您好,欢迎访问三七文档
当前位置:首页 > 商业/管理/HR > 质量控制/管理 > 限定领域汉语口语对话语料分析AnalysisofSpo
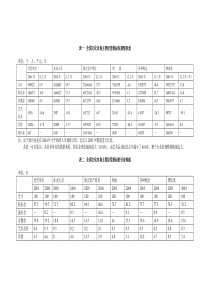
115限定领域汉语口语对话语料分析*宗成庆吴华黄泰翼徐波中科院自动化研究所模式识别国家重点实验室北京100080摘要口语对话语料分析是口语交互翻译系统和人机对话系统研究的基础。本文以限定领域汉语口语对话语料为基础,首次对汉语口语对话中的语言现象进行了详细统计和分析,提出了建立通用口语词典和适应不同应用领域转移性的词汇提取方法。本文提出的方法和统计的结果对于研究鲁棒性汉语口语理解算法和建立限定领域的口语翻译系统和人机对话系统,具有重要的意义。关键词话语分析语料统计口语翻译人机对话AnalysisofSpokenDialogCorpusinRestrictedDomainChengqingZONG,HuaWU,TaiyiHUANGandBoXUcqzong@nlpr.ia.ac.cnNationalLaboratoryofPatternRecognition,InstituteofAutomation,CAS.Beijing100080AbstractAnalysisofspokendialogcorpusisanimportantfoundationforresearchofspeech-to-speechtranslationsystemandman-machinedialogsystem.BasedontheChinesespokendialogcorpusinrestricteddomain,thispaperfirstlypresentsstatisticaldataandperformsanalysisindetailonthespokenlanguagephenomena.Theideastoestablishuniversalspokenlanguagedictionaryandthemethodstoextractwordsfromcorpusofdifferentdomainsforexpandingdictionaryarealsopresented.ThemethodsandstatisticalresultspresentedinthepaperaremeaningfulforresearchofrobustChinesespokenlanguageunderstandingandimplementationofspokenlanguagetranslationsystemandman-machinedialogsystem.KeywordsDiscourseanalysis,Corpusstatistics,Spokenlanguagetranslation,Man-machinedialogsystem1.引言在口语翻译和人机对话系统研究中,口语语料的收集、整理和分析是非常重要的基础性工作。由于口语对话中的语言现象与书面语相比具有较大的差异,而且不同的应用领域*本项目得到国家自然科学基金项目(批准号:69835030)、国家“863”项目(批准号:863-306-ZT03-02-2)、中国博士后科学基金和中国科学院王宽诚博士后基金资助。116之间,词汇的分布等各种语言现象也有所不同,因此,如何建立有效的语料分析方法,对特定领域的口语现象进行准确地统计和分析,对于口语理解方法的研究和建立限定领域的口语翻译系统和人机对话系统,具有重要的意义。近几年来,随着口语翻译系统和人机对话系统的研究日渐兴起,口语语料的分析受到越来越多的重视,尤其在国外,话语分析(DiscourseAnalysis)已经成为自然语言处理研究中的一个比较活跃的分支[1~3]。而在我国,除了语言学家对汉语口语进行过一些定性的分析[4]以外,在自然语言处理领域中对口语现象的研究还只是十分初步的。本文以旅馆预订领域收集到的对话语料为基础,对汉语口语中的语言现象进行了详细的统计和分析,提出了建立通用口语词典和适应不同应用领域转移性的词汇提取方法。本文统计的结果和提出的方法,对于研究鲁棒性汉语口语理解算法和建立限定领域的人机对话系统及口语翻译系统,具有较大的参考价值。2.语料收集及统计结果本文的研究工作以旅馆预订领域的对话语料为基础。对话过程是两个人通过电话以一问一答的形式进行的,电话一端代表客户,另一端是旅馆前台服务人员,说话方式完全是自由的和随意的。为了表述方便,我们首先给出如下定义:定义1对话语句(Utterance)从对话者一方开始讲话到讲完停下或被对方强行打断为止,所说的全部内容称作一个对话语句。定义2对话子句(Dialogsentence)一个对话语句中所包含的分句,称作对话子句。例如:我打电话到订票处了/他说票特别紧张/他说去试一试/这样吧我明天一早给您挂电话行吗这一段文字从开始到结束是一个对话语句,在这个对话语句中包含有4个对话子句(由“/”隔开)。2.1语料的整理与标注方法口语对话语料的收集与书面语语料的收集方法不同,它首先需要通过录音的方式将对话内容记录下来,然后再将其整理成文字,因此,往往需要大量的手工操作。首先用录音电话将对话内容记录在磁带上,然后由人根据磁带记录的信息将对话整理成文字。整个处理过程可以简单地表示为如下流程图:语料标注人与人的录音整理文字表示分词标注标注后自由对话磁带存放的对话内容提取词汇词典词典标注后语料图1语料整理流程其中,词典标注采用人工方式,语料标注采用机器自动标注与人工核对相结合的方法。当第一次收集语料时,词典是不存在的,我们只需要对整理的语料进行分词,然后提取所有的词汇,并依据这些词汇建立相应的词典。词典一旦建立之后,当领域转移或扩展时,系统只需将新收集的语料中在词典中没有的所有新词提取出来,然后在人的辅助下决定是否将这些新词添加到词典中去。这样,对于应用领域接近或同一领域扩展时,只需要处理少数新的词汇即可,而避免了大量的重复工作。2.2词类划分与词典标注面向口语翻译系统,我们将建立一个通用的汉语口语词典。词典中尽量收集口语中使用较多的一些口语词汇和相对稳定的一些常用的虚词。每一个词条信息包括汉语词条的词类、语义特征信息和对应的英语单词等。考虑到口语中若干词的使用方法和含义与其在书面语中的作用和含义有所差异,因此,在考虑一般的汉语词类划分方法的同时,我们还专门针对口语中的词汇进行了调整,将全部词汇划分为18个大类:名词N、代词P、时间词T、处所词W、动词V、助动词X、判断动词J、形容词A、数词Q、副词D、方位词F、介词R、连词C、助词H、量词L、语气词M、拟声词Y、习惯用语I。其中,习惯用语较多地考虑了日常口语对话中的用词习惯,它包括敬语、插入语、感叹词和呼应语以及搪塞性的词语。呼应性的词是指对话双方在交互过程中应答性的口头用语,如:“嗯,好的,哦,没错儿,够戗,”等;敬语主要包括日常对话中的一些寒暄性用语,如:“多谢,不敢当,久仰”等;搪塞性的词语是指当说话者处于思考状态或语塞状态时使用的一些,如“那个、这个、这”等。词义特征标记根据不同的词类采用不同深度的树状层次化结构的标记方法,由上位到下位逐步细化,层次最多的是名词,语义特征树的高度最高达8层。1171182.3语料统计结果根据上述介绍,我们对收集到的100多段涉及旅馆预订的对话语料进行了全面统计。以下给出部分统计结果:(1)词长分布口语中的词长分布如下表所示:表1词长分布词长(字)1234比例(%)28.5157.2012.991.31统计结果显示,在口语对话中,1字词和2字词占绝大多数(86.19%),3字词和4字词只占少数,4字以上词基本上极少出现。口语的平均词长为1.87个汉字,比书面语的平均词长(约2.45汉字)短[5]。(2)对话语句长度分布对话语句长度的分布情况如下:表2语句长度分布长度(字)1234567891011~67比例(%)15.128.349.288.547.686.785.275.274.784.0924.85在我们收集到的语料中,最长的对话语句为67个汉字,占全部语句的0.08%,其次长度是61个汉字,占0.041%。长度为1的语句数最多,这些语句一般是单字长的语气词或呼应性的单字词,如:啊,噢,嗯等,平均语句长度为7.8个汉字。(3)词类分布统计根据我们对口语词类的划分标准和对口语词的处理方法,对收集的语料进行统计后得到如下词类的分布结果:表3词类分布统计结果词类ACDFHIJLM比例(%)4.001.526.840.523.9810.772.632.875.37词类NPQRTVWXY比例(%)14.6910.8815.610.663.1015.310.471.630.00从统计结果我们可以看出,口语中使用最多的5种词类依次是:数词、动词、名词、代词和习惯用语。在统计语料中数词之所以如此之多,主要是因为在旅馆预订时经常需要交换电话号码、询问费用和房间号码、楼层号等原因所致。119(4)非规范语言现象的统计我们专门对口语中经常出现的重复、次序颠倒、冗余和语句残缺(严重省略)等4种非规范语言现象的出现几率进行了统计。以下首先说明4种非规范语言现象的界定:1)重复这里所说的重复主要指字面上明显的重复现象。如下面的例句:(a)啊打九折行下礼拜下礼拜二三吧好吗(b)不不现在先不订过两天再订2)次序颠倒次序颠倒主要指语序上明显的不合理现象。如下列例句:(c)已经给您打过折扣了这个(d)有房吗现在3)冗余冗余现象主要指语句中含有多余的词语。如下面的例句:(e)那个可以预订吗可以(f)就里面的那些设施啊怎么样就是条件我想大概就是说看一下4)省略或语句残缺省略现象主要指说话人根据对话主题和上下文语境,有意省略双方正在讨论的问题所对应的词汇,或者说话者出现语塞,或被对方强行打断等现象引起的对话语句残缺。如下面的语句:(g)那六楼呢(h)差别在哪里二百三百另外还有一类语句我们把它们称之为独词句或零句,这类语句一般只有一个词或同一个词连续重复,多数是说话一方呼应对方或彼此使用的敬语,如:“对、对、对”,“不客气”,“没问题”等。独词句和省略句只按一种情况记。以下是对上述4种非规范语言现象和独词句出现几率的统计情况:表4非规范语言现象出现几率语言现象重复次序颠倒冗余省略独词句现象并存出现几率(%)3.561.234.7032.6144.595.68其中,“现象并存”是指重复、次序颠倒、冗余和省略(或独词句)至少两种语言现象同时存在的情况。另外,口语中常常因为说话人边思考,边重复对方讲话内容,同时还伴随介绍正在进行的动作,从而导致说出来的语句支离破碎。如:120(i)住到我看看啊住两天两晚上(j)单人间告诉我客人的名字系统要对类似的句子正确地理解,必须能够识别并分隔这些语句中的插入片段或子句。3.口语歧义现象分析从上面的统计结果我们可以看出,在口语会话中无论是用词情况,还是句子结构等各方面,与书面语相比都有较大的差异。除了上述已经获得的统计结果以外,口语中出现的歧义现象也十分复杂,以下我们对口语中的歧义现象进行分析。3.1口语中的词汇歧义同书面语中的词汇歧义一样,口语中的词汇歧义主要是由词汇的一词多义引起的。在口语词类的划分中,尽管有些词按严格的汉语词法规定不能算作词,如“不好、不行、行了”等,但考虑到它们在口语中大量地存在,并且含义相对固定,因此,我们将其作为一个词处理。但是,这些词在不同的场合下使用,有时仅仅是因为语气的差异而使其意思完全不一样。请看如下例子:(1)a.这样肯定不行。b.不行您过来一趟。在例句a中,“不行”表示对结果的一种判断,是确定性的;而在例句b中,“不行”仅仅表示一种假设的语气,相当于“要不然的话”或“要不”。(2)a.您说的那个宾馆不是我们这里。b.价钱我们不是已经说好了吗?第一句中的“不是”是否定意义的断词,在句子中充当谓语成分;而第二句中的“不是”仅作为强调语气的一个填充性的词语,本身在句子中并不充当什么成分,含义也没有任何否定的意义,相反加强了肯定的语气。类似地,“不好,什么,那个”等在口语中都有不同的语义表示。3.2口语中的结构歧义由于口语语句中没有标点符号,又缺少了必要的声调、语
 三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 扫描二维码
扫描二维码








 wasi007
wasi007
本文标题:限定领域汉语口语对话语料分析AnalysisofSpo
链接地址:https://www.777doc.com/doc-447538 .html