您好,欢迎访问三七文档
当前位置:首页 > 商业/管理/HR > 质量控制/管理 > 基于人工神经网络的文本分类的研究与实现
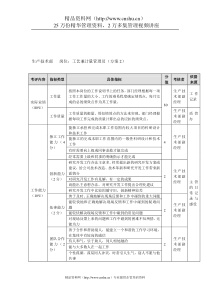
基于人工神经网络的文本分类的研究与实现摘要:本文研究实现了文本分类过程中的主要技术:中文分词、特征选择、文本向量化和分类器构造,并在广泛研究现有的文本自动分类的基础上,利用BP神经网络的联想记忆和预测能力,构建了基于BP神经网络的分类器。主要设计思路如下:首先对所有文本进行分词、词频统计,并生成各文本的特征向量,然后利用TFIDF算法优化特征向量,对特征空间做降维处理;最后建立BP神经网络文本分类器并初始化网络,用训练语料库训练BP文本分类器,直到算法迭代结束,网络的训练满足一定的收敛条件。关键词文本分类;特征选择;BP神经网络BasedonartificialneuralnetworkintheresearchandimplementationoftextcategorizationLiFei,JIAOYue(SchoolofInformationTechnologyandCommunication,QufuNormalUniversity,Rizhao276826,China)AbstractThisresearchachievesthemaintechnologyamongtheprocessoftextclassification,whichincludeChineseWordSegmentation,FeatureSelection,thetexttoquantitativeandClassSelection.AndtakingadvantageoftheassociativememoryandpredictionabilityofBPneuralnetwork.WestructuretheclassifierbasedonBPneuralnetworkonaccountoftheextensiveresearchofexistingautomatictextclassification.Maindesignideaisasfollows:Firstly,wecarryonthestatisticsofwordsegmentationandwordfrequencyforalltext,whichgeneratesafeaturevectorofeachtext.ThenreducethedimensionoffeaturespacebytheimprovementoffeaturevectormakinguseofTFIDFarithmetic.Finally,establishtextclassificationofBPneuralnetwork,initializethenetwork,trainBPtextclassificationapplyingthetrainingcorpusuntiltheendoftheiterativealgorithm.Thenetworktrainingmeetscertainconvergenceconditions.Keyword:Textclassification;Featureselection;BPneuralnetwork1引言在过去的几十年中,随着互联网的飞速发展,各种电子文档的急剧增加,如何有效地检索和访问这些庞大的文档资源,已经成为信息系统学科急需解决的重要问题。文本分类就是解决这个问题的工具之一,它是指在给定分类体系下,根据文本内容自动确定文本类别的过程。从数学的角度看,文本分类是一个映射的过程,它将未标明类别的文本映射到已有的类别中。这样,用户不但能方便的浏览文档,而且能够通过限制搜索范围提高搜索效率。目前,文本分类已经被应用在众多领域,包括Internet上的应用、电子邮件分拣中的应用、电子出版社的应用、网络安全中的应用、电话会议中的应用等等[1]。许多网站如Yahoo仍然是通过人工对Web文档进行分类,这大大限制了其索引页面的数目和覆盖范围。可以说研究文本分类有着广泛的应用前景[2]。总之,文本自动分类可节约大量人力和财力,避免人工分类带来的周期长、费用高、效率低等诸多缺陷。2人工神经网络人工神经网络(AneuralNeuralNetwork,ANN)是由大量简单的基本元件——神经元相互连接,通过模拟人的大脑神经处理信息的方式,进行信息并行处理和非线性转换的复杂网络系统。神经网络由于具有多输入多输出的优点,所以实现了数据的并行处理以及自学习能力。前向反馈(BackPropagation,BP)网络和径向基(RadialBasisFunction,RBF)网络是目前技术最成熟,应用最广泛的两种网络[3]。3文本分类器的设计与实现BP神经网络是数据挖掘中的一种常用的技术方法,作者充分发挥BP网络的优势,并针对他的缺点运用新技术进行弥补,构造出一个基于BP神经网络的文本分类器。分类器分为训练和分类两个部分。首先根据自己的需求范围建立专用的分词词典;然后对经过人工分类的文本进行整理,形成训练语料库;利用分词词典对训练语料库和训练样本进行词条切分、词频统计、文本特征提取、词频统计、文本向量化;使用训练样本得出的矩阵作为输入,利用BP网络进行训练,达到满意效果后,得到固定的权值,作为分类知识存储在网络中。分类器训练完毕后,就可以对测试样本进行分类了,分类过程和训练过程大体相似,首先利用分词词典对样本进行词条切分、词频统计、文本特征提取、文本向量化,生成待分类文档的特征向量,由于训练过的网络权值已经固定,可以直接运用它得出分类结果。3.1词条切分文本分词是预处理过程中必不可少的一个操作,因为后续的分类操作需要使用文本中的单词来表征文本。文本分词包括两个主要步骤:第一个是词典的构造,第二个是分词算法的操作。一般选用的汉语词典有十几万词条,如果每次匹配都检索词典内全部词条,效率将会大大降低。为了提高词典的查询速度,文献[4]提出了一种支持首字Hash和标准二分查找的词典数据结构,明显提高了分词效率,优于目前所见的同类算法。因此,本文使用类似于文献[4]中提出的首字Hash思路的二级索引词典结构。将首字的区位码作为标识的数组索引,指向以此字为首的所有词组成的HashMap。汉字的区位码就是GB2312码中的汉字部分。包括单字词在内,词典中的首字有6763个,声明一个大小6763的数组就足够了。分词算法有简单的有复杂的,常见的主要有正向最大匹配、反向最大匹配、双向最大匹配、语言模型方法、最短路径算法等等,本文使用的是正向最大匹配算法。3.2词频统计大多数研究将词频统计放到特征提取后面来做,而本文将词条切分和词频统计整合到一起,这样可以方便实现而且又可以将词频统计的结果应用于下一步的特征值提取,等到特征值提取完毕后,再利用同样的算法进行一次新的词频统计,来作为文本特征向量的依据。实验结果如图1。图3.1文本分类和词频统计的结果3.3特征提取文本分类问题的最大特点和困难是特征空间的高维性和文本向量的稀疏性。最基本的特征选择方法是将一篇文档中出现的全部词集作为这篇文档的特征,但是随着特征空间维数的增大而导致的复杂性使得这种做法几乎是不可取的[5]。所以选择一种有效的特征选择方法对文本实现特征提取是非常有必要的。目前广泛应用的特征选择方法有:文档频率(DF)[6]、互信息(MI)[7]、期望交叉熵[8]等。本文首先利用词频统计得出的结果,结合DF算法,预先设定一个阈值,把度量值小于阈值的那些特征过滤掉,剩下的候选特征作为结果的特征子集。3.4改进的文本向量化大多数分类算法都只适用于离散的数值类型,所以在运用分类算法前,文本向量化是一个非常重要的步骤。本文选用TFIDF算法的一部分思想,将文本中每个单词被看成一个特征项tj,每篇文档被看成由单词组成的向量),...,,(21iniiidddd,在每篇具体文档di中,单词tj)1(nj被赋予一个数值dij,表示tj在该文档中的重要程度,称为tj的权值,即有:jijijidftfd*(3.1))1||log(jjdfDid(3.2)公式(3.1)和(3.2)中,词频(TermFrequency,简称TF)ijtf表示特征项tj在文档di中出现的次数,文档频率(DocumentFrequency,简称DF)jdf指整个训练文档集合中包含特征项tj的文档个数,jidf是特征项tj的反文档频率(InverseDocumentFrequency,简称IDF)[9]。然后利用文档频率和反文档频率得到特征向量。具体步骤如下:特征词集合/文档d1d2单词出现总数A213B224C213D101表3.1特征词在文档中出现的次数E437F213G224文档单词总数151025如表3.1所示,表格中的数字表示特征单词在对应文档中出现的次数,下一步计算p并标准化(将数值映射到-1到1之间,以防止大值特征词对文本特征的控制,当然也可以便于后续的计算)。p的值是特征词在文档中出现次数和文档中总词数的比值,计算结果如表3.2所示。q值得计算利用公式(3.3)。|)Dt||)/D|log((1(3.3)其中其中|D|表示文档总数,|Dt|表示包含特征词t的文档数量,计算结果如表3.3所示。最后将p、q相乘得到每个文档的最终向量表示:p值d1d2A0.08(2/25)0.04B0.080.08C0.080.04D0.040.00E0.160.12F0.080.04G0.080.08表3.2p的值表3.3q的值d1=(0.032,0.032,0.032,0.044,0.064,0.032,0.032)d2=(0.016,0.032,0.016,0.000,0.048,0.016,0.032)3.5BP神经网络的实现BP网络是一种具有三层或者三层以上神经元的神经网络,包括输入层、中间层(隐含层)和输出层。上下层之间实现全连接,而同一层的神经元之间无连接。当一对学习样本提供给输入神经元之后,神经元的激活值(该层神经元的输出值)从输入层经过各隐含层向输出层传播,在输出层的各神经元获得网络的输入响应,然后按照减少网络输出与实际输出之间误差的方向,从输出层反向经过各隐含层回到输入层,从而逐步修正各连接权值,这种算法称为误差反向算法,即BP算法[9]。3.5.1BP网络文本分类步骤经过上面几步的预处理得出文本的特征向量以后,便可应用BP网络对其进行分类了。本文BP网络的拓扑结构如图1所示。图3.2中,X1,X2,…,Xn是BP神经网络的输入值,对应于输入文本的特征权值;Y1,Y2,…,Ym是BP神经网络的预测值,对应于文本类型;wij和wjk为为BP神经网络的权值。在进行文本分类预测前,需要通过训练网络使网络具有联想和预测能力。训练过程包括以下几个步骤[10]。计算q值lnA0.4B0.4C0.4D1.1E0.4F0.4G0.4X1X2XnwjkYmY1wij输入层隐含层输出层图3.2BP神经网络拓扑结构图步骤1:网络初始化。根据系统输入输出序列(X,Y)确定网络输入层结点数n、隐含层节点数l,输出层节点数m,初始化输入层、隐含层和输出层神经元之间的连接权值wij,wjk,初始化隐含层阙值a,输出层阙值b,给定学习速率和神经元激励函数。步骤2:隐含层输出计算。根据输入向量X,输出层和隐含层间连接权值wij以及隐含层阙值a,计算隐含层输出H。n1jjiiijaxwHj=1,2,…,l(3.8)式中,l为隐含层节点数;f为隐含层激励函数,该函数有多种表达式,本章所选函数为:xexf1l)((3.9)步骤3:输出层输出计算。根据隐含层输出H,连接权值wjk和阙值b,计算BP神经网络预测输出O。kjkjJbwHOl1kk=1,2,…,m(3.11)步骤4:误差计算。根据网络预测出O和期望输出Y,计算网络预测误差e。kkkOYek=1,2,…,m(3.12)步骤5:权值更新。根据网络预测误差e更新网络连接权值wij,wjk。kixkjkjJijewixHHw1ij)()1(wj=1,2,…,n;j=1,2,
 三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 扫描二维码
扫描二维码








 小兵油子
小兵油子
本文标题:基于人工神经网络的文本分类的研究与实现
链接地址:https://www.777doc.com/doc-2535525 .html