您好,欢迎访问三七文档
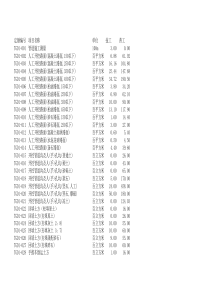
第5章决策树及应用5.1问题概述各个领域的人工智能实现,常常要涉及这样的问题:从实际问题中提取数据,并从数据中提炼一组数据规则,以支持知识推理实现智能的功能。知识规则一般以“原因—结果”形式表示。一般地,获取知识规则可以通过样本集{(𝑥1(𝑘),𝑥2(𝑘),⋯,𝑥𝑛(𝑘),𝑦(𝑘))|𝑘=1,2,⋯,𝑚},建模实现。由于推理结果是有限个,即y的取值是有限的,所以这样的建模属于分类问题。利用神经网络可以实现分类问题建模,但当影响因素变量𝑥𝑖的个数较大时,建模后的知识规则不易表示,特别地,当默写变量𝑥𝑖的取值缺失时,即使神经网络具有容错性,也会在一定程度上影响分类结果的不确定性。实际应用中,决定分类结果可能只是几个主要影响因素取值,不依赖全部因素变量,因此,知识规则的提取,可以转换为这样的问题:某一分类下哪些变量是主要的影响因素,这些主要影响因素与分类结果的因素规则表示如何获取?决策树就是解决这些问题的方法之一。5.2决策树概述决策树学习算法是一组样本数据集(一个样本数据也可以称为实例)为基础的一种归纳学习算法,它着眼于从一组无次序、无规则的样本数据(概念)中推理出决策树表示形式的分类规则。假设这里的样本数据应该能够用“属性—结论”。决策时是一个可以自动对数据进行分类的树形结构,是树形结构的知识表示,可以直接转换为分类规则。它能被看做基于属性的预测模型,树的根节点是整个数据集空间,每个分结点对应一个分裂问题,它是对某个单一变量的测试,该测试将数据集合空间分割成两个或更多数据块,每个叶结点是带有分类结果的数据分割。决策树算法主要针对“以离散型变量作为属性类型进行分类”的学习方法。对于连续性变量,必须被离散化才能被学习和分类。基于决策树的决策算法的最大的有点就在于它在学习过程中不需要了解很多的背景知识,只从样本数据及提供的信息就能够产生一颗决策树,通过树结点的分叉判别可以使某一分类问题仅与主要的树结点对应的变量属性取值相关,即不需要全部变量取值来判别对应的范类。5.2.1决策树基本算法一颗决策树的内部结点是属性或属性的集合,儿叶结点就是学习划分的类别或结论,内部结点的属性称为测试属性或分裂属性。当通过一组样本数据集的学习产生了一颗决策树之后,就可以对一组新的未知数据进行分类。使用决策树对数据进行分类的时候,采用自顶向下的递归方法,对决策树内部结点进行属性值的判断比较并根据不同的属性值决定走向哪一条分支,在叶节点处就得到了新数据的类别或结论。从上面的描述可以看出从根结点到叶结点的一条路径对应着一条合取规则,而整棵决策树对应着一组合取规则。图5.1简单决策树根据决策树内部结点的各种不同的属性,可以将决策树分为以下几种:(1)当决策树的每一个内部结点都只包含一个属性时,称为单变量决策树;当决策树存在包含多个变量的内部结点时,称为多变量决策树。(2)根据测试属性的不同属性值的个数,可能使得每一个内部结点有两个或者是多个分支,如果每一个内部结点只有两个分支则称之为二叉树决策。(3)分类结果可能是两类也可能是多类,二叉树决策的分类结果只能有两类,股也称之为布尔决策树。5.2.2CLS算法CLS学习算法是1966年有Hunt等人提出的。它是最早的决策树学习算法。后来的许多决策树算法都可以看作是CLS学习算法的改进与更新。CLS的算法的思想就是从一个空的决策出发,根据样本数据不断增加新的分支结点,直到产生的决策树能够正确地将样本数据分类为止。CLS算法的步骤如下:(1)令决策树T的初始状态只含有一个树根(X,Q),其中X是全体样本数据的集合,BCA1234𝑎1𝑎2𝑏1𝑏2𝑐1𝑐2Q是全体测试属性的集合。(2)如果T中所有叶结点(𝑋′,𝑄‘)都有如下状态:或者𝑋′中的样本数据都是属于同一个类,或者𝑄‘为空,则停止执行学习算法,学习的结果为T。(3)否则,选择一个不具有(2)所描述状态的叶节点(𝑋′,𝑄‘).(4)对于𝑄‘,按照一定规则选取属性b∈𝑄‘,设𝑋′被b的不同取值分为m个不同的子集𝑋′,1≤i≤m,从(𝑋′,𝑄‘)伸出m个分支,每个分支代表属性b的一个不同取值,从而形成m个新的叶结点(𝑋′,𝑄‘−|𝑏|),1≤i≤m。(5)转(2)。在算法步骤(4)中,并没有明确地说明按照怎样的规则来选取测试属性,所以CLS有很大的改进空间,而后来很多的决策树学习算法都是采取了各种各样的规则和标准来选取测试属性,所以说后来的各种决策树学习算法都是CLS学习算法的改进。5.2.3信息熵Shannon在1948年提出并发展了信息论的观点,主张用数学方法度量和研究信息,提出了以下的一些概念。决策树学习算法是以信息熵为基础的,这些概念将有助于理解后续的算法。(1)自信息量:在收到𝑎𝑖之前,接收者对信源发出𝑎𝑖的不确定性定义为信息符号𝑎𝑖的自信息量𝐼(𝑎𝑖)=−log2𝑝(𝑎𝑖),其中𝑝(𝑎𝑖)是取值为𝑎𝑖的概率。自信息量反映了接收𝑎𝑖的不确定性,自信息量越大,不确定性越大。(2)信息熵:自信息量只能反映符号的不确定性,而信息上可以用来度量整个信源X整体的不确定性。H(𝑋)=[−𝑝(𝑎1)log2𝑝(𝑎1)]+⋯+[−𝑝(𝑎𝑛)log2𝑝(𝑎𝑛)]=−∑𝑝(𝑎𝑖)log2𝑝(𝑎𝑖)𝑛𝑖=1(5.1)式中:n是信源X所有可能的符号数;𝑎𝑖是可能取到的值;𝑝(𝑎𝑖)是取值为𝑎𝑖的概率;信息熵是各个自信息量的期望。(3)条件熵:如果信源X与随机变量Y不是相互独立的,接收者收到信息Y,那么用条件熵H(𝑋|𝑌)来度量接信者收到随机变量Y之后,对随机变量X仍然存在的不确定性。X对应信源符号𝑎𝑖(𝑖=1,2,⋯,𝑛),Y对应信源符号𝑏𝑖(𝑖=1,2,⋯,𝑠),p(𝑎𝑖|𝑏𝑗)为当Y为𝑏𝑗时X为𝑎𝑖的概率,则有H(𝑋|𝑌)=∑𝑝(𝑏𝑗)𝑠𝑗=1H(𝑋|𝑏𝑗)=∑𝑝(𝑏𝑗)𝑠𝑗=1[−∑𝑝(𝑎𝑖|𝑏𝑗)log2𝑝(𝑎𝑖|𝑏𝑗)𝑛𝑖=1]=−∑∑𝑝(𝑏𝑗)𝑛𝑖=1𝑠𝑗=1𝑝(𝑎𝑖|𝑏𝑗)log2𝑝(𝑎𝑖|𝑏𝑗)=−∑∑𝑝(𝑎𝑖,𝑏𝑗)𝑛𝑖=1𝑠𝑗=1log2𝑝(𝑎𝑖|𝑏𝑗)即条件熵是各种不同条件下的信息熵期望。(4)平均互信息量:用来表示信号Y所能提供的关于X的信息量的大小,用下式表示,即I(𝑋|𝑌)=𝐻(𝑋)−H(𝑋|𝑌)5.3ID3算法上一节已经提到的CLS算法并没有明确地说明按照怎样的规则和标准来确定不同层次的树结点(即测试属性),Quinlan于1979年提出的以信息熵的下降速度作为选取测试属性的标准。ID3算法是各种决策树学习算法中最有影响力、使用最广泛的一种决策树学习算法。5.3.1基本思想设样本数据集为X,目的是要把样本数据集分为n类。设属于第i类的样本数据个数是𝐶𝑖,X中总的样本数据个数是|𝑋|,则一个样本数据属于第i类的概率p(𝐶𝑖)=𝐶𝑖|𝑋|。此时决策树对划分C的不确定程度(即信息熵)为H(𝑋,𝐶)=𝐻(𝑋)=−∑p(𝐶𝑖)log2p(𝐶𝑖)𝑛𝑖=1若选择属性a(设属性a有m个不同的取值)进行测试,其不确定程度(即条件熵)为H(𝑋|𝑎)=−∑∑𝑝(𝐶𝑖,𝑎=𝑎𝑗)𝑚𝑗=1𝑛𝑖=1log2𝑝(𝐶𝑖|𝑎=𝑎𝑗)=−∑∑𝑝(𝑎=𝑎𝑗)𝑝(𝐶𝑖|𝑎=𝑎𝑗)𝑚𝑗=1𝑛𝑖=1log2𝑝(𝐶𝑖|𝑎=𝑎𝑗)=∑𝑝(𝑎=𝑎𝑗)𝑚𝑗=1∑𝑝(𝐶𝑖|𝑎=𝑎𝑗)𝑛𝑖=1log2𝑝(𝐶𝑖|𝑎=𝑎𝑗)则属性a对于分类提供的信息量为I(𝑋,𝑎)=𝐻(𝑋)−H(𝑋|𝑎)式中:I(𝑋,𝑎)表示选择了属性a作为分类属性之后信息熵的下降程度,亦即不确定性下降的程度,所以应该选择时的I(𝑋,𝑎)最大的属性作为分类的属性,这样得到的决策树的确定性最大。可见ID3算法继承了CLS算法,并且根据信息论选择时的I(𝑋,𝑎)最大的属性作为分类属性的测试属性选择标准。另外,ID3算法除了引入信息论作为选择测试属性的标准之外,并且引入窗口的方法进行增量学习。ID3算法的步骤如下:(1)选出整个样本数据集X的规模为W的随机子集𝑋1(W称为窗口规模,子集称为窗口)。(2)以I(𝑋,𝑎)=𝐻(𝑋)−H(𝑋|𝑎)的值最大,即H(𝑋|𝑎)的值最小为标准,选取每次的测试属性,形成当前窗口的决策树。(3)顺序扫描所有样本数据,找出当前的决策树的例外,如果没有例外则结束。(4)组合当前窗口的一些样本数据与某些(3)中找到的李哇哦形成新的窗口,转(2)。5.3.2ID3算法应用实例表5.1是有关天气的数据样本集合。每一样本有4个属性变量:Outlook,Temperature,Humidity和Windy。样本被分为两类,P和N,分别表示正例和反例。表5.1天气样本数据首先计算信息熵H(𝑋),由表5.1可知,一共有24条记录,其中P类的记录和N类的记录都是12条,则根据上面介绍的信息熵和条件熵的算法,可以得到信息熵值为H(𝑋)=−1224log21224−1224log21224=1如果选取Outlook属性作为测试属性,则计算条件熵值H(𝑋|𝑂𝑢𝑡𝑙𝑜𝑜𝑘)。有表5.1可知,Outlook属性共有3个属性值,分别是Overcast、Sunny和Rain。Outlook属性取Overcast属性值的记录共有9条,其中P类的记录和N类的记录分别是4条和5条,因此有Overcast引起的熵值为−924(49log249+59log259)。而Outlook属性取Sunny属性值的记录共有7条,其中P类的记录和N类的记录分别是7条和0条,因此有Sunny引起的熵值为−724(77log277)。同理,Outlook属性取Rain属性值的记录共有8条,其中P类的记录和N类的记录分别是1条和7条,因此有Rain引起的熵值为−824(18log218+78log278)。因此条件熵值H(𝑋|𝑂𝑢𝑡𝑙𝑜𝑜𝑘)应为上述三个式子之和,得到H(𝑋|𝑂𝑢𝑡𝑙𝑜𝑜𝑘)=−924(49log249+59log259)−724(77log277)−824(18log218+78log278)=0.5528仿照上面条件熵值H(𝑋|𝑂𝑢𝑡𝑙𝑜𝑜𝑘)的计算方法,可以得到,如果选取Temperature属性为测试属性,则条件熵值为H(𝑋|𝑇𝑒𝑚𝑝𝑒𝑟𝑎𝑡𝑢𝑟𝑒)=−824(48log248+48log248)−1124(411log2411+711log2711)−524(45log245+15log215)=0.9172如果选取Humidity属性为测试属性,则条件熵值为H(𝑋|𝐻𝑢𝑚𝑖𝑑𝑖𝑡𝑦)=−1224(412log2412+812log2812)−1224(412log2412+812log2812)=0.9172如果选取Windy属性为测试属性,则条件熵值为H(𝑋|𝑊𝑖𝑛𝑑𝑦)=−824(48log248+48log248)−624(36log236+36log236)−1024(510log2510+510log2510)=1可见H(𝑋|𝑂𝑢𝑡𝑙𝑜𝑜𝑘)的值最小,所以应该选择Outlook属性作为测试属性,得到根据结点为Outlook属性,根据不同记录的Outlook属性取值的不同,向下引出三条分支,如图5.2所示,其中的数字代表第几条记录。图5.2ID3算法第一次分类的决策树综合表5.1和图5.2可以看出,由Sunny引出的分支包括(4,5,11,12,21,22,23)共7条记录,Outloo
 三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 扫描二维码
扫描二维码









 辉娜
辉娜
本文标题:决策树及应用
链接地址:https://www.777doc.com/doc-7127664 .html