您好,欢迎访问三七文档
当前位置:首页 > 商业/管理/HR > 信息化管理 > 机器学习K-means
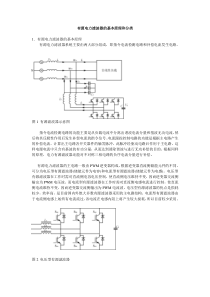
机器学习报告非监督学习-----一些聚类算法聚类是数据挖掘中用来发现数据分布和隐含模式的一项重要技术,聚类分析是指事先不了解一批样品中的每个样品的类别或者其他的先验知识,而唯一的分类依据是样品的特征,利用某种相似性度量的方法,把特征相同的或相近的分为一类,实现聚类分析。下面介绍五种聚类方法,每个算法的使用时有限的,不同的聚类酸腐蚀可以解决不同的问题。(一)K-means聚类K均值算法是一种常用的动态聚类算法,K均值算法能够使聚类集中所有样本到聚类中心的距离和最小。原理为:先选K个初始距离中心,计算每个样本到这K个中心的距离,找出最小距离把样本归入最近的聚类中心,然后对中心进行修改,得到新的K个中心,再计算样本到K个中心的距离,重新归类,重新计算中心,修改中心。直到新的聚类中心等于聚类中心则结束。修改聚类中心的准则函数是:GXZXJiNijijj,12其中:jG是第j个聚类;jN为第j个聚类中心的样本数;jZ为第j个样本的聚类中心。K次平均算法的聚类准则是:聚类中心jZ的选择应使准则函数的jJ值最小。因此,令NijiTjiNijijZXZXZZXZ1120解上式得jNiijXNZ11,其中jiGX上式表明,jG类得聚类中心应选为该类样本的均值。算法:Stept1:任选k个初始聚类中心lZlZlZk21,Stept2:计算每个样本到k个聚类中心的距离,并按最近规则归类。若kZXkZXij,则jikikGXj,,2,1,,其中:kGj为聚类中心kZj的样本聚类。在第k次迭代,分配各个样本X到k个聚类中心Stept3:从第二步的计算结果计算新的聚类中心。kGXijjjiXNkZ11,其中kj,,2,1上面应经证明,该聚类中心可以使准则函数的jJ值达到最小。Stept4;若新的聚类中心与前一个聚类中心相等,即kjkZkZjj,,2,1,1则算法收敛,聚类结束。否则,转入第二步。K均值方法的特点:该算法的特点是运算结果受所选的聚类中心的数目,初始位置,模式样本的几何性质以及读入的次序的影响。在实际运用时,要试探选择不同的K值和起始聚类中心。如果模式样本为N个孤立的区域分布,则一般都能得到收敛结果。(二)Kmedoid方法Kmedoid方法同Kmeans方法类似,它们之间的差别就是Kmedoid方法中的最新的聚类中心是集合中的点到原来聚类中心的点最近距离的点,即:聚类中心都是集合中的点。Stept1:任选k个初始聚类中心lZlZlZk21,Stept2:计算每个样本到k个聚类中心的距离,并按最近规则归类。若22kZXkZXij,则jikikGXj,,2,1,,其中:kGj为聚类中心kZj的样本聚类。在第k次迭代,分配各个样本X到k个聚类中心Stept3:从第二步的计算结果计算新的聚类中心。kGXijjjiXNkV11,其中kj,,2,1然后求解问题2minkVXjkGXj,得到的X定义为第J类得新的中心。即定义XkZj1。Stept4:若新的聚类中心与前一个聚类中心相等,即kjkZkZjj,,2,1,1则算法收敛,聚类结束。否则,转入第二步。通过算法过程可以发现,该算法与Kmeans方法除了第三步不同外,其他的过程都是相同的。下面给出Kmeans方法与Kmedoid方法对同一组数据的聚类结果。00.10.20.30.40.50.60.70.80.9100.10.20.30.40.50.60.70.80.9100.10.20.30.40.50.60.70.80.9100.10.20.30.40.50.60.70.80.91该图为Kmeans方法分为3类和4类得结果.可以发现该聚类中心并不是集合中本身的点。00.10.20.30.40.50.60.70.80.9100.10.20.30.40.50.60.70.80.9100.10.20.30.40.50.60.70.80.9100.10.20.30.40.50.60.70.80.91图为用Kmeans方法得到的3类和4类的结果从图中可以看出,Kmedoid方法分类中,聚类中心点全是集合本身的点,且与Kmeans方法比较,聚类中心点近似的,且分类结果也差不多。注:Kmeans方法和Kmedoid方法对初始值要求比较敏感,且要求各类的密度差不多。(三)谱聚类为了能在任意形状的样本空间上聚类,且收敛于全局最优解,现研究利用谱方法来聚类。谱方法聚类是由数据点间相似关系建立矩阵,获取该矩阵的前n个特征向量,并且用它们来聚类不同的数据点。谱聚类方法建立在图论中的谱图理论上。谱聚类算法将数据集中的每个对象看作是图的顶点V,将顶点间的相似度量化作为相应顶点连接边E的权值,这样就得到一个基于相似度的无向加权图G(V,E),于是聚类问题就可以转化为图的划分问题。基于图论的最优划分准则就是使划分成的子图内部相似度最大,子图之间的相似度最小。针对这个问题,Shi和MalikEz提出了基于将图划分为两个子图的2-way目标函数Ncut:BjiijBAijijABjAiijwdwdwBAcutdBBAcutdABAcutBANCut,,,,,min,其中cut(A,B)是子图A,B间的边,又叫“边切集”。其中ijw为连点之间定义的权重。我们可以看出改进后目标函数不仅满足类间样本间的相似度小,也满足类内样本间的相似度大。现令P是A的划分指示向量:BjnnnAjnnnfj,,2112其中1n为A中样本的个数,2n为B中样本的个数,n为样本的总数。那么:问题可转化为:TnTfffffWDfBANcut),,,(,),(21其中jijinwddddD,21,nijwW且满足111,0eefT其中求该问题中的f是离散的,为了解决该问题,我们将问题f进行放松为连续的情况,转化为:fWDfRalextmin:S.t102fefT可得:由L=D-W的性质,该问题的解为矩阵WD对应的第二最小特征值,f取对应的特征向量。对应于第二最小特征值对应的特征向量X2则包含了图的划分信息。人们可以根据启发式规则在X2寻找划分点i,使得值大于等于X2i的划为A类,而小于X2i的划为B类。注:L=D-W称为Laplacian矩阵:Laplacian矩阵是对称半正定矩阵,因此它的所有特征值是实数且是非负的:如果G是c个连接部件,那么L有c个等于0的特征向量。如果G是连通的,第二个最小特征值不为0,则它是G的连接代数值(Fiedter-value)。其对应的特征向量为Fiedler向量。具体算法叙述如下:Stept1:通过样本集建立无向加权图G,根据G构造W和D;Stept2:计算L=D-W的第二最小特征值2x及对应的Fiedler向量;Stept3:根据启发式规则在2x寻找划分点i,使得值大于等于X2i的划为A类,而小于X2i的划为B类;注:对于大于2类的k情况,在第二步中取L的除了最小特征值外剩下的k个特征值和对应的特征向量。然后对特征向量空间的特征向量用k-means方法聚类。(四)模糊C-means方法模糊聚类算法是一种基于函数最优方法的聚类算法,使用微积分计算技术求最优代价函数,在基于概率算法的聚类方法中将使用概率密度函数,为此要假定合适的模型,模糊聚类算法的向量可以同时属于多个聚类。K-均值算法在聚类过程中,每次得到的结果虽然不一定是期望的结果,但类别之间的边界是明确的,聚类中心根据各类当前具有的样本进行修改。模糊C-均值算法在聚类过程中,每次得到的类别边界任然是模糊的,每次聚类中心的修改都要用到所有的样本,此外,聚类准则也体现了模糊行。现先虑属度解释,隶属度函数是表示一个对象x隶属于集合A的程度的函数,通常记做xA,其自变量范围是所有可能属于集合A的对象(即集合A所在空间中的所有点),取值范围是[0,1],即10xA。1xA表示x完全隶属于集合A,相当于传统集合概念上的Ax。一个定义在空间xX上的隶属度函数就定义了一个模糊集合A,或者叫定义在论域xX上的模糊子集~A。对于有限个对象nxxx,,,21模糊集合~A可以表示为:}|)),({(~XxxxAiiiA(6.1)有了模糊集合的概念,一个元素隶属于模糊集合就不是硬性的了,在聚类的问题中,可以把聚类生成的簇看成模糊集合,因此,每个样本点隶属于簇的隶属度就是[0,1]区间里面的值。对于模糊C均值聚类算法的步骤还是比较简单的,模糊C均值聚类(FCM),即众所周知的模糊ISODATA,是用隶属度确定每个数据点属于某个聚类的程度的一种聚类算法。1973年,Bezdek提出了该算法,作为早期硬C均值聚类(HCM)方法的一种改进。FCM把n个向量ixni,,2,1分为c个模糊组,并求每组的聚类中心,使得非相似性指标的价值函数达到最小。FCM用模糊划分,使得每个给定数据点用值在[0,1]间的隶属度来确定其属于各个组的程度。与引入模糊划分相适应,隶属矩阵U允许有取值在[0,1]间的元素。不过,加上归一化规定,一个数据集的隶属度的和总等于1:ciijnju1,...,1,1那么,FCM的目标函数的一般化形式:cinjijmijciicduJccUJ1211),...,,(,(*)这里iju介于0,1间;ic为模糊组i的聚类中心,jiijxcd为第i个聚类中心与第j个数据点间的欧几里德距离;且,1m是一个加权指数。构造如下新的目标函数,可求得使(*)式达到最小值的必要条件:njciijjcinjijmijnjciijjcncuduuccUJccUJ111211111)1()1(),...,,(),...,,,...,,(这里j,j=1到n,是n个约束式的拉格朗日乘子。对所有输入参量求导,使式(*)达到最小的必要条件为:njmijnjjmijiuxuc11ckmkjijijddu1)1/(21由上述两个必要条件,模糊C均值聚类算法是一个简单的迭代过程。具体步骤叙述如下:Stept1:确定模式类别数C,C小于样本总数N。Stept2:用值在[0,1]间的随机数初始化隶属矩阵0ijuU,使其满足式上式中的约束条件,其中iju表示第j个元素对第i类的隶属度。且矩阵的每列元素之和等于1.Stept3:求各类的聚类中心LCi,L为迭代的次数。njmijnjjmijiuxuLC11其中参数m控制着聚类模糊程度的常数。Stept4:计算新的隶属矩阵1LU,矩阵元素的计算为ckmkjijijddLu1)1/(211避免坟墓为零,特规定,0ijd则ipLuLupjij01,11可见,ijd越大,1Luij越小。Stept5:回到第三步,知道收敛。收敛条件为LuLuijijji1max,参数C,m的选择模糊C-算法需要两个参数一个是聚类数目C,另一个是参数m。一般来讲C要远远小于聚类样本的总个数,同时要保证C1。对于m,它是一个控制算法的柔性的参数,如果m过大,则聚类效果会很次,而如果m过小则算法会接近HCM聚类算法。下面给出K-means方法和模糊C-means方法对某组样本的聚类结果:00.10.20.30.40.50.60.70.80.9100.10.20.30.40.50.60.70.80.91图100.10.20.30.40.50.60.70.80.9100.10.20.30.40.50.60.70.80.91图200.10
 三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 扫描二维码
扫描二维码








 heyanli
heyanli
本文标题:机器学习K-means
链接地址:https://www.777doc.com/doc-5058628 .html