您好,欢迎访问三七文档
当前位置:首页 > 商业/管理/HR > 管理学资料 > 数据挖掘在实际生活中的应用
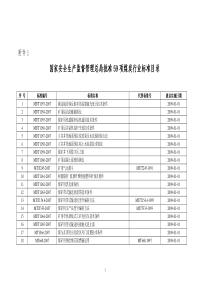
郑重声明:这是我们小组全体成员的集体原创劳动成果,仅供参考,未经允许严禁任何人窃取数据挖掘在学生学习成绩分析中的应用数据挖掘在学生学习成绩中的应用小组成员:说明由于我们小组分析的是上一学年我们计商两个班级的学习成绩与奖学金获得情况,因此涉及到了学生的一些个人信息。我们小组全体成员一致承诺:我们获得的数据(通过辅导员老师获得)仅用于本门课程的数据分析所用,对大家的姓名、学号、成绩等敏感信息已做过处理,保证大家的隐私不被泄露。希望各位能够予以理解!选题背景近年来,随着高校的不断扩招,学生人数大幅增加,给高校学生管理、教学工作带来了严峻考验。传统的教学管理手段已经不能满足高校的快速发展。现阶段许多高校对学生的成绩、学生的信息基本还停留在传统的、简单的数据库管理和查询阶段,不能发挥其应有的作用。就以学生成绩为例,教师对学生的成绩知识做一个简单的优、良、中、差的考核,并不考虑影响学生学习成绩的因素,有些可能是主观因素,有些可能是客观因素。如果某些客观因素比如学习环境、师资力量等不能很好地解决,将严重影响学生的学习成绩,制约学生的发展,而且严重阻碍了学校教育教学发展的脚步。因此,通过数据挖掘等技术理性的分析学生成绩等关键信息,提高教学质量与水平,是广大师生最关心的问题之一。数据挖掘数据挖掘又称为数据库中的知识发现(KDD),是从大量数据中寻找其规律的技术,是统计学、数据库技术和人工智能技术的综合。数据挖掘的任务是从大量的数据中发现对决策有用的知识,发现数据特性以及数据之间的关系。利用贝叶斯分类器分析奖学金概率问题奖学金作为一种激励机制,在人才培养过程中发挥非常重要的导向作用,其目的是为了引导和鼓励学生刻苦学习、奋发向上,促进学生全面素质提高和个性健康发展。为了了解我们计商两个班级上一学年奖学金获得情况,进而考评上一学年我们电子商务系教学成果以及各位同学的学习成绩情况,我们小组利用贝郑重声明:这是我们小组全体成员的集体原创劳动成果,仅供参考,未经允许严禁任何人窃取数据挖掘在学生学习成绩分析中的应用叶斯分类器的方法进行了分析。贝叶斯分类器的分类原理:贝叶斯分类器的分类原理是通过某对象的先验概率,利用贝叶斯公式计算出其后验概率,即该对象属于某一类的概率,选择具有最大后验概率的类作为该对象所属的类。贝叶斯公式:p(X,Y)=p(Y|X)p(X)=p(X|Y)p(Y)变换式:)()()|()|(XpYpYXpXYp其中,X和Y在分类中可以分别表示样本的属性集合类别。p(X,Y)表示他们的联合概率,p(X|Y)和p(Y|X)表示条件概率,p(Y|X)是后验概率,p(Y)称为Y的先验概率。已知通过辅导员老师获得2012-2013学年计商两个班级学生奖学金获得情况统计数据如表1和表2所示:表1A1班奖学金获得情况郑重声明:这是我们小组全体成员的集体原创劳动成果,仅供参考,未经允许严禁任何人窃取数据挖掘在学生学习成绩分析中的应用表2A2班奖学金获得情况已知A1班总人数39,由表1可看出获得奖学金人数为22,获得奖学金的概率约为0.56已知A2班总人数36,由表2可看出获得奖学金人数16,获得奖学金的概率约为0.44A1、A2两个班级总人数为75,奖学金获得者38人,其中A1班占奖学金获得者的比例为58%,A2班占奖学金获得者总人数的比例为42%。.根据以上数据可以得到奖学金获得概率及获奖人数占两个班级获奖总人数的比例,如表3所示:班级奖学金概率获奖人数占两个班级获奖总人数的比例10计商A10.5658%10计商A20.4442%表3奖学金获得概率及所占比例通过以上数据,我们解决以下两个问题:(1)随机从两个班级中选出一个学生是奖学金获得者的概率是多少?(2)随机从两个班级中选出一个学生,已知该学生是奖学金获得者,则此学生来自哪个班级的可能性最大?假设X表示“选出的一个学生是奖学金获得者”,Y=i,(i=10计商A1,10计商A2)表示“选出的学生是来自班级i”,则问题就转换为求解p(X)与p(Y=i|X)。郑重声明:这是我们小组全体成员的集体原创劳动成果,仅供参考,未经允许严禁任何人窃取数据挖掘在学生学习成绩分析中的应用由表3得到后验概率为:P(X|Y=10计商A1)=0.56,P(X|Y=10计商A2)=0.44先验概率为:P(Y=10计商A1)=58%,P(Y=10计商A2)=42%由全概率计算公式得出:P(X)=P(X|Y=10计商A1)P(Y=10计商A1)+P(X|Y=10计商A2)P(Y=10计商A2)=0.56*0.58+0.44*0.42=0.3248+0.1848=0.5096因此,随机从两个班级中选出一个学生是奖学金获得者的概率是0.5096。下面我们求解p(Y=i|X),根据贝叶斯定理可得:)()()|()|(XpiYpiYXpXiYp①由公式①可以计算出该获奖学生来自10计商A1班级的概率为:)()110()110|()|110(XpAYpAYXpXAYp计商计商计商64.05096.058.0*56.0同理可得,该获奖学生来自10计商A2班级的概率为:)()210()210|()|210(XpAYpAYXpXAYp计商计商计商36.05096.042.0*44.0通过以上分析计算不难得出结论:随机从两个班级中选出一个学生,已知该学生是奖学金获得者,则此学生来自10计商A1班级的可能性最大。聚类分析中的k-means算法在学生奖学金等级划分中的应用k-means算法是常见的基于划分的聚类方法,其中相异度基于对象与类中心(簇中心)的距离计算,与簇中心距离最近的对象可以划分为一个簇。此算法的目标是每个对象与簇中心距离的平方和最小。根据对奖学金获得者学生的学习情况分析可知:获奖等级与该学生平时去图书馆的次数、平时上课迟到次数、上课座位前后、参加竞赛次数、宿舍评分等因素有关。比如,图书馆能为同学们提供安静的、舒适的学习环境,同时能够提高学生学习的自觉性,因此常去图书馆的同学学习成绩一般都比很少去图书馆学生郑重声明:这是我们小组全体成员的集体原创劳动成果,仅供参考,未经允许严禁任何人窃取数据挖掘在学生学习成绩分析中的应用学习成绩要好,相应的拿到奖学金的概率越大,拿到奖学金的等级也越高。其他因素类似,这里不一一详细用文字来描述。首先定义五个变量(每学期均按16周计算):1x:一学期去图书馆次数(每周按七天计算,上限112次)2x:一学期迟到次数(每周按四天计算,上限64次)3x:一学期座位在前排次数(每周按四天计算,上限64次)4x:一学期参加各类竞赛次数(每学期上限5次)5x:一学期宿舍平均评分(上限20分)根据奖学金获得者获奖等级情况分析可知,能够拿到一等及以上奖学金的指标为:1x:96-112;2x:0-2;3x:60-64;4x:3-5;5x:19.5-20学生1x2x3x4x5x1112160119.52106364219.5334348119.5485264119590162018.5656139120727452118.5873053118910719117表4根据不同获奖等级选取的学生信息在以上给定的9个样本中选择3个样本:1号样本代表能够拿到一等及以上奖学金6号样本代表能够拿到非一等及以上奖学金9号样本代表不能够拿到奖学金计算每一个样本与这三个样本的距离:郑重声明:这是我们小组全体成员的集体原创劳动成果,仅供参考,未经允许严禁任何人窃取数据挖掘在学生学习成绩分析中的应用135.195.19126064131121061,2d5.78205.1912396413561066,2d5.148175.1912196473101069,2d925.195.1911604813112341,3d5.33205.191139481356346,3d5.59175.191119487310349,3d5.325.191911606412112851,4d5620191139641256856,4d12717191119647210859,4d265.195.1810606211112901,5d5.59205.181039621156906,5d5.131175.181019627110909,5d975.195.1811605214112271,7d5.46205.181139527410276,7d5.54175.181119527410279,7d郑重声明:这是我们小组全体成员的集体原创劳动成果,仅供参考,未经允许严禁任何人窃取数据挖掘在学生学习成绩分析中的应用5.485.191811605310112731,8d13420181139531056736,8d10517181119537010739,8d第一次聚类结果:学生与学生1的距离与学生6的距离与学生9的距离10--21378.5148.539233.559.5432.55612752659.5131.56-0-79746.554.5848.5341059--0表5第一次聚类结果把以上距离最小的样本归入相应的类:根据第一次聚类结果数据不难看出,样本1、2、4、5、8几组数据比较接近,样本3、6、7数据比较接近。因此,将以上样本划分为三类。第一类由样本1、2、4、5、8组成,第二类由样本3、6、7组成,第三类由样本9组成。第一类:1x=(112+106+85+90+73)/5=93.22x=(1+3+2+1+0)/5=1.43x=(60+64+64+62+53)/5=60.64x=(1+2+1+0+1)/5=15x=(19.5+19.5+19+18.5+18)/5=18.9郑重声明:这是我们小组全体成员的集体原创劳动成果,仅供参考,未经允许严禁任何人窃取数据挖掘在学生学习成绩分析中的应用第二类:1x=(34+56+27)/3=392x=(3+1+4)/3=2.73x=(48+39+52)/3=46.34x=(1+1+1)/3=15x=(19.5+20+18.5)/3=19.3第三类:1x=102x=73x=194x=15x=17新的样本中心:新中心1x2x3x4x5x第一类93.21.460.6118.9第二类392.746.3119.3第三类10719117表6新的样本中心第二次聚类:学生2与新样本的距离:4.189.185.19116.60644.132.931061,2d2.833.195.19113.46647.23391062,2d郑重声明:这是我们小组全体成员的集体原创劳动成果,仅供参考,未经允许严禁任何人窃取数据挖掘在学生学习成绩分析中的应用5.143175.1911196477101063,2d学生3与新样本的距离:749.185.19116.60484.132.93341,3d2.73.195.19113.46487.2339342,3d5.59175.191119487310343,3d学生4与新样本的距离:3.129.1819116.60644.122.93851,4d4.643.1919113.46647.2239852,4d12717191119647210853,4d学生5与新样本的距离:4.69.185.18106.60624.112.93901,5d2.703.195.18103.46627.
 三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 扫描二维码
扫描二维码







 haogogo
haogogo
本文标题:数据挖掘在实际生活中的应用
链接地址:https://www.777doc.com/doc-1858436 .html