您好,欢迎访问三七文档
当前位置:首页 > 商业/管理/HR > 管理学资料 > 基于本征正交分解(POD)的PIV数据坏点剔除方法
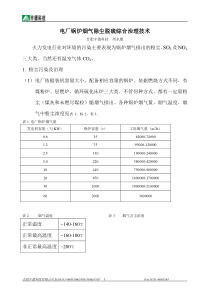
基于本征正交分解(POD)的PIV数据坏点辨识方法摘要:1.引言:粒子图像测速技术是一种基于图像互相关的激光测速技术。在进行PIV实验的过程的由于示踪粒子浓度不均匀、激光强度分布不均、粒子成像质量差等原因容易造成互相关峰值不确定1,出现所谓的“坏点”。最近几年发展起来的3D3CPIV2,3,由于在重构空间粒子场的时候会不可避免的引入虚假粒子,进一步增加了流场中了坏矢量。因此,坏矢量的剔除和重建是PIV数据后处理的一个重要内容。一般通过对比该点误差与周围3*3或5*5邻域内平均误差来确定该点是不是坏点。目前比较通用并且效果很好的是Westerweel和Scarano提出的归一化中值检测方法4(normalizedmediantest)。考虑一个位移矢量0U和其周围33的相邻矢量12345678{,,,,,,,}UUUUUUUU。用mU表示12345678{,,,,,,,}UUUUUUUU的中值,用ir表示残差,定义为iimrUU(i=1,2,…8)。0U的残差用ir的中值mr归一化后得到下面的公式:0*0mmUUrr其中是与流场的平均噪音有关的量,一般设为0.1-0.2pixel。对于平面PIV,*0r的阈值设为24,大于该阈值的点被认为是坏点。其他坏点识别的方法与该方法原理相同,基本上都是基于相邻点的统计特性判断该点的性质。这种方法有缺陷,一是只能用到少量相邻点的值,忽略了流场的全场特性;二是局部相邻点的速度矢量很有可能也是坏点,导致判断的结果不可靠;三是*0r的阈值需要根据流中坏点的多少确定,在实际运用中并不能精确的知道坏点所占的比例。因此,本文作者提出了基于POD的坏点检测方法。该方法对周期性或类周期性流场PIV数据的后处理有很好的效果。本文的结构安排如下:首先在第二节简单的介绍了本征正交分解的原理,推导了POD与流场湍动能的关系;在第三节对流场的误差进行了数值模拟,讨论了误差对POD分解的影响以及详细的介绍了基于POD的坏点剔除方法;一个真实PIV计算出的流场运用该方法进行了坏点剔除并和归一化中值检测方法进行了比较,这在第四节给出;第五节是结论。2.POD原理POD是一种从统计意义上提取流场中主要流动结构的方法,可以实现对复杂非线性系统的线性降维处理。这种方法最早由Lumley(1967年)引入湍流的研究,用于辨识大尺度拟序结构,后来Berkooz5等人对POD方法给出了系统的介绍。POD方法就是要找出和原流场最相似的流动模态5,对于复杂流场这样的流动模态不止一个,于是可以假设流场是一系列POD基模态的线性组合,即:1(,)()()KkkktatΦXUX其中(,)UtX是不同时刻的速度场,()kΦX代表POD的第k阶模态,()kat代表与第k阶模态相关的时间系数。POD的模态满足正交关系:,0,,1,ijijijijΦΦ从数学上可以从下面的公式解出()kΦX:kkkCΦΦ(1)其中C是(,)iUXt和(,)jUXt的两点互相关系数,即(,),(,)ijCUXtUXt。这里我们着重讨论一下特征值k的取值。对于两点互相关矩阵C中的元素Cij有计算公式:((,),(,))((,),(,))*((,),(,))*ijijijiijjiijjUXtUXtKCUXtUXtUXtUXtKK一般都是用速度的脉动场进行POD分解的,式中(,)tUX代表的是速度脉动。当拥有足够多的不同时刻流场的数据时,不论是对于classicalPOD还是snapshotPOD,iiK都代表流场的湍动能,而且不会有太大的变化,即在Cij的公式中分母基本都相同,这也正是可以直接用Kij替换Cij带入公式8计算的原因。因此,当对k归一化后,特征值k就是一个与该阶模态的湍动能有关的量。k越大,该阶模态所含的湍动能越多,也就是说POD可以按能量提取流场的主要特征。详细的介绍可以参考文献5。3.误差模拟分析3.1模拟方法评价PIV计算结果好坏的一个重要指标就是坏点所占的百分比Q。一般来说,在PIV中存在两类误差。一类是以单个点形式出现的错误矢量,这类误差大小和分布都带有明显的随机性,主要是由于查询窗内互相关信噪比太低峰值不明确造成的;另一类误差成片形式出现,通常有好几个误差向量集中在同一个区域,这种误差很有可能是由于图像在这一区域粒子太少或质量太差造成的。设误差向量的连通区域的大小为errn,当1errn时表示单个误差矢量,2errn表示两个误差矢量连在一起,以此类推。为了得到errn的分布,对一个PIV计算出来的真实的流场用归一化中值检测方法检识别坏点,然后统计坏点连通区域的分布。得到图1中的统计结果。从直方图中可以看出单个误差矢量出现的概率最高,连通区域越大出现的概率越小。对数据进行高斯拟合得到光滑的拟合曲线:22()0.3439exp()(1,2,3...)3.815errerrerrnfnn()errfn代表该类型误差占所有向量的比例。误差的大小在查询窗内随机分布。当流场误差总的个数确定后,按该概率密度函计算不同类型的误差并添加到基本流场之上,完成误差场的模拟。图1误差向量连通区域errn的概率密度分布图2Q=3%时模拟结果基本流场取自一套平滑过后的圆柱扰流的平面PIV数据。该数据在北京航空航天大学低速水槽完成,自由来流速度为35mm/s。圆柱水平放置在水槽中间直径为10mm。雷诺数为250。在流场中撒播直径为5μm,密度为1.05gmm-3的空心玻璃微珠作为示踪粒子,用一台2w的激光器照亮测量区域。相机的分辨率为640*480,采样频率为80Hz。在进行互相关计算时采用了窗口变形算法,查询窗最终大小为16*16,50%重叠区。本文模拟了8中不同的工况,分别是Q=0.5%,1%,2%,3%,4%,5%,7%,10%。对其中Q=3%的情况进行了详细的分析。图2给出了Q=3%时模拟的结果。3.2误差向量对POD分解的影响POD分解按流场的湍动能提取拟序结构,而误差向量直接影响流场湍动能。直观上判断流场中坏点越多,流场的湍动能就会越大,而且这种湍动能的增加并不是流动结构的变化引起的。设Q代表误差向量的个数占流场全部向量个数的百分比,Qr代表引入误差后流场湍动能的值与真实流场湍动能值的比值,当Q=0时Qr=1。图3给出了Qr随Q的变化规律。从图中可以看出,Qr明显随Q呈线性变化,增加1%的误差向量流场的湍动能增加23.27%。但是值得注意的是这种湍动能是由于随机误差造成的,并不包含流动结构。图3流场湍动能随Q的变化规律23.271QrQ接下来我们考虑误差向量对POD分解的影响。在前面一节我们已经知道基于两点互相关的POD按湍动能提取流场的流动特征。那么,由于引入了误差导致湍动能增加会影响POD分解的模态吗?怎样影响?为此,我们选择包含0%,0.5%,1%,3%,5%,10%的误差的流场进行本征正交分解,根据拟合的公式可知流场的湍动能分别为:100%,110.75%,121.5%,164.5%,207.5%,315%。图4给出了分解后的能量谱。由于流场整体能量的增加,各阶模态所占的相对能量百分比下降。设各阶模态的绝对能量为ie,0E为原始没有误差向量的流场所含总湍动能的绝对值。那么,原始场各阶模态的相对能量为:0iiiieeEe当引入误差矢量后,流场的湍动能会按照线性规律增加。增加的比例用Qr表示。用'i表示该流场模态的相对能量,于是得到:''''''0iiiiiQeeeEerE为了和原始模态进行比较,在上面的公式两端都乘以Qr,进行归一化处理。得到的结果如图所示。从图中可以看出,归一化后的各阶模态的相对能量曲线在低阶时很好的重合在一起。虽然流场的湍动能在不断增加,但是主要流动结构(低阶模态)的能量并没有发生变化。这说明误差向量并没有影响低阶模态的提取,用较少的低阶模态同样能重构出和原流场非常近似的流场。但是,从图中我们发现,随着误差向量的越来越多,对流场的影响逐渐深入到低阶高能模态,而且模态的阶数越来越多。这与流场的相关性降低有关。高阶模态反映了流场的随机误差,虽然随机误差场占有很大一部分湍动能,但这些湍动能并不包含流动结构并且每阶模态杂乱无章。低阶模态包含流场的大尺度流动结构,这些模态所含的能量越低,越容易受随机误差的影响。但是值得注意的是,随机误差在这些流动结构中所含的能量是十分有限的,大部分误差的能量仍然集中在高阶模态,并且各阶模态之间能量差别很小。正是这样的原因导致了POD模态的急剧增加,达到上千阶。对于含误差3%的PIV数据,如果选择前15阶和100阶模态进行重构得到的流场如图5所示。从图中可以看出,前15阶得到的流场受随机误差的影响要小很多,重构阶数越多流场受到的扰动越大。而且随机误差会传播到流场中的每一个点,这种误差均匀分布于全流场,通过对比很容易判断出误差的分布。图4不同Q下流场POD分解的能量谱图5Q=3%流场与POD重构对比通过上面的讨论得知,随机误差会快速的增加流场的湍动能,但是在一般PIV误差量级下,其能量在POD分解时还不足以影响流场的大尺度结构,即低阶高能模态。虽然各个点的误差会传播到整个流场,导致POD的模态不光滑,但并不影响对流场的近似重构。3.3基于POD的坏点剔除通过上面的分析我们知道,运用较少的低阶高能模态重构可以引入较少的随机误差。对比重构的流场和原始流场,在存在坏点的地方速度矢量的差别很大,而不存在坏点的地方绝对误差与周围的绝对误差相近。由于重构采用了固定的阶数,不可避免的产生了阶段误差,但是从局部3*3或5*5的区域来看,这种重构的阶段误差应该是非常相近的,这为我们判断坏点提供了方便。与Westerweel和Scarano4相同,考虑速度矢量0V和其周围3*3区域的相邻矢量12345678{,,,,,,,}VVVVVVVV,与之相对应的前m阶重构的速度矢量用0mV和12345678{,,,,,,,}mmmmmmmmVVVVVVVV。在平面PIV中每个速度矢量有两个分量u,v。重构的绝对误差22()()PODmmmiiiiiiirVVuuvv可以看出PODr为两矢量差的长度。该误差与重构阶数、流场特性有关。一般而言在强剪切区或湍流度比较大的区域该误差较大,这与POD分解的特性有关,这些区域需要更多的重构阶数才能达到一定的精度。另外,该误差还与该点速度的大小有关。由此可见用绝对误差PODr作为误差判断的标准并不能适应各种流动工况,一种简单的解决方法就是用周围点的绝对误差对其归一化。具体公式为:*00min()PODPODPODirrr式中*0PODr代表0V点误差归一化后的残差,分母上为周围8个点的绝点误差的最小值。和Westerweel和Scarano文献不同,之所以选择最小值,是加速收敛和对成片坏点有更好的剔除效果。为一常数,反映流场中整个误差的平均水平。可以预见在光滑的区域*0PODr应该是趋近于1的,而在存在坏点的地方残差应该很大。需要说明的是,之所以分母上选择中值而非平均,是因为中值滤波可以减少坏点的干扰,算法上更稳定。这样可以通过迭代剔除坏点不断的逼近真实流场。算法的实现过程如下:a)准备第k次迭代b)对前一次迭代得到的流场进行POD分解,若k等于1,则对原始PIV数据进行POD分解。这里要求原流场拥有足够多的帧数和周期,在时间上能够很好的解析整个流动过程。本文选择snapshotPOD方法。c)选择前4阶模态的相对能量作为收敛条件的判断。设2ke代表第k次迭代后前4阶模态的能量。随着坏点的不断剔除,低阶模态的能量会越来越大,最终趋于稳定。因此可以认为当2212()kkkeege时,程序已收敛,停止迭代;否则继续下一步。g的取值范围为1~2%。d)计算重构阶数km并用前km阶模态对流场进行重构。当k=1时,km=4。当k=2时,取原始数据能量谱和第1k次迭代完成并插值后数据能量谱的交点对应的阶数。如图XX所示,该点位置在迭代过程基本不变。e)按照公式计算残差*0POD
 三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 扫描二维码
扫描二维码









 飞翔的天空91
飞翔的天空91
本文标题:基于本征正交分解(POD)的PIV数据坏点剔除方法
链接地址:https://www.777doc.com/doc-2536669 .html