您好,欢迎访问三七文档
当前位置:首页 > 商业/管理/HR > 信息化管理 > 聚类分析—K-means-and-K-medoids聚类
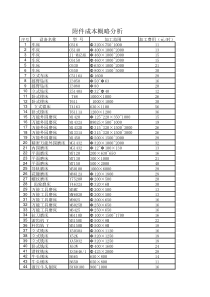
数据挖掘Topic3--聚类分析K-means&K-medoids聚类2020/4/29主要内容K-means算法Matlab程序实现在图像分割上的简单应用K-medoids算法k-中心点聚类算法--PAMK-medoids改进算法2020/4/29基于划分的聚类方法构造n个对象数据库D的划分,将其划分成k个聚类启发式方法:k-平均值(k-means)和k-中心点(k-medoids)算法k-平均值(MacQueen’67):每个簇用该簇中对象的平均值来表示k-中心点或PAM(Partitionaroundmedoids)(Kaufman&Rousseeuw’87):每个簇用接近聚类中心的一个对象来表示这些启发式算法适合发现中小规模数据库中的球状聚类对于大规模数据库和处理任意形状的聚类,这些算法需要进一步扩展2020/4/29K-means聚类算法算法描述1.为中心向量c1,c2,…,ck初始化k个种子2.分组:将样本分配给距离其最近的中心向量由这些样本构造不相交(non-overlapping)的聚类3.确定中心:用各个聚类的中心向量作为新的中心4.重复分组和确定中心的步骤,直至算法收敛2020/4/29K-means聚类算法(续)算法的具体过程1.从数据集中任意选取k个赋给初始的聚类中心c1,c2,…,ck;2.对数据集中的每个样本点xi,计算其与各个聚类中心cj的欧氏距离并获取其类别标号:3.按下式重新计算k个聚类中心;4.重复步骤2和步骤3,直到达到最大迭代次数为止。1{}Nnnx2()argmin||||,1,...,,1,...,ijjlabeliiNjkxc:(),1,2,...,sslabelsjjjcjkNx2020/4/29Matlab程序实现function[M,j,e]=kmeans(X,K,Max_Its)[N,D]=size(X);I=randperm(N);M=X(I(1:K),:);Mo=M;forn=1:Max_Itsfork=1:KDist(:,k)=sum((X-repmat(M(k,:),N,1)).^2,2)';end[i,j]=min(Dist,[],2);fork=1:Kifsize(find(j==k))0M(k,:)=mean(X(find(j==k),:));endend2020/4/29Matlab程序实现(续)Z=zeros(N,K);form=1:NZ(m,j(m))=1;ende=sum(sum(Z.*Dist)./N);fprintf('%dError=%f\n',n,e);Mo=M;end2020/4/29k-平均聚类算法(续)例012345678910012345678910012345678910012345678910012345678910012345678910012345678910012345678910012345678910012345678910K=2任意选择K个对象作为初始聚类中心将每个对象赋给最类似的中心更新簇的平均值重新赋值更新簇的平均值重新赋值2020/4/29在图像分割上的简单应用例1:1.图片:一只遥望大海的小狗;2.此图为100x100像素的JPG图片,每个像素可以表示为三维向量(分别对应JPEG图像中的红色、绿色和蓝色通道);3.将图片分割为合适的背景区域(三个)和前景区域(小狗);4.使用K-means算法对图像进行分割。2020/4/29在图像分割上的简单应用(续)分割后的效果注:最大迭代次数为20次,需运行多次才有可能得到较好的效果。2020/4/29在图像分割上的简单应用(续)例2:注:聚类中心个数为5,最大迭代次数为10。2020/4/29k-平均聚类算法(续)优点:相对有效性:O(tkn),其中n是对象数目,k是簇数目,t是迭代次数;通常,k,tn.当结果簇是密集的,而簇与簇之间区别明显时,它的效果较好Comment:常常终止于局部最优.全局最优可以使用诸如确定性的退火(deterministicannealing)和遗传算法(geneticalgorithms)等技术得到2020/4/29k-平均聚类算法(续)弱点只有在簇的平均值(mean)被定义的情况下才能使用.可能不适用于某些应用,例如涉及有分类属性的数据需要预先指顶簇的数目k,不能处理噪音数据和孤立点(outliers)不适合用来发现具有非凸形状(non-convexshapes)的簇2020/4/29k-中心点聚类方法k-平均值算法对孤立点很敏感!因为具有特别大的值的对象可能显著地影响数据的分布.k-中心点(k-Medoids):不采用簇中对象的平均值作为参照点,而是选用簇中位置最中心的对象,即中心点(medoid)作为参照点.0123456789100123456789100123456789100123456789100123456789100123456789102020/4/29k-中心点聚类方法(续)找聚类中的代表对象(中心点)PAM(PartitioningAroundMedoids,1987)首先为每个簇随意选择选择一个代表对象,剩余的对象根据其与代表对象的距离分配给最近的一个簇;然后反复地用非代表对象来替代代表对象,以改进聚类的质量PAM对于较小的数据集非常有效,但不能很好地扩展到大型数据集CLARA(Kaufmann&Rousseeuw,1990)抽样CLARANS(Ng&Han,1994):随机选样2020/4/29k-中心点聚类方法(续)基本思想:首先为每个簇随意选择选择一个代表对象;剩余的对象根据其与代表对象的距离分配给最近的一个簇然后反复地用非代表对象来替代代表对象,以改进聚类的质量聚类结果的质量用一个代价函数来估算,该函数评估了对象与其参照对象之间的平均相异度21||||jkijpCEpo2020/4/29k-中心点聚类方法(续)为了判定一个非代表对象Orandom是否是当前一个代表对象Oj的好的替代,对于每一个非代表对象p,考虑下面的四种情况:第一种情况:p当前隶属于代表对象Oj.如果Oj被Orandom所代替,且p离Oi最近,i≠j,那么p被重新分配给Oi第二种情况:p当前隶属于代表对象Oj.如果Oj被Orandom代替,且p离Orandom最近,那么p被重新分配给Orandom第三种情况:p当前隶属于Oi,i≠j。如果Oj被Orandom代替,而p仍然离Oi最近,那么对象的隶属不发生变化第四种情况:p当前隶属于Oi,i≠j。如果Oj被Orandom代替,且p离Orandom最近,那么p被重新分配给Orandom2020/4/29k-中心点聚类方法(续)1.重新分配给Oi2.重新分配给Orandom3.不发生变化4.重新分配给Orandomk-中心点聚类代价函数的四种情况2020/4/29k-中心点聚类方法(续)算法:k-中心点(1)随机选择k个对象作为初始的代表对象;(2)repeat(3)指派每个剩余的对象给离它最近的代表对象所代表的簇;(4)随意地选择一个非代表对象Orandom;(5)计算用Orandom代替Oj的总代价S;(6)如果S0,则用Orandom替换Oj,形成新的k个代表对象的集合;(7)until不发生变化2020/4/29PAMPAM(PartitioningAroundMedoids)(KaufmanandRousseeuw,1987)是最早提出的k-中心点聚类算法基本思想:随机选择k个代表对象反复地试图找出更好的代表对象:分析所有可能的对象对,每个对中的一个对象被看作是代表对象,而另一个不是.对可能的各种组合,估算聚类结果的质量2020/4/29PAM(续)012345678910012345678910TotalCost=20012345678910012345678910K=2Arbitrarychoosekobjectasinitialmedoids012345678910012345678910AssigneachremainingobjecttonearestmedoidsRandomlyselectanonmedoidobject,OramdomComputetotalcostofswapping012345678910012345678910TotalCost=26SwappingOandOramdomIfqualityisimproved.DoloopUntilnochange0123456789100123456789102020/4/29PAM(续)当存在噪音和孤立点时,PAM比k-平均方法更健壮.这是因为中心点不象平均值那么容易被极端数据影响PAM对于小数据集工作得很好,但不能很好地用于大数据集每次迭代O(k(n-k)2)其中n是数据对象数目,k是聚类数基于抽样的方法,CLARA(ClusteringLARgeApplications)2020/4/29CLARA(ClusteringLargeApplications)(1990)CLARA(KaufmannandRousseeuwin1990)不考虑整个数据集,而是选择数据的一小部分作为样本它从数据集中抽取多个样本集,对每个样本集使用PAM,并以最好的聚类作为输出优点:可以处理的数据集比PAM大缺点:有效性依赖于样本集的大小基于样本的好的聚类并不一定是整个数据集的好的聚类,样本可能发生倾斜例如,Oi是最佳的k个中心点之一,但它不包含在样本中,CLARA将找不到最佳聚类2020/4/29CLARA--效率由取样大小决定PAM→利用完整资料集CLARA→利用取样资料集盲点:取样范围不包含最佳解sampledbest242020/4/29CLARA改良解決:CLARANS(ClusteringLargeApplicationbaseduponRANdomizedSearch)应用graph考虑紧邻节点不局限于区域性负杂度:O(n^2)→缺点252020/4/29CLARANS(“Randomized”CLARA)(1994)CLARANS(AClusteringAlgorithmbasedonRandomizedSearch)(NgandHan’94)CLARANS将采样技术和PAM结合起来CLARA在搜索的每个阶段有一个固定的样本CLARANS任何时候都不局限于固定样本,而是在搜索的每一步带一定随机性地抽取一个样本聚类过程可以被描述为对一个图的搜索,图中的每个节点是一个潜在的解,也就是说k-medoids相邻节点:代表的集合只有一个对象不同在替换了一个代表对象后得到的聚类结果被称为当前聚类结果的邻居2020/4/29CLARANS(续)如果一个更好的邻居被发现,CLARANS移到该邻居节点,处理过程重新开始,否则当前的聚类达到了一个局部最优如果找到了一个局部最优,CLARANS从随机选择的节点开始寻找新的局部最优实验显示CLARANS比PAM和CLARA更有效CLARANS能够探测孤立点聚焦技术和空间存取结构可以进一步改进它的性能(Esteretal.’95)2020/4/29综合比较KmeansKmedoidsCLARACLARANS优点简单不受极值影响可处理大数据找到最佳解缺点受极值影响无法处理大数据不一定是最佳解速度慢复杂度O(nkt)O(k(n-k)^2)O(ks^2+k(n-k))O(n^2)精確度速度282020/4/29作业编程实现K-means算法针对UCI的waveform数据集中每类数据取100个;对一副无噪图像进行分割;编程实现PAM对部分waveform数据集加20%的高斯噪声;同时对一副噪声图像进行分割;编程实现CLARA在全部的waveform数据集上的聚类;duedate:4月25
 三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 扫描二维码
扫描二维码









 h2041075
h2041075
本文标题:聚类分析—K-means-and-K-medoids聚类
链接地址:https://www.777doc.com/doc-5133651 .html