您好,欢迎访问三七文档
当前位置:首页 > 商业/管理/HR > 信息化管理 > 人工智能课程设计基于KMEANS的文本聚类算法实现
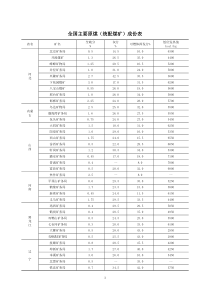
山西大学研究生学位课程论文(2014----2015学年第一学期)学院(中心、所):计算机与信息技术学院专业名称:计算机应用技术课程名称:人工智能论文题目:基于K-means的文本聚类算法授课教师(职称):王文剑研究生姓名:刘杰飞年级:2014级学号:201422403003成绩:评阅日期:山西大学研究生学院2015年1月23日基于K-means的文本聚类算法1摘要随着互联网飞速发展,尤其是大数据时代,为了快速找到用户感兴趣的相关信息,已经越来越成为当下计算机信息处理的任务。人类在面对大量数据时候,通常是将其先分类,将相似的数据归结为一类,根据聚类假设数据相似意味着处理方法和处理结果也是相似的。机器学习是研究机器如何实现人类的学习行为,以获取新的知识技能,并且不断完善自身的性能。其中归纳学习的一种策略是通过对事例进行概念描述,采用聚类的方法将相似的事例划分为一类,从而对信息进行预处理。本文基于K-means的聚类方法对文本进行聚类处理。用余弦夹角计算文本相似度,用方差计算两个数据间欧氏距离,从而将实验数据进行分类。采用Java语言编写代码,在MyEclipse实现结果。关键词聚类;文本;K-means;相似度;距离;AbstractWiththerapiddevelopmentoftheInternet,especiallyintheageofbigdata,inordertoquicklyfindtherelatedinformationofinteresttotheuser,hasincreasinglybecomeacomputerinformationprocessingthecurrentdifficulttask.Whenwehandlealargenumberofdata,usuallyfirstclassification,thesimilardataisreducedtoaclass,becausethedatasimilaritymeansthattheprocessingmethodandtheprocessingresultissimilar.Machinelearningisthestudyofhowthemachineistotherealizationofhumanlearning,toacquirenewknowledgeandskills,andcontinuouslyimproveitsperformance.Onestrategyofinductivelearningiscarriedoutthroughtheconceptofcasedescription,useclusteringmethodtothesimilarcasesclassifiedasaclass,thustopreprocessinformation.Inthispaper,clusteringprocessingoftextclusteringmethodbasedonK-means.Thecalculationoftextsimilaritybythecosineangle,calculatingtheEuclideandistancebetweentwodatavariance,thustheexperimentaldataclassification.TheuseofJavalanguagecode,intheMyEclipsetoachieveresults.Keywordsclustering;text;K-means;similarity;distance;1.引言随着大数据时代的来临,我们每天都要接受来自社会,生活中各种各样的信息,如何从浩如烟海的信息海洋中提取接收到自己感兴趣的信息,是每一个人关注的问题。在这里面关于文本信息的处理就是一种比较典型的问题。人类在学习时候一般是采用归纳演绎,为了使机器也具有这样的学习能力,来处理数据信息。根据文本数据的不同特征,按照数据间的相似性,将其划分为不同数据类的过程即是文本聚类。其目的是使同一类别的文本数据间相似度尽可能大,而不同类别的文本间的相似度尽可能的小。在这一过程中无需指导,是一种典型的无监督分类。文本聚类在推荐用户感兴趣的信息,以及文本信息融合,冗余消除方面都有一定的实际意义。2.文本聚类算法概述2.1文本聚类算法研究现状目前对文本聚类的研究以经很成熟了,国内外提出了很多的聚类方法,比较典型的有划分法,层次法,基于密度的方法,基于网格的方法和基于模型的方法。每种方法都各有其特点。2.1.1划分法2聚类中划分的思想是给定一个有N个元组或者记录的数据集,分裂构造为K个分组,每一个分组即代表一类,KN,并且每个分组至少包含一个数据记录;每个数据记录隶属于一个分组。如果开始时候划分出要划分数目的话,可以根据划分数目K选出K个初始聚类中心,然后进行迭代,反复在这K个簇间重新定位聚类中心,并重新分配每个簇中的对象,使得同一个分类间相似度尽量高。比较典型的算法有K-means算法、K-medoids算法。这两个算法的区别在于前者使用所有点的均值来做类中心,后者用每个数据对象来代表类中心。2.1.2层次法基于层次的聚类方法是通过分解给定的数据对象集来创建一个层次,这种方法一般有两种思路。一种是认为每个对象自己是一类,然后根据相似性进行合并,最后得到一个比较满意的划分结果,或者最终合并为一个类。另一种是将所有对象看成一类,根据规则进行分解,直到得到满意的结果,或者每个类只有一个数据对象。但是这种方法时间复杂度较高,不适合于大文本的数据集合。并且一旦类之间分解或者合并后一般过程不可以撤销,类间对象也不可以交换,负责结果质量会受到较大影响。3.K-means算法介绍K-means算法是很典型的硬聚类算法,基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的类作为最终目标。k个初始类聚类中心点的选取对聚类结果具有较大的影响,因为在该算法第一步中是随机的选取任意k个对象作为初始聚类的中心,初始地代表一个类。该算法在每次迭代中对数据集中剩余的每个对象,根据其与各个类中心的距离将每个对象重新赋给最近的类。当考察完所有数据对象后,一次迭代运算完成,新的聚类中心被计算出来。算法过程如下:1)从N个文档随机选取K个文档作为质心2)对剩余的每个文档测量其到每个质心的距离,并把它归到最近的质心的类3)重新计算已经得到的各个类的质心4)迭代2~3步直至新的质心与原质心相等或小于指定阈值,算法结束本文使用的方法中余弦夹角计算文本相似度,用方差计算两个数据间欧氏距离。余弦相似性度量:欧氏距离:4.实验分析34.1实验数据本实验自行选取了一些文本数据词汇。如下:初步分析以下文本数据分为asp.net,奥运运动,股民的信息。奥运击剑入场券基本分罄邹市明夺冠对手浮出水面股民要了解自己的目的印花税之股民四季杭州股民放鞭炮庆祝个人税下调残疾女青年入围奥运游泳比赛创奥运历史两项第一介绍一个ASP.netMVC系列教程在asp.net中实现观察者模式,或有更好的方法(续)Asp.Net页面执行流程分析运动员行李将“后上先下”奥运相关人员行李实名制asp.net控件开发显示控件内容奥运票务网上成功订票后应及时到银行代售网点付款某心理健康站开张后首个咨询者是位新股民ASP.NET自定义控件复杂属性声明持久性浅析4.2实验设计主要代码4.2.1程序开始:publicstaticvoidmain(String[]args)throwsIOException{//1、获取文档输入String[]docs=getInputDocs(D:\\java\\myeclipse\\textcluster\\src\\textcluster\\input.txt);if(docs.length1){System.out.println(没有文档输入);System.in.read();return;}//2、初始化TFIDF测量器,用来生产每个文档的TFIDF权重TFIDFMeasuretf=newTFIDFMeasure(docs,newTokeniser());System.out.println(tf.get_numTerms());intK=2;//聚成3个聚类//3、生成k-means的输入数据,是一个联合数组,第一维表示文档个数,//第二维表示所有文档分出来的所有词double[][]data=newdouble[docs.length][];intdocCount=docs.length;//文档个数intdimension=tf.get_numTerms();//所有词的数目for(inti=0;idocCount;i++){for(intj=0;jdimension;j++){data[i]=tf.GetTermVector2(i);//获取第i个文档的TFIDF权重向量}4}//4、初始化k-means算法,第一个参数表示输入数据,第二个参数表示要聚成几个类WawaKMeanskmeans=newWawaKMeans(data,K);//5、开始迭代kmeans.Start();//6、获取聚类结果并输出WawaCluster[]clusters=kmeans.getClusters();for(WawaClustercluster:clusters){ListIntegermembers=cluster.CurrentMembership;System.out.println(-----------------);for(inti:members){System.out.println(docs[i]);}}}///summary///获取文档输入////summary///returns/returnsprivatestaticString[]getInputDocs(Stringfile){ListStringret=newArrayListString();try{BufferedReaderbr=newBufferedReader(newInputStreamReader(newFileInputStream(file)));{Stringtemp;while((temp=br.readLine())!=null){ret.add(temp);}}}catch(Exceptionex){ex.printStackTrace();}String[]fileString=newString[ret.size()];return(String[])ret.toArray(fileString);}4.2.2K-means方法实现代码:///summary///聚类///定义一个变量用于记录和跟踪每个资料点属于哪个群聚类///_clusterAssignments[j]=i;//表示第j个资料点对象属于第i个群聚类////summary5finalint[]_clusterAssignments;///summary///定义一个变量用于记录和跟踪每个资料点离聚类最近////summaryprivatefinalint[]_nearestCluster;///summary///定义一个变量,来表示资料点到中心点的距离,///其中—_distanceCache[i][j]表示第i个资料点到第j个群聚对象中心点的距离;////summaryprivatefinaldouble[][]_distanceCache;///summary///用来初始化的随机种子////summaryprivatestaticfinalRandom_rnd=newRandom(1);publicWawaKMeans(double[][]data,intK
 三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 扫描二维码
扫描二维码








 hysteric1980
hysteric1980
本文标题:人工智能课程设计基于KMEANS的文本聚类算法实现
链接地址:https://www.777doc.com/doc-5857279 .html