您好,欢迎访问三七文档
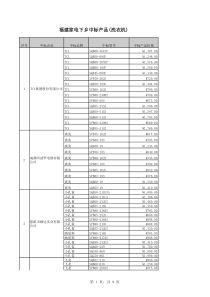
关于亚细胞定位知识探讨贺位皇生物信息平台2016.09.02主要内容亚细胞定位知识背景定位要点软件使用展望未来生物体细胞是一个高度有序的结构,胞内根据空间分布和功能不同,可以分成不同细胞器或细胞区域,如细胞核、高尔基体、内质网、线粒体、胞浆和细胞膜等。蛋白质在核糖体中合成后经蛋白质分选信号引导后被转运到特定的细胞器中,部分蛋白质则被分泌到细胞外或留在细胞质中,只有转运到正确的部位才能参与细胞的各种生命活动,所以蛋白质的亚细胞定位信息日益重要。•●传统法●生信法亚细胞分离绿色荧光蛋白同位素亲和标签质谱抗体昂贵耗时重复性差数据通量大根据已知数据可对未知做预测数据增长,不断验证完善亚细胞定位知识背景亚细胞定位原理:蛋白质的氨基酸序列以及亚细胞的特异结构特征,提取特征参数或描述符,通过算法比较查询序列中所包含的特征参数与各类被定位蛋白质的相似度,从而对蛋白质的亚细胞定位作出判断。1999年chou根据蛋白质的亚细胞位置,把蛋白质细分为12类(然而无细胞壁?),是后来的主流分类方式。(SWISS-PROT)2002年亚细胞数据库蛋白分选信号:一种信号序列,决定特定蛋白的转运方向,可被细胞器上的分选受体特异性识别。N端分选信息包括信息肽、线粒体引导肽、叶绿体运输肽和核定位肽等。(局限性)氨基酸组成:将20种氨基酸在蛋白质序列中出现的频率抽取出来作为一个20维的向量来预测蛋白质亚细胞定位,随后也把氨基酸残基的特性结合起来。(忽略了蛋白质全部氨基酸序列及蛋白结构信息)其他特征信息:除了常用特征信息外,还加了功能域组成、结构、go注释等(局限性)几种信息的结合:将多种向量结合起来已成为最普遍的一种方法,Gardy等提出的PSORT-B将氨基酸组成、N端分选信等一起作为特征信息来预测细胞定位。亚细胞定位要点“if-then”规则:Nakai等最先使用构建了一个专家系统来进行预测相关性分析:蛋白质的细胞定位和氨基酸的组成的相关性机器学习法:根据已有的生物数据发现有意义的生物规律,通过推理、模型匹配从中自动学习知识和理论。包括神经网络、隐Markov模型。趋势:将多种算法结合起来,用不同算法处理不同特征信息或综合多种算法进行多级预测,都取得更高精确度。Fujiwara等用神经网络方法描述蛋白序列的氨基酸组成,用隐马可夫模型描述残基序列取得在植物中86%、非植物91%的预测精度。亚细胞定位预测数据集的建立:抽取高质量亚细胞定位数据集并分为训练集和测试集抽取特征信息向量作出预测选择合适算法,依据特征信息向量作出预测用检验数据集对结果进行评价预测性能评估性能评估:留一交叉验证,每次取数据集中一条蛋白序列做测试样品,而剩余蛋白序列作为训练集对测试样本的亚细胞进行定位(取平均值做总的分类性能)MCC:Mattthe相关系数(Matthewcorrelationcoefficient):综合评价指标,反应系统的综合评价能力Sensitivity:敏感性,代表蛋白数据集中每一小类的预测准确率特异性:集中体现了蛋白数据集中的每一小类预测结果的可信程度。理想值:均为1TP:真阳性数TN:真阴性数目FP:假阳性数目FN:假阴性数目成功率:N为蛋白序列总数性能评估流程上诉各种蛋白定位计算的参考网址:=paperuri%3A%288bf4deb6418a85f9a5279ea794c4ce8d%29&filter=sc_long_sign&tn=SE_xueshusource_2kduw22v&sc_vurl=http%3A%2F%2F=utf-8&sc_us=14325412026675279602=GkAlGgBeBFdbe5-gEJO-Pvt1xcjbj0bCuTLJTcsGHfcDTlFgQBgwu28e43GCfYZdso0j_tHAJUIKsrPHAG47J4fvcIkBJU_2cI8c_35xW9G在线软件使用真菌阈值:实验经验值(默认14)在线软件使用结果展示GeneID位点位置:分数蛋白ID文献结果展示K近邻法:对于一个待分类的测试样本,在多维空间中寻找与未知样本最相似的K样本,及K个最近邻居,待测样本则被判定为K个样品中绝大多数样本所属的类别,因为仅仅取决少量相邻的样本,因此这种算法能有效处理样品不均衡问题,展望未来亚细胞定位的生物信息学研究作为亚细胞蛋白组学实验做了研究补充,但是从生物学的角度来看:目前各数据库的亚细胞定位注释不统一,给大规模分析带来困难对分选信号的理解不透彻有些蛋白质在细胞内并不是固定在某一个亚细胞内,如:转录因子,具有流动性,这类蛋白研究较少。对蛋白质功能和亚细胞定位之间关系理解不够深入。
 三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 扫描二维码
扫描二维码








 unheroooo
unheroooo
本文标题:亚细胞定位
链接地址:https://www.777doc.com/doc-1872192 .html