您好,欢迎访问三七文档
当前位置:首页 > 电子/通信 > 数据通信与网络 > Web-2.0搜索引擎反作弊技术研究
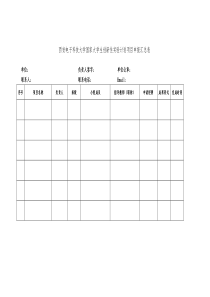
Web2.0搜索引擎反作弊技术研究摘要:概述web2.0的基本含义和主要特征,并分析在web2.0下常见的网页作弊方法,博客作弊、点评作弊、微博作弊和sns作弊等,提出反作弊的3种模型——信任传播模型、不信任传播模型和异常发现模型。最后提出一个基于人工手段和技术手段相结合的综合搜索引擎反作弊框架系统。关键词:web2.0;反作弊;搜索引擎中国分类号:tn919.5文献标识码:a文章编号10053824(2013)010019030引言web2.0时代出现了大量以用户产生内容、内容分享与协作等为主的产品,如博客、图片分享网站、sns网站以及现在很流行的微博等。针对大量的这些web2.0网站,同时也出现了相应的web2.0作弊方法。本文详细分析了web2.0常见的作弊方法和相对应的反作弊技术。1web2.0描述web2.0是相对应web1.0的新一类互联网应用的统称。对于web1.0,用户主要通过浏览器获取相关的信息,而web2.0则更加注重用户的交互作用,用户既是网站内容的发布者同时也是内容的浏览者。所以,在web2.0时代,用户从被动地接受互联网的信息向自动地创造互联网信息发展。web2.0的特征如下[14]。1)众人参与。在web1.0时代,网站的内容主要是由少数的编辑人员定制的,而在web2.0里面,每个人都是内容的提供者。2)以人为中心。在web2.0里面,信息是每个人贡献出来的,每个人都成为互联网信息的来源,因此可以说web2.0里面人是灵魂。3)web2.0的元素。在web2.0里面包含了我们经常使用的服务,如博客、社区、分享服务和微博等。博客和微博是web2.0里面十分重要的元素,因为它们打破了传统的门户网站的信息垄断。4)更加个性化。web2.0是对web1.0的信息来源的拓展,使其更加个性化和多样化。2web2.0网页作弊方法web2.0的以上特征和大量web2.0的网站的出现,使web2.0作弊方法层出不穷。只要操纵搜索引擎的搜索结果就能够带来收益,那么网页作弊的动机就一直存在,尤其在网络营销起着越来越重要的宣传作用的时代更是如此。1)博客作弊。博客评论作弊、作弊博客和trackback作弊构成了常见的3种博客作弊。作弊博客是作弊者申请博客空间,而写作的博客内容是用来诱导搜索引擎转到希望提升排名的网站或者营销的网页,由于这种作弊手段成本较低,使之成为比较流行的作弊方式。博客评论作弊是博客主发布内容后,往往允许读者发布评论,有些作弊者利用这一点,在评论博客发布大量的推广产品的信息和链接。2)点评作弊。目前很多网站允许商品使用者对所消费的商品或者服务做出评价,典型的例子是“淘宝网”和“京东网”等电子商务网站。这为作弊者打开了另外一条作弊通道:作弊者要么在评论里面加入与所评商品无关的广告或者链接,要么提供虚假的点评,比如对较差的产品给予较高的评价以此来打击竞争对手。3)sns作弊。随着facebook和人人网等sns平台的日益流行,在sns平台上作弊也逐渐地发展起来。一种典型的sns作弊手段是用户个人信息描述作弊。作弊者建立一个虚假的个人信息描述,在描述部分利用色情等信息吸引他人,并诱导其他用户点击其推广链接或者向一些用户群组发送广告信息等。4)微博作弊。微博是个人信息发布平台,以信息发布及时性吸引大量的用户,象目前流行的新浪微博和腾讯微博等都拥有很大的用户群。作弊者也利用这些平台来作弊,一个十分典型的作弊方式是:作弊者大量关注他人微博,很多人出于礼貌也会将其加入关注者,在作弊者拥有一定量的关注者后,作弊者会发布广告信息,这些广告信息就会出现在其关注者阅读列表中,以达到营销的目的。3web2.0搜索引擎反作弊技术如上所述,在web2.0时代,搜索引擎作弊手段层出不穷,作为应对方的搜索引擎,也应相应地调整技术思路,不断有针对性地提出反作弊技术方案,而纯粹的技术手段目前是无法彻底解决作弊问题的,所以本文提出了将人工手段和技术手段相结合的反作弊技术方案。从基本的思路看,本文将反作弊手段大致分为信任传播模型、不信任传播模型和异常发现模型。前2种模型可以进一步抽象成“链接分析”传播模型,核心思想是根据人工确定的白名单或者黑名单再由链接关系推导出其他网页是否有问题[5]。异常发现模型也是一个高度抽象的算法框架模型,核心思想是作弊网页必定有异于正常网页的特征,制定具体的算法流程找到一些作弊的网页集合,分析出异常特征,然后利用这些异常特征来识别作弊网页。3.1信任传播模型图1给出了信任传播模型的示意图。基本思路:在海量的网页数据中,通过人工或者一定的技术手段筛选出一定不会作弊的网页组成白名单,赋予这些白名单中的网页较高的信任度分值,其他网页是否作弊要根据与白名单中网页的链接关系来确定。白名单中的网页将根据链接关系把信任分值传播开去,如果某个节点的信任度分值高于一定的阈值,则认为该网页没问题。3.2不信任传播模型图2给出了一个不信任传播模型的示意图,其与信任传播模型是相似的,最大的不同在于,初始页面子集是存在作弊行为的网页集合。赋予黑名单页面节点不信任分值,通过链接关系将这种不信任关系传播开去,如果最后页面节点的不信任分值大于设定的阈值,则认为是作弊网页。3.3异常发现模型异常发现模型具体又可以划分为2个子模型,这2个子模型从不同的角度判断异常网页,一种考虑角度比较直观,即直接从作弊网页包含的特征来构建算法(如图3所示);另一种角度则认为不正常的网页即作弊网页,通过统计等手段分析正常网页应该具备哪些特征,如果网页不具备这些特征,则认为是作弊网页。本文前述提出的3种反作弊模型是从技术手段进行反作弊的,而事实上目前纯粹的技术手段无法彻底解决作弊问题,必须将技术手段和人工手段相结合,才能取得较好的反作弊效果。一个有效的搜索引擎反作弊系统应该是一个综合系统,有机融合人工因素、通用技术手段和专用技术手段。通用技术手段对于可能新出现的作弊手法有一定的预防能力,人工手段和技术手段有很强的互补性,可以在新的作弊方式一出现就被人发现,可以看作是针对作弊进行时的预防措施。图4给出了一个综合反作弊系统的框架,用户可以在上网浏览网页时随时举报作弊网页,比如google推出了浏览器插件来方便用户举报,搜索引擎公司也有专门的部门来审核并主动发现可疑的页面,经过审查后的网页可以放入白名单或者黑名单中。通用的反作弊方法大体有两类:一种从黑名单出发,根据链接关系找出哪些是有问题的网页;另外一种是从白名单出发,找出哪些是没有问题的网页,两者显然有互补的关系,通过两者的搭配可以形成有效的通用反作弊屏障。这种通用方法的好处是具有预防性,如果出现新的作弊方式,只要作弊网页需要通过链接关系进行操纵,那么通用方法就能起到一定的作用。但正因为通用方法的通用性,其反作弊思路没有很好的针对性,对一些特殊的作弊手段不能很好的发现。此时,针对特殊作弊手段的方法就形成了第三道屏障,即搜索公司针对一些具体的作弊方法采取专门的技术手段来进行识别,因为有针对性,所以效果好。综上所述,这几种反作弊方法是有互补关系的,有效融合三者才能获得较好的反作弊效果。目前,纯粹利用技术手段还无法彻底解决作弊问题,必须将人工手段和技术手段相结合才能取得较好的反作弊效果。本文针对目前web2.0里面常见的网页作弊方法进行了分析,并提出了一个综合的反作弊系统,具有一定的使用价值和参考价值。参考文献:[1]bencza,biroi,csaloganyk,etal.detectingnepotisticlinksbylanguagemodeldisagreement[c]//proceedingsofthe15thinternationalconferenceonworldwideweb.newyork:ny,2006:930940.[2]wubn,davisonbd.identifyinglinkspamfarmpages[eb/ol].(20050830)[20120720].http://[3]gyongyiz,molinag.webspamtaxonomy[c]//infirstinternationalworkshoponadversarialinformationretrievalontheweb.chiba:[s.n.],2005:1014.[4]fetterlyd.manassem,najorkm.spam,damnspam,andstatistics:usingstatisticalanalysistolocatespamwebpages[c]//proceedingsofthe7thinternationalworkshoponthewebanddatabases:colocatedwithacmsigmod/pods.newyork:ny,2004:16.[5]张俊林.这就是搜索引擎核心技术详解[m].北京:电子工业出版社,2012.(责任编辑郭毅)
 三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 扫描二维码
扫描二维码







 dushen1982
dushen1982
本文标题:Web-2.0搜索引擎反作弊技术研究
链接地址:https://www.777doc.com/doc-7786274 .html