您好,欢迎访问三七文档
当前位置:首页 > 商业/管理/HR > 公司方案 > Linux内存管理_陈莉君
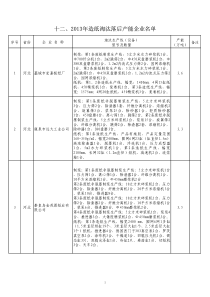
CompanyLOGOLinux中的内存管理西安邮电学院2CompanyLogo主要内容主要内容内容内容3CompanyLogo源程序到可执行文件一个hello.c源程序经过预处理、编译、汇编和链接四个阶段后,形成一个可执行文件hello。在Linux下可执行文件的格式为ELF(ExecutableandLinkableFormat)。4CompanyLogo程序的执行当在bash终端下执行可执行文件hello时,bash所属进程通过fork()系统调用创建一个子进程,该子进程是bash进程(即父进程)的一个副本。子进程通过execv()将可执行文件hello装入自己的地址空间,子进程便开始执行hello程序。5CompanyLogo程序执行的演示-code16CompanyLogo进程的虚拟地址空间程序一旦被执行就成为一个进程,内核就会为每个运行的进程提供了大小相同的虚拟地址空间,这使得多个进程可以同时运行而又不会互相干扰。具体来说一个进程对某个地址的访问,绝不会干扰其他进程对同一地址的访问。7CompanyLogo虚拟地址空间的划分每个进程都拥有4GB(32位)大小的虚拟地址空间,每个进程都拥有私有的前3G“”空间,即用户空间;而后1G“”空间被每个进程所共享,即内核空间。进程访问内核空间的唯一途径为系统调用。在每个进程眼中,它们各自拥有4GB大小的地址空间;而在CPU眼中,任意时刻,一个CPU上只存在一个虚拟地址空间。虚拟地址空间随着进程间的切换而变化。8CompanyLogo虚拟地址空间图示9CompanyLogo虚拟内存实现机制Linux虚拟内存的实现需要多种机制的支持:地址映射机制请页机制内存分配和回收机制交换机制缓存和刷新机制10CompanyLogo虚拟内存实现机制关系图11CompanyLogo进程用户空间管理每个进程经编译、链接后形成的二进制映像文件有一个代码段和数据段。进程运行时须有独占的堆栈空间。连接器和函数库所属的代码段、数据段。将文件映射到虚拟地址空间中的内存映像。它们在用户空间中是如何组织和管理的?12CompanyLogo进程地址空间布局图13CompanyLogo进程用户空间的数据结构Linux把进程的用户空间划分为若干个区间,便于管理,这些区间称为虚拟内存区域(简称vma)。一个进程的用户地址空间主要由mm_struct结构和vm_area_structs结构来描述。mm_struct结构对进程整个用户空间进行描述。m_area_structs结构对用户空间中各个内存区进行描述。14CompanyLogo内存描述符基本字段15CompanyLogovm_area_struct主要字段16CompanyLogo相关数据结构之间的关系一个进程在内核中使用task_struct结构对其进行描述。task_struct结构中的mm字段指向的便是与该进程用户空间所对应的mm_struct结构体。mm_struct结构中的mmap字段指向VMA双链表。使用current-mm-mmap就可以获得VMA链表的头指针。那么current-mm-mmap-vm-next就可以获得指向该VMA双联表的下一个结点的指针。17CompanyLogo相关结构的实例图18CompanyLogo进程用户空间的演示-code219CompanyLogo程序执行结果20CompanyLogo通过/proc查看该进程的虚拟地址空间21CompanyLogo新建虚拟内存区域从code2中可以看到,内核甚至为每种不同类型的数据都建立相应的虚拟内存区。那么内核通过怎样的方式新建一个VMA?22CompanyLogoVMA的新建方法在内核空间可以通过do_mmap()创建一个新的虚拟内存区域。在用户空间可以通过mmap()系统调用获取do_mmap()的功能。23CompanyLogommap()和do_mmap()24CompanyLogo内存映射内存映射:把文件从磁盘映射到进程用户空间的一个虚拟内存区域中,对文件的访问转化为对虚存区的访问。当从这段内存中读数据时,就相当于读磁盘文件中的数据,将数据写入这段内存时,则相当于将数据直接写入磁盘文件。这样就可以在不使用基本I/O操作函数read和write的情况下执行I/O操作。有共享的、私有的虚存映射和匿名映射。25CompanyLogommap()addr:映射到用户地址空间的起始地址,一般取NULLlength:映射内存区的字节长度prot:对映射区的保护要求,比如只读flags:指定内存区的属性fd:映射文件的描述符offset:文件起始映射的偏移量26CompanyLogommap()的演示-code327CompanyLogommap()28CompanyLogo访问内存code2中使用了malloc(),它负责为进程动态的申请一块内存,并且这快内存的首地址为str。malloc()执行后,内核是不是立即为进程分配了物理内存?29CompanyLogo虚拟内存与物理内存用户态的程序经过编译执行形成进程,进程虽然可以任意访问整个用户空间的内存,但这毕竟属于虚拟地址空间,因此进程最终必须访问到物理内存。将虚拟内存和物理内存连接起来的就是分页机制,它在虚拟地址和物理地址之间建立了一种映射关系。进程访问的是虚拟地址,虚拟地址通过页表的转换最终形成物理地址。如果某个虚拟地址在页表中并不存在和某个物理地址之间的映射,那么系统将发生一次缺页异常。30CompanyLogo地址之间的转换-保护模式下的寻址31CompanyLogo地址之间的转换-MMU机制32CompanyLogo请页机制当一个进程运行时,CPU访问的地址是用户空间的虚拟地址。Linux采用请页机制来节约物理内存,也就是说它仅仅将当前要使用的用户空间中少量页装入物理内存。当访问的虚拟内存页面尚未装入物理内存时,处理器将产生一个缺页异常。当发生缺页异常时,操作系统必须从磁盘或交换文件中将要访问的页装入物理内存。33CompanyLogo物理内存管理请页机制可以为进程请求物理内存,那么物理内存在内核中究竟是如何管理和分配的?接下来将从物理内存的逻辑模型开始说起。34CompanyLogo内核空间的划分在IA-32体系架构上,内核空间的地址范围是PAGE_0FFSET到4G。内核空间的第一部分试图将系统的所有物理内存线性映射到虚拟地址空间中,但最多只能映射high_memory(默认为896M)大小的物理内存。大于high_memory的物理内存将映射到内核空间的后部分。35CompanyLogo内核空间的划分图示按照这样的映射规则,0M到high_memory的物理内存称为低端内存,大于high_memory的物理内存称为高端内存。36CompanyLogo内核虚拟地址和物理地址的转换内核为线性映射的内存区提供物理地址和虚拟地址的转换函数:__pa(vaddr):返回虚拟地址vaddr对应的物理地址。__va(paddr):返回物理地址paddr对应的虚拟地址。37CompanyLogo地址转换函数的实现内核地址空间是从PAGE_OFFSET开始的,因此上述两个地址转换函数的源码实现如下:#define__pa(x)((unsignedlong)(x)-PAGE_OFFSET)#define__va(x)((void*)((unsignedlong)(x)+PAGE_OFFSET))38CompanyLogoUMA和NUMA目前有两种类型的计算机,分别以不同的方法管理物理内存:NUMA计算机(non-uniformmemoryaccess):总是多处理器计算机,每个CPU拥有各自的本地内存。这样的划分使每个CPU都能以较快的速度访问本地内存,各个CPU之间通过总线连接起来,这样也可以访问其他CPU的本地内存,只不过速度比较慢而已UMA计算机(uniformmemoryaccess):将可用内存以连续方式组织起来。39CompanyLogoUMA和NUMA示意图40CompanyLogo物理内存的组织为了兼容NUMA模型,内核引入了内存节点,每个节点关联一个CPU。各个节点又被划分几个内存区,每个内存区中又包含若干个页框。物理内存在逻辑上被划分为三级结构,分别使用pg_data_t,zone和page这三种数据结构依次描述节点,区和页框。41CompanyLogo物理内存三级结构图示42CompanyLogo内存节点NUMA计算机中每个CPU的物理内存称为一个内存节点,内核通过pg_data_t数据结构来描述,系统内的所有结点形成一个双链表。UMA模型下的物理内存只对应一个节点,也就是说整个物理内存形成一个节点,因此上述的节点链表中也就只有一个元素。43CompanyLogo内存管理区各个节点划分为若干个区,也是对物理内存的进一步细分。物理内存通过下面几个宏来标记不同的区:ZONE_DMA:标记适合DMA的内存区。ZONE_NORMAL:可以直接映射到内核空间的物理内存。ZONE_HIGHMEM:超出内核空间大小的物理内存。44CompanyLogo页框内核使用page结构体描述一个物理页框,该结构也称为页描述符。页框代表是物理内存的最小单位,每个物理页框都关联一个这样的结构体。所有的页描述符都存放在mem_map数组中。45CompanyLogo物理内存管理机制伙伴算法:负责大块连续物理内存的分配和释放,以页框为基本单位,可以避免外部碎片。slab缓存:负责小块物理内存的分配,并且它也作为一个缓存,主要针对内核中经常分配并释放的对象。per-CPU页框缓存:内核经常请求和释放单个页框,该缓存包含预先分配的页框,用于满足本地CPU发出的单一页框请求。46CompanyLogo伙伴算法概述Linux的伙伴算法把所有的空闲页面分为MAX_ORDER+1(该宏默认大小为11)个块链表,每个链表中的一个块含有2的幂次个页面,即页块或简称块。大小相同、物理地址连续的两个页块被称为伙伴。工作原理:首先在大小满足要求的块链表中查找是否有空闲块,若有则直接分配,否则在更大的块中查找。其逆过程就是块的释放,此时会把满足伙伴关系的块合并。47CompanyLogo与伙伴算法有关的数据结构每个物理页框对应一个structpage实例。每个内存区关联了一个structzone实例,该结构中使用free_area数组对空闲页框进行管理。48CompanyLogo伙伴算法数据结构49CompanyLogo伙伴算法结构实例图50CompanyLogo伙伴算法的分配原理伙伴算法的分配原理是,如果分配阶为i的页框块,那么先从第i条页框块链表中查找是否存在这么大小的空闲页块。如果有则分配,否则在第i+1条链表中继续查找,直到找到为止。如果申请大小为8的页块(分配阶为3),但却在页块大小为32的链表中找到空闲块,则先将这32个页面对半等分,前一半作为分配使用,另一半作为新元素插入下级大小为16的链表中;继续将前一半大小为16的页块等分,一半分配,另一半插入大小为8的链表中。51CompanyLogo页框分配的实现__rmqueue_smallest():在指定的内存分配区上,从所请求分配阶order对应的链表开始查找所需大小的空闲块,如果不成功则从高一阶的链表上继续查找。expand():如果所得到的内存块大于所请求的内存块,则按照伙伴算法的分配原理将大的页框块分裂成小的页框块。52CompanyLogo__rmqueue_smallest53CompanyLogoexpand()54CompanyLogo物理内存分配器基于伙伴算法、每CPU高速缓存和slab高速缓存形成两种内存分配器。第一种是分区页框分配器(zonedpageframeallocator),处理对连续页框的内存分配请求
 三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 扫描二维码
扫描二维码








 股神之鞭
股神之鞭
本文标题:Linux内存管理_陈莉君
链接地址:https://www.777doc.com/doc-4580887 .html