您好,欢迎访问三七文档
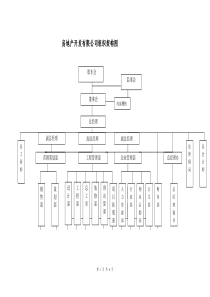
本章主要内容•抽样调查的一般问题•抽样误差•抽样估计的方法•抽样组织设计第七章抽样调查第一节抽样调查概述一、抽样调查的概念:是一种非全面调查,就是按随机原则从全部研究对象中抽取部分单位进行观察,并根据这一部分单位的实际数据推断总体的数量特征,作出具有一定可靠程度的估计和判断。它是由部分推断整体的一种认识方法。建立在随机取样的基础上。运用概率估计的方法。其误差可以事先计算并加以控制。二、特点三、有关的基本概念(一)总体和样本总体:又称全及总体。指所要认识的研究对象全体。总体单位总数用“N”表示。样本:又称子样。是从全及总体中随机抽取出来,作为代表这一总体的那部分单位组成的集合体。样本单位总数用“n”表示。(二)全及指标和样本指标全及指标:反映总体数量特征的指标数值。全及指标研究总体中的数量标志总体平均数总体方差X=∑XNX=∑XF∑FΣ(X-X)N2σ=2Σ(X-X)FΣF2σ=2研究总体中的品质标志成数方差σ2=P(1-P)P=N1N(只有两种表现)总体成数样本指标:根据样本数据计算的综合指标。研究数量标志样本平均数x=∑xnx=∑xf∑f样本标准差研究品质标志样本成数成数标准差n=nnxxS2ffxxS2ppp1样本指标p什么是成数?将总体所包含的总体单位按某一标志划分为两大部分,具有某种特征的单位数占全部单位数的比重,就是成数。成数也是这个总体的平均数。产品质量合格品不合格品数量(件)合计N1N0N平均数x10ffxfxPNNNNNN1010101(成数)(三)样本容量和样本个数样本容量:一个样本包含的单位数。用“n”表示。一般要求n≥30样本个数:从一个全及总体中可能抽取的样本数目。(四)重复抽样和不重复抽样重复抽样:又称置回抽样。不重复抽样:又称不置回抽样。例如:从A、B、C、D四个单位中,抽出两个单位构成一个样本重复抽样AAACADBABBBCBDABCACBCCCDDADBDCDD不重复抽样12个样本16个样本第三节抽样误差一、抽样误差的含义由于随机抽样的偶然因素使样本各单位的结构不足以代表总体各单位的结构,而引起抽样指标和全及指标之间的绝对离差。抽样误差不包括下面两类误差:一类是调查误差,即在调查过程中由于观察、测量、登记、计算上的差错而引起的误差;另一类是系统性误差,即由于违反抽样调查的随机原则,有意抽选较好单位或较坏单位进行调查,这样造成样本的代表性不足所引起的误差。二、影响抽样误差大小的因素1、总体各单位标志值的差异程度2、样本的单位数3、抽样方法4、抽样调查的组织形式三、抽样平均误差抽样平均误差是抽样平均数或抽样成数的标准差,反映了抽样指标与总体指标的平均误差程度。假设总体包含1、2、3、4、5,五个数字。则:总体平均数为x=1+2+3+4+55=3现在,采用重复抽样从中抽出两个,组成一个样本。可能组成的样本数目:25个。如:……..1+32=21+42=2.52+42=33+52=4抽样平均误差的计算理论公式抽样平均数的平均误差抽样成数平均误差(以上两个公式实际上就是第四章讲的标准差。但反映的是样本指标与总体指标的平均离差程度)MXxx2MPpp2实际上,利用上述两个公式是计算不出抽样平均误差的。想一想,为什么?多数样本指标与总体指标都有误差,误差有大、有小,有正、有负,抽样平均误差就是将所有的误差综合起来,再求其平均数,所以抽样平均误差是反映抽样误差一般水平的指标。抽样平均数平均误差的实际计算方法采用重复抽样:此公式说明,抽样平均误差与总体标准差成正比,与样本容量成反比。(当总体标准差未知时,可用样本标准差代替)(教材P279例题)通过例题可说明以下几点:①样本平均数的平均数等于总体平均数。②抽样平均数的标准差仅为总体标准差的③可通过调整样本单位数来控制抽样平均误差。nxn1例题:假定抽样单位数增加2倍、0.5倍时,抽样平均误差怎样变化?解:抽样单位数增加2倍,即为原来的3倍则:抽样单位数增加0.5倍,即为原来的1.5倍则:577.0313nx8165.05.115.1nx即:当样本单位数增加2倍时,抽样平均误差为原来的0.577倍。即:当样本单位数增加0.5倍时,抽样平均误差为原来的0.8165倍。采用不重复抽样:公式表明:抽样平均误差不仅与总体变异程度、样本容量有关,而且与总体单位数的多少有关。Nnnx12与重复抽样相比,不重复抽样平均误差是在重复抽样平均误差的基础上,再乘以,而总是小于1,所以不重复抽样的平均误差也总是小于重复抽样的平均误差。)-()-(1/NnN)-()-(1/NnN例题一:例题二:某厂生产一种新型灯泡共2000只,随机抽出400只作耐用时间试验,测试结果平均使用寿命为4800小时,样本标准差为300小时,求抽样推断的平均误差?随机抽选某校学生100人,调查他们的体重。得到他们的平均体重为58公斤,标准差为10公斤。问抽样推断的平均误差是多少?例题一解:)(110010公斤nx即:当根据样本学生的平均体重估计全部学生的平均体重时,抽样平均误差为1公斤。例题二解:)(15400300小时nxNnnx12)(42.13200040014003002小时计算结果表明:根据部分产品推断全部产品的平均使用寿命时,采用不重复抽样比重复抽样的平均误差要小。已知:则:已知:则:n=100σ=10x=58N=2000n=400σ=300x=4800•习题:有5个工人的日产量分别为(单位:件):6,8,10,12,14,用重复抽样的方法,从中随机抽取2个工人的日产量,用以代表这5个工人的总体水平。则抽样平均误差为多少?若改用不重复抽样方法,则抽样平均误差为多少?•解:根据题意可得:(件))(85402NXX(件)10514121086X(件)抽样平均误差228nx不重复抽样条件下抽样平均误差(件)=)--(=)(=732.115252812NnNnx重复抽样条件下抽样成数平均误差的实际计算方法采用重复抽样:采用不重复抽样:例题三:某校随机抽选400名学生,发现戴眼镜的学生有80人。根据样本资料推断全部学生中戴眼镜的学生所占比重时,抽样误差为多大?例题四:一批食品罐头共60000桶,随机抽查300桶,发现有6桶不合格,求合格品率的抽样平均误差?nppp1Nnnppp11例题三解:已知:400n801n则:样本成数%20400801nnp02.04008.02.01nppp即:根据样本资料推断全部学生中戴眼镜的学生所占的比重时,推断的平均误差为2%。例题四解:已知:60000N300n61n则:样本合格率98.030063001nnnp(%)808.030002.098.01npppNnnppp11(%)806.060000300130002.098.0计算结果表明:不重复抽样的平均误差小于重复抽样,但是“N”的数值越大,则两种方法计算的抽样平均误差就越接近。抽样极限误差是指样本和总体指标之间误差的可能范围。由于总体指标是一个确定的数,而样本指标则是围绕总体指标上下波动的,它与总体指标之间既有正离差,也有负离差,样本指标变动的上限或下限与总体指标之差的绝对值就可以表示抽样误差的可能范围,我们将这种以绝对值形式表示的抽样误差可能范围称为抽样极限误差。四、抽样极限误差含义:抽样极限误差指在进行抽样估计时,根据研究对象的变异程度和分析任务的要求所确定的样本指标与总体指标之间可允许的最大误差范围。计算方法:设Δx与Δp分别表示样本平均数与样本成数的抽样极限误差,则有:|x-X|≤Δx,|p-P|≤Δp上述不等式也可表示成:抽样平均数极限误差:抽样成数极限误差:x-Δx≤X≤x+Δxp-Δp≤P≤p+Δp五、抽样误差的可信度(概率度)含义抽样误差的概率度是测量抽样估计可靠程度的一个参数。用符号“t”表示。公式表示:t=ΔμΔ=tμ(t是极限误差与抽样平均误差的比值)(极限误差是t倍的抽样平均误差)上式可变形为:参看P284-286例题第四节抽样组织设计一、简单纯随机抽样1、含义:按随机原则直接从总体N个单位中抽取n个单位作为样本。2、样本单位数的计算方法:通过抽样极限误差公式计算必要的样本单位数。重复抽样:不重复抽样:抽样平均数抽样成数22222xxxtNNtnpptNpNptnp11222222xxtn221ppptn二、类型抽样三、等距抽样四、整群抽样先对总体各单位按主要标志加以分组,然后再从各组中按随机的原则抽选一定单位构成样本。先按某一标志对总体各单位进行排队,然后依一定顺序和间隔来抽取样本单位的一种组织形式。将总体各单位划分成许多群,然后从其中随机抽取部分群,对中选群的所有单位进行全面调查的抽样组织形式。第五节抽样单位数目的确定样本单位数的计算方法:通过抽样极限误差公式计算必要的样本单位数。重复抽样:不重复抽样:抽样平均数抽样成数22222xxxtNNtnpptNpNptnp11222222xxtn221ppptn第五节抽样单位数目的确定教材P302-306第六节全集总体指标的推断一、总体的点估计点估计的特点:P307总体参数优良估计的标准无偏性一致性有效性二、总体的区间估计区间估计三要素估计值抽样误差范围抽样估计的置信度区间估计的方法步骤:P307px,px,tFpx,教材P271什么是抽样估计的置信度?抽样估计的置信度就是表明抽样指标和总体指标的误差不超过一定范围的概率保证程度(教材P284)符号表示:P(x-X≤Δ)=F(t)x(教材P286例题)理论已经证明,在大样本的情况下,抽样平均数的分布接近于正态分布,分布特点是:抽样平均数以总体平均数为中心,两边完全对称分布,即抽样平均数的正误差与负误差的可能性是完全相等的。且抽样平均数愈接近总体平均数,出现的可能性愈大,概率愈大;反之,抽样平均数愈离开总体平均数,出现的可能性愈小,概率愈小,趋于0。(见下图)正态概率分布图Xx+1μx-1μ68.27%x+2μx-2μ95.45%由此可知,误差范围愈大,抽样估计的置信度愈高,但抽样估计的精确度愈低;反之,误差范围愈小,则抽样估计的置信度愈低,但抽样估计的精确度愈高。因为扩大或缩小以后的平均误差,就是极限误差:Δ=tμ所以,抽样平均误差的系数就是概率度t。数理统计已经证明,抽样误差的概率就是概率度的函数,二者对应的函数关系已编成“正态分布概率表”。(一)根据给定的概率F(t),推算抽样极限误差的可能范围分析步骤:1、抽取样本,计算样本指标。2、根据给定的F(t)查表求得概率度t。3、根据概率度和抽样平均误差计算极限误差。4、计算被估计值的上、下限,对总体参数作出区间估计。三、总体参数区间估计的方法某农场进行小麦产量抽样调查,小麦播种总面积为1万亩,采用不重复简单随机抽样,从中抽选了100亩作为样本进行实割实测,测得样本平均亩产400斤,方差144斤。(1)以95.45%的可靠性推断该农场小麦平均亩产可能在多少斤之间?例题一:9545.0,144,400,100,100002tFxnNt=2样本指标,有时需要计算例题一解题过程:已知:问题一解:1、计算抽样平均误差斤19.110000100110014412Nnnx2、计算抽样极限误差斤38.219.12xxt3、计算总体平均数的置信区间上限:斤38.40238.2400xx下限:斤62.39738.2400xx即:以95.45%的可靠性估计该农场小麦平均亩产量在397.62斤至402.
 三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 扫描二维码
扫描二维码







 cdcabm
cdcabm
本文标题:第七章 抽样调查
链接地址:https://www.777doc.com/doc-419647 .html