您好,欢迎访问三七文档
当前位置:首页 > 办公文档 > 招标投标 > 网络异常检测的无监督聚类方法
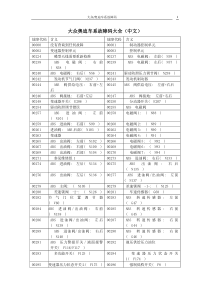
Unsupervisedclusteringapproachfornetworkanomalydetection——文献阅读笔记论文:网络异常检测的无监督聚类方法本文描述了无监督聚类方法在检测未知的网络入侵或攻击方面的应用。给出了五种聚类算法和它们在实际情况中的具体表现。五种聚类算法分别是:k-Means算法,改进的k-Means算法,k-Medoids算法,EM聚类法和基于距离的孤立点检测法。1k-Meansk-Means是机器学习中最简单的一种聚类算法,算法需要事先定好类别的个数K,第一步是选择K个实例集合作为聚合质心,通常每个集合选择一个实例即可,尽可能远的能使每个类别分开。具体算法如下:1.Selectthetotalnumberofclusters(k)选择聚合类别的个数K2.Chooserandomkpointsandsetascentroid随机选择K个点和集合作为聚心3.CalculatethedistancefromeachinstancetoallcentroidsusingEuclideanmethod使用欧几里德方法计算每个实例到聚心的距离4.Assigneachinstancetotheclosestcentroid将每个实例分配到距离最近的聚心的集合5.Recalculatethepositionsofthecentroids重新计算各个聚心的位置6.Repeatstep3-5untilthecentroidsdonotchange重复3-5步,直到聚心不再改变2k-Medoidsk-Medoids算法和k-Means类似,但是本算法能将实例到聚心的距离最小化.一个medoid定义为用来代表一个类集的模板数据点。k-Means算法对噪声和离群值比较健壮。具体算法如下:1.InputadatasetDconsistsofnobjects输入有个n对象的数据集D2.InputthenumberofclustersK输入聚合类别的个数K3.Selectkobjectsrandomlyastheinitialclustercentresorclustermedoids随机选择K个对象作为初始化聚心或medoid4.Assigneachobjecttotheclusterwiththenearestmedoid将每个对象分配到距离最近的medoid的集合5.Calculatethetotaldistancebetweentheobjectanditsclustermedoid计算对象到它的medoid的总距离6.Swapthemedoidwithnon-medoidobject交换medoid和非medoid7.Recalculatethepositionsofthekmedoids重新计算K个medoids的位置8.Repeat4-7untilthemedoidsbecomefixed重复4-7步,直到medoids不再改变3EMClusteringExpectationMaximization(EM)clustering最大期望聚类法是变种的k-Means算法,广泛使用在非监督聚类的数据点密度估计上。EM计算使数据的似然值最大的参数,假定数据由K个正态分布生成.,算法同时得到正态分布的方法和协方差。算法需要输入数据集、聚合的类别个数、最大误差公差、最大迭代次数。EM可分为两个重要过程E过程(E-step)和M过程(M-step).1)E-step目的是计算每个实例的似然值的期望,然后用它们的概率估计重新标记每个实例。2)M-step的目的是重新估计参数值,输出参数值作为下一个E-step的输入。3)两个过程反复迭代计算,直到结果收敛。4OutlierDetectionAlgorithms孤立点检测(Outlierdetection)是为了找到数据中不合预期的行为的数据模式。大多数的聚类算法虽然不是为所有的点分配类别,但在在计算中其实都把噪声对象考虑了进去。Outlierdetection算法首先实现一个聚类算法然后检索噪声集。因此算法的效果取决于聚类算法的好坏。算法有两种实现方式:基于距离的孤立点检测和基于密度的孤立点检测。基于距离的孤立点检测,假设正常的数据对象有一个密集的分布区,孤立点距离那些区域很远。论文只给出了基于距离的孤立点检测算法。通过nestedloop(NL)算法来计算每一对儿对象的距离,而那些远离大多数对象的则被标记为孤立点。基于密度的孤立点检测,假设正常的数据对象的密度与其相邻分布区密度相似,孤立点则大相径庭。算法通过计算孤立值来比较这种密度差异。5ExperimentalSetup实验过程5.1IntrusionDataset入侵数据集试验使用的是NSL-KDD入侵数据。训练和测试数据都出现的入侵数据:back,buffer_overflow,ftp_write,guess_passwd,imap,ipsweep,land,loadmodule,multihop,neptune,nmap,phf,pod,portsweep,rootkit,satan,smurf,spy,teardrop,warezclient,warezmaster。只在测试数据中出现的入侵数据:apache2,httptunnel,mailbomb,mscan,named,perl,processtable,ps,saint,sendmail,snmpgetattack,snmpguess,sqlattack,udpstorm,worm,xlock,xsnoop,xterm。训练数据集包含有25191个实例,测试数据集包含有11950个实例。四十种不同入侵分为四类:DoS(DenialofService),R2L(RemotetoLocalAttack),U2R(UsertoRootAttack)andProbingAttack。5.2PerformanceMetric评价指标我们使用准确率和误报率作为评价指标:ActualResult真实值IntrusionNormalPredictedResult预测值IntrusionTruePositive(TP)FalsePositive(FP)NormalFalseNegative(FN)TrueNegative(TN)用如下公式计算准确率和错误率:5.3MisuseDetectionModule错误检测模块错误检测模块包括五个阶段:1)特征提取featureextraction2)降维dimensionalityreduction3)分类算法classificationalgorithms4)模型应用applymodel5)性能测试和分析performancemeasurement&analysis。5.4AnomalyDetectionModule异常检测模块给定一个训练数据集,平均和标准偏差特征向量计算方法如下:然后训练集中每个实例(特征向量)做如下转换:6ExperimentalResultsandDiscussion实验结果及分析6.1MisuseDetectionModule错误检测模块在第一个实验中,我们只使用训练数据包含大约22个不同的类型的已知入侵。结果见表所示:表中可见四个算法中有三个实现了高于99%的准确率和低于1%的误报率。效果显著。在第二个实验中,我们使用一个错误检测模块的测试数据集评价的入侵检测模块的性能。测试数据含有22种已知的入侵和18种未知的入侵。结果见表所示:表中可见由于有大量的未知入侵数据,错误检测模块效果不是很好。最准确率仅为63.97%,最低的误报率是17.90%。6.2AnomalyDetectionModule异常检测模块我们实现了五种非监督聚类算法,分别是:k-Means算法,改进的k-Means算法,k-Medoids算法,EM聚类法和基于距离的孤立点检测法。使用一个未标记的数据集作为输入。结果见下表:与上一个错误检测模块相比,异常检测模块在检测新异常的表现上显然更好一些。这些聚类算法能够在没有先验知识的情况下检测入侵。实验中outlierdetection算法达到了最好的准确率80.15%,第二好的是EMclustering算法78.06%,k-Medoids达到76.71%,改进的k-Means达到65.40%,k-Means达到57.81%。遗憾的是误报率也都超过20%。因此,我们未来的工作将集中在如何减少误报同时还提高准确率。各个算法的执行时间如下图:把入侵数据集分类为四个类型的入侵后,再用outlierdetection算法检测结果如下:7Conclusions总结实验表明,错误检测技术在检测已知入侵方面能达到很好的性能,达到了高于99%准确率。但是当有大量未知数据时准确率仅仅63.97%。相反,异常检测技术的集中算法在未知数据上准确率都表现得良好,outlierdetection算法达到了最好的准确率80.15%,进一步的实验表明把入侵数据集分类后,再用outlierdetection算法检测的效果更加好。因此,我们未来的工作将集中在寻找更先进的机器学习技术,来减少误报同时还提高准确率。
 三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 扫描二维码
扫描二维码








 mfkyga110
mfkyga110
本文标题:网络异常检测的无监督聚类方法
链接地址:https://www.777doc.com/doc-1427349 .html