您好,欢迎访问三七文档
当前位置:首页 > 电子/通信 > 数据通信与网络 > 第一章高等计算机的核心技术并行处理
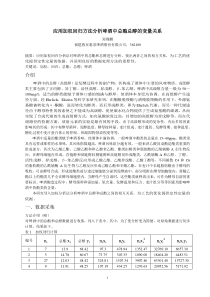
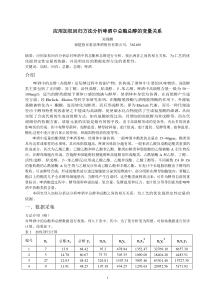
高等计算机系统结构高等计算机系统结构第一章高等计算机的核心技术——并行处理第二章加速比性能模型与可扩展性分析第三章互连与通信第四章划分与调度第五章并行存储器系统第六章CacheCoherence第七章MemoryConsistency第八章指令级并行处理第一章高等计算机的核心技术——并行处理1.1什么是并行处理1.1.1并行处理定义1.1.2并行性级别1.2为什么要开发并行处理技术1.3并行处理计算机结构沿革1.4其它并行处理计算机技术1.1什么是并行处理1.1.1并行处理定义并行处理是指同时对多个任务或多条指令、或同时对多个数据项进行处理。完成此项处理的计算机系统称为并行处理计算机系统。同时性(simultaneity)——两个或多个事件在同一时刻发生。并发性(concurrency)——两个或多个事件在同一时间间隔内发生。流水特性(pipelining)——在一个重叠的时间内所发生的流水事件。1.1.2并行性级别粒度(granularity):衡量一个软件进程的计算量的度量。最简单的是指此程序段中的指令数。分细、中、粗三种。按粒度的不同,并行性级别可以分为指令级、循环级、过程级、子程序级和作业级等不同的层次。它们对应的计算粒度可以为细粒度、中粒度和粗粒度。1.指令级并行典型细粒度,一般少于20条指令。借助优化编译器自动检测并行性,将源代码变成运行时系统能识别的并行形式。2.循环级并行典型循环含少于500条指令,由于有些循环操作在连续迭代中并不相关,易于向量化,是在并行机或向量机上运行的最优程序结构。递归循环的并行化比较困难。向量处理由优化编译器在循环级开发,仍属于细粒度计算。3.过程级并行中粒度并行,指令少于2000条,分析过程间的并行性比细粒度要困难。有时需要重新设计程序,并要编译器的支持。SPMD、多任务处理属于这一层。4.子程序级并行(粗)中粒度并行,几千条指令,常在messagepassing多计算机上以SPMD或MPMD方式执行。并行性主要由算法设计人员与程序员开发。5.作业级并行粗粒度并行,数万条指令,常由加载程序和操作系统处理这类并行性,靠算法有效性来保证。一般说来:细粒度:用并行化或向量化编译器来开发,共享变量通信支持。中粒度:靠程序员和编译器一起开发,共享变量通信。粗粒度:取决于操作系统和算法的效率,消息传递通信。例子:共享存储型多处理机上执行:L1:DO10I=1,NL2:A(I)=B(I)+C(I)L3:10ContinueL4:SUM=0L5:DO20J=1,NL6:SUM=SUM+A(J)L7:20Continue假设:L2,L4,L6每行要用一个机器周期。L1,L3,L5,L7所需时间可以忽略。所有数组已经装入主存,程序已装入Cache中(取指令和加载数据可以忽略不计)。忽略总线争用或存储器访问冲突。上面的程序实际上把数组B(I)和C(I)相加,最后得到一个总和。共享存储多处理机结构如下图:P1P2……Pm系统互连I/OSM1……SMm处理机共享存储器在单机系统中,2N个周期可以完成上述的操作:I循环中执行N次独立迭代需要N个周期;J循环中执行N次递归迭代也需要N个周期。在共享存储型的多处理机系统上:假设有M台处理机,可以将循环分成M段,每段有L=N/M个元素。代码如下所示:Doallk=1,MDo10I=L(k-1)+1,kLA(I)=B(I)+C(I)10ContinueSUM(k)=0Do20J=1,LSUM(k)=SUM(k)+A(L(k-1)+J)20ContinueEndall分段的I循环可以在L个周期中完成;分段的J循环在L个周期中产生M个部分和。所以产生所有的M个部分和共需要2L个周期(还需要将这些部分和合并)。假设经过共享存储器的处理机之间的每次通信操作需要k个周期。设N=32,M=8,则经过2L(即8个周期)后在8台处理机上各有一个部分和,还需要8个数相加。为了合并部分和,可以设计一个l层的二进制加法树,其中l=log2M,加法树用l(k+1)个周期从树叶到树根顺序合并M个部分和,如下:二进制加法树:所以,多处理机系统需要才能得到最终的结果。假定数组中有N=220个元素,顺序执行需要2N=221个机器周期,假设机器间通信的开销平均值为k=200个周期,则在M=256台处理机的并行执行需要:第一章高等计算机的核心技术——并行处理1.1什么是并行处理1.2为什么要开发并行处理技术1.3并行处理计算机结构沿革1.4其它并行处理计算机技术1.2为什么要开发并行处理技术对单用户,可以提高加速比(SpeedupOriented);对多用户,可以提高吞吐率(ThroughputOriented).对不同的需求我们可以做需求分析如下:1.天气预报1990年10次台风登陆,福建、浙江两省损失79亿元,死亡950余人。天气预报模式为非线性偏微分方程,预报台风暴雨过程,计算量为1014—1016次浮点运算,需要10GFlops—100GFlops的巨型机。用途:局部灾害性天气预报。2.石油工业地震勘探资料处理油藏数值模拟测井资料处理地震勘探由数据采集、数据处理和资料解释三阶段组成。目前采用的三维地震勘探比较精确的反映地下情况,但数据量大,处理周期长。100平方公里的三维勘探面积,道距25米,60次覆盖,6秒长记录,2毫秒采样,一共采集2.881010个数据,约为116GB。叠加后数据为4.8108个数据。用二维叠前深度偏移方法精确的产生地下深度图像,需要进行251012FLOP,采用100MFLOPs机器计算250天,1GFLOPs机计算25天,10GFLOPs机器35分。考虑到机器持续速度常常是峰值速度的10-30%,所以需要100GFlops的机器。CrayT932/32约为60GFLOPs。3.航空航天研究三维翼型对飞机性能的影响。数值模拟用时间相关法解Navier-Stoker方程,网格分点为1204050,需内存160MB,6亿计算机上解12小时,如果在数分钟内完成设计,则需要千亿次计算机。4.重大挑战性课题需求(图3.5)计算空气动力学:千亿次/秒(1011)图像处理:百亿次/秒(1010)AI:万亿次/秒(1012)5.核武器核爆炸数值模拟,推断出不同结构与不同条件下核装置的能量释放效应。压力:几百万大气压温度:几千万摄氏度能量在秒级内释放出来。设计一个核武器型号,从模型规律、调整各种参数到优选,需计算成百上千次核试验。LosAlamos实验室要求计算一个模型的上限为8-10小时。千万次机上算椭球程序的计算模型需要40-60CPU小时。二维计算,每方向上网格点数取100,二维计算是一维的200倍,三维是一维的33000倍。若每维设1000网格点,则三维计算是一维的几十万倍之多。此时对主存储器容量要数十、数百亿字单元(64位)。另外还有I/O能力的要求,可视化图形输出。6.解决方案只有开发并行处理技术才能满足要求:3Tperformance:TeraflopsofComputingPowerTerabyteofMainMemoryTerabyte/sofI/Obandwidth第一章高等计算机的核心技术——并行处理1.1什么是并行处理1.2为什么要开发并行处理技术1.3并行处理计算机结构沿革1.3.1向量机与多向量机1.3.2SIMD计算机1.3.3Shared-MemoryMultiprocessors1.3.4Distributed-MemoryMultiprocessors1.3.5四类实用的并行系统1.4其它并行处理计算机技术1.3并行处理计算机结构沿革1.3.1向量机与多向量机向量机的结构如下图:ScalarFunctionalpipelinesScalarControlunitscalarprocessorscalarinstructionMainMemory(Programanddata)MassStorageHostComputerI/O(user)VectorControlunitvectorregistersvectorprocessorcontrolVectorFunctionalpipelinesVectorFunctionalpipelines……vectorinstruction程序和数据从Host进入主机指令先在Scalarcontrolunit译码,如是标量或控制操作指令,则在标量功能流水部件种执行。如果是向量指令,则进入向量控制部件。register-to-register:CrayseriesFujitsuVP2000seriesmemory-to-memory:Cyber205向量化。多向量机发展过程:CDC7600(CDC,1970)CDCCyber205(Levine,1982)Memory-MemoryCray1(Russell,1978)register-registerETA10(ETA,Inc,1989)CrayY-MPCrayResearch1989FujitsuNECHitachiModelsCrayMPPCrayResearch1993其中:CrayY-MP,C90:Y-MP有2,4,8个处理器,而C90有16个处理单元(PE),处理速度16GFlops。ConvexC3800family:8个处理器,4GB主存储器,Rerkperformance为2GFlops。1.3.2SIMD计算机SIMD计算机的结构如下图:ControlUnitProc0Mem0Proc1Mem1……ProcN-1MemN-1PE0PE1PEN-1InterConnectionNetworkMasParMP-1:可有1024,4096,…,16384个处理器。在16KPEs,32位整数运算,16KB局部存储器模块的配置下,可达26000MIPS,单精度浮点运算1.5GFlops,双精度浮点运算650MFlops。CM-2:65536个处理单元,1Mbit/PE。峰值速率为28GFlops,持续速率5.6GFlops。SIMD计算机发展过程图如下:IlliacIV(1968)GoodYearMPP(1980)BSP(1982)MasParMP1(1990)IBMGF/11(1985)DAP610(AMT,Inc.1987)CM2(1990)CM5(1991)1.3.3Shared-MemoryMultiprocessorsUMA(Uniform-memory-access)model:物理存储器被所有处理机均匀共享,所有处理机对所有存储字具有相同的存取时间。P0I/OP1SM1……PnSMnInterConnectionNetwork(Bus、Crossbar、MultistageNetwork)……处理器共享存储器NUMA(NonUniform-memory-access)model:访问时间随存储字的位置不同而变化。P1……PnLMnInter-ConnectionNetwork……LM1P2LM2……COMA(Cache-onlymemoryarchitecture):只用高速缓存的多处理机远程高速缓存访问则借助于分布高速缓存目录进行。PDInterConnectionNetwork……distributedcachedirectoriesCPDCPDCKendallSquareResearch’sKSR-1Shared-MemoryMultiprocessors发展过程如下:Cmmp(cmu,1972)IllinoisCedar(1987)UltraComputerNYU(1983)FujitsuVPP500(1992)IBMRP3(1985)BBNButterfly(1989)stanford/Dash(1992)KSR-1(1990)1.3.4Distributed-MemoryMultiprocessorsP……Message-passinginterconnectionnetwork(Mesh,ring,tor
 三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 扫描二维码
扫描二维码





 ypxmaomao
ypxmaomao
本文标题:第一章高等计算机的核心技术并行处理
链接地址:https://www.777doc.com/doc-2116649 .html