您好,欢迎访问三七文档
当前位置:首页 > 行业资料 > 冶金工业 > 第6章径向基函数网络
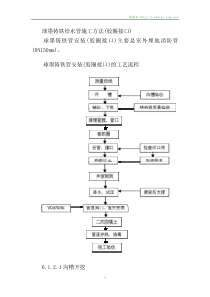
人工神经网络及应用主讲何东健第六章径向基函数网络6.1径向基函数用函数来描述一个实际对象,需要一个函数空间。最熟悉的是多项式函数空间,一个简单函数x和他自身的乘积xn做线性组合得到。如:f(x)=ax+bx2+cx3+dx4三角多项式函数空间,也是eix和他自身的乘积einx做线性组合得到。高维的数值分析问题,选择何种函数空间和基底?希望能有一个简单的函数φ(.)经过一些简单的运算就能得到函数空间的基。国际上处理多元函数问题的基:(1)楔型基函数(2)径向基函数RBF(Radialbasisfunction){φ(||x-c||)}径向基函数指某种沿径向对称的标量函数,通常定义为空间中任一点X到某一中心ci之间欧氏距离的单调函数。设有P个输入样本Xp,在输出空间相应目标为dp。需要找到一个非线性映射函数F(x),使得:F(Xp)=dp选择P个基函数,每个基函数对应一个训练数据,各基函数的形式为:φ(||X-Xp||),p=1,2,......,PXp是函数的中心。φ以输入空间的点X与中心Xp的距离为自变量。故称为径向基函数。定义F(X)为基函数的线性组合PpppXXwX1||)(||)(F令φip=φ(||X-Xp||)。上述方程组可改写为pPppppPppPppdXXwdXXwdXXw121221111||)(||||)(||||)(||pdddwpwwpppppp2121212222111211用Φ表示φip的P×P矩阵;ΦW=d若Φ可逆,可解出W=Φ-1d最常用的径向基函数是高斯核函数,形式为其中ci为核函数中心,σi为核函数的宽度参数,控制基函数的径向作用范围,即方差(扩展常数)。例用径向基函数映射一个函数p=-3:.1:3;a=radbas(p);plot(p,a)a2=radbas(p-1.5);a3=radbas(p+2);a4=a+a2*1+a3*0.5;plot(p,a,'b-',p,a2,'b--',p,a3,'b--',p,a4,'m-')aa2a3a46.2径向基函数网络(RBF)是在借鉴生物局部调节和交叠接受区域知识的基础上提出的一种采用局部接受域来执行函数映射的人工神经网络,具有最优逼近和全局逼近的特性。网络的学习等价于在多维空间中寻找训练数据的最佳拟合平面,隐层的每一个神经元的传递函数都构成拟合平面的一个基函数,故称为径向基函数网络。RBF网络是一种局部逼近网络,对输入空间的某一个局部区域,只存在少数神经元用于决定网络的输出。网络由一个隐含层和一个线性输出层组成。隐含层最常用的是高斯径向基函数,而输出层采用线性激活函数。RBF网络的权值训练是一层一层进行的,对径向基层的权值训练采用无导师训练,在输出层的权值设计采用误差纠正算法,为有导师训练。与BP网络相比,RBF必BP网络规模大,但学习速度快,函数逼近、模式识别和分类能力都优于BP网络。RBF神经元模型R维输入的神经元模型如图。||dist||模块表示求取输入矢量和权值矢量的距离。传递函数为高斯函数(radbas),函数的输入n为p和w的距离乘以阈值b。高斯函数表达式为:中心和宽度是径向基函数的两个重要参数。神经元的权值矢量w确定基函数的中心,当输入p和w重合时,径向基函数神经元输出达到最大值,p与w的距离越远,输出越小。神经元的阈值b决定了径向基函数的宽度。a=radbas(dist(W,P).*b)RBF网络结构在RBF中,输入层到隐含层的基函数输出是一种非线性映射,而输出则是线性的。这样,RBF网络可以看成是首先将原始的非线性可分的特征空间,变换到另一线性可分的空间(通常是高维空间),通过合理选择这一变换使在新空间中原问题线性可分,然后用一个线性单元来解决问题,从而很容易的达到从非线性输入空间向输出空间映射的目的。注意:由于RBF网络的权值算法是单层进行的,它的工作原理采用的是聚类功能,由训练得到输入数据的聚类中心,通过σ值来调节基函数的宽度。虽然网络结构看上去是全连结的,实际网络是局部工作的,即对输入的一组数据,网络只有一个神经元被激活,其他神经元被激活的程度可忽略。所以RBF网络是一个局部逼近网络,训练速度比BP网络快2~3个数量级。6.3RBF网络学习方法RBF网络有3组可调参数:隐含层基函数中心、方差和隐含层单元到输出单元的权值。这些参数的确定主要有两种形式:一种是根据经验或聚类方法选择中心及方差,当选定中心和方差后,由于输出是线性单元,它的权值可以用迭代的最小二乘法直接计算出来。另一种是通过训练样本用误差纠正算法进行监督学习,逐步修正以上3个参数,即计算总的输出误差对各参数的梯度,再用梯度下降法修正待学习的参数。一种采用模糊K均值聚类算法确定各基函数的中心及相应的方差,用局部梯度下降法修正网络权值的算法如下:1、利用模糊K均值聚类算法确定ci①随机选择h个样本值作为ci(i=1,2,…,h)的初值,其他样本按该样本与中心ci的欧氏距离远近归入某一类,从而形成h个子类ai,i=1,2,…,h;②重新计算各子类中心ci的值,其中xk∈ai,si为子集ai的样本数;同时计算每个样本属于每个中心的隶属度③确定ci是否在容许的误差范围内,若是则结束,不是则根据样本的隶属度调整子类个数,转到②继续。2、确定基函数宽度(方差σ)其中,ai是以ci为中心的样本子集。基函数中心和宽度参数确定后,隐含层执行的是一种固定不变的非线性变换,第i个隐节点输出定义为3、调节隐层单元到输出单元间的连接权网络的目标函数为也就是总的平均误差函数。其中,yˆ(xk)是相对于输入xk的实际输出,y(xk)是相对于输入xk的期望输出,N为训练样本集中的总样本数。对于RBF神经网络,参数的确定应能使网络在最小二乘意义下逼近所对应的映射关系,也就是使E达到最小;因此,这里利用梯度下降法修正网络隐含层到输出层的权值ω,使目标函数达到最小。根据上面两式最终可以确定权值ω的每步调整量(其中,η为学习率,取值为0到1间的小数)。权值ω的修正公式为最后整个网络的输出定义为:其中,θ为输出层节点的阈值。整个RBF网络分类器的学习算法:1)初始化:对权值ω(0)赋0到1之间的随机数,隐层神经元数m,初始误差E置0,最大误差ε设为一正的小数,学习率η为0到1之间的小数。2)采用模糊K均值聚类算法确定基函数的中心ci(0)及方差σi(0),i=1,2,…,m。3)按上述梯度下降法调整网络权值ω(0)直到误差Eε,结束。6.4RBF网络MATLAB设计1、RBF的精确设计newrbe用来精确设计RBF网络。精确是指该函数生产的网络对于训练样本数据达到了0误差。net=newrbe(P,T,SPREAD)P,T-输入矢量、目标矢量。SPREAD-扩展常数,缺省为1.相当于σ。隐层神经元个数与P中输入矢量个数相等(正规化网络),隐层神经元阈值取0.8632/SPREAD。显然,当输入矢量个数过多时,生产的网络过于庞大,实时性变差。实际更有效的设计是用newrb()函数。如:P=[123];T=[2.04.15.9];net=newrbe(P,T);P=1.5;Y=sim(net,P)2、RBF的有效设计newrb()用迭代方法设计RBF网络。每迭代一次就增加一个神经元,直到平方和误差下降到目标误差以下或神经元个数达到最大值时停止。调用形式:net=newrb(P,T,GOAL,SPREAD,MN,DF)GOAL-目标误差。NM-最大神经元个数;DF-迭代过程显示频率。例6.1径向基函数进行线性组合例6.2利用RBF实现函数逼近例6.3利用RBF实现函数逼近,但扩展常数太小(过拟合)例6.4利用RBF实现函数逼近,但扩展常数太大(不能完全拟合)6.5广义RBF网络(GRNN)1、Cover定理:将复杂的模式分类问题非线性地投射到高维空间,将比投射到低维空间更可能是线性可分的。在RBF网络中,将输入空间的模式点非线性地映射到一个高维空间的方法是,设置一个隐层,令φ(X)是隐节点的激活函数,并令隐节点个数M大于输入节点个数N,形成一个高维(隐)空间。若M足够大,则在隐空间输入是线性可分的。2、广义RBF网络正规化RBF网络的隐节点个数和输入样本数相等,但样本很大时,网络庞大,计算量惊人。解决思路:减少隐节点个数。使NMPN为样本维数、P为样本个数。从而得到广义RBF网络。广义RBF网络的基本思想:用径向基函数做为隐单元的“基”,构成隐含层空间。隐含层对输入向量进行变换,将低维空间的模式变换到高维空间内,使得低维空间内的线性不可分问题在高维空间内线性可分。GRNN特点:1、M不等于N,常远远小于N;2、径向基函数的中心不再限制在数据点上,由训练算法确定;3、扩展常数不再统一,由训练算法确定;4、输出函数的线性中包括阈值参数,以补偿样本平均值与目标平均值间的差别。5、GRNN多用于函数逼近问题。NEWGRNN(P,T,SPREAD)建立一个2层网络。第一层具有RADBAS神经元,||DIST||为求输入矢量和权值矢量的距离;输出层为特殊线性层,输入为规格化内积。nprod为计算隐层输出矢量a1和输出权矩阵W的规格化内积(W2a1/sum(a1))例6.5GRNN函数逼近(rbf5grnn.m)隐层、输出层神经元个数,等于输入样本个数Q规格化内积n2=LW21a1/sum(a1)6.6概率神经网络(PNN)特点:1、网络隐层神经元个数(Q)等于输入矢量样本个数;输出层神经元个数等于训练样本数据的种类个数(K);2、输出层是竞争层,每个神经元对应1类。模块C表示竞争传递函数,功能是找输入矢量中个元素的最大值max(WX),并使最大值对应类别的神经元输出为1,其余输出为0.这种网络得到的分类结果能达到最大的正确概率。用于解决分类问题。当样本足够多时,收敛于一个贝叶斯分类器。概率神经网络设计net=newpnn(P,T,SPREAD)SPREAD-缺省为0.1。例6.6PNN用于分类(rbfpnn.m)例6.7PNN用于分类(rbfpnn2.m)
 三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 扫描二维码
扫描二维码








 akibarika333
akibarika333
本文标题:第6章径向基函数网络
链接地址:https://www.777doc.com/doc-1370063 .html