您好,欢迎访问三七文档
当前位置:首页 > 商业/管理/HR > 信息化管理 > 运用文本数据库中元数据关联规则进行知识发现的研究探究
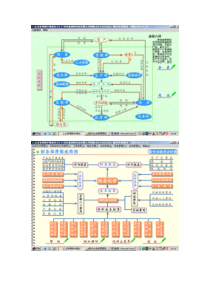
生物医学文本挖掘研究的体会中国医科大学信息管理与信息系统(医学)系主要内容1.开展的课题“运用文本数据库中元数据关联规则进行知识发现的研究”1.文本挖掘工具2.课题申请的体会运用文本数据库中元数据关联规则进行知识发现的研究文本数据库:PubMed元数据:关于数据的数据,MeSH主题词关联规则:associationrule,在同一个事件中出现的不同项的相关性,如在一次购物活动中所购商品的相关性(尿布→啤酒:30%~40%)事件:一篇论文;不同项:MeSH主题词MeSH主题词在同一篇文章中出现有规律吗?可否利用这种关联规律来发现知识?背景知识知识发现(KDD):从数据中正规提取隐含的、以前未知的并且可能有用的知识。数据挖掘:在数据中正规地发现有效的、新颖的、潜在有用的、并且最终可以被读懂的模式的过程。一般可以把数据挖掘当作知识发现的一个具体步骤。背景知识文本挖掘TextMining:文本挖掘LiteratureBasedDiscovery(LBD):基于文献的发现KnowledgeDiscoveryinBiomedicalLiterature(KDiBL):生物医学文献知识发现背景知识Cimino的研究哥伦比亚大学。如果在一篇文献纪录中同时存在“疾病类主题词/化学诱导副主题词”和“药物类主题词/副作用副主题词”这样的组合的话,那么可以建议该疾病由该化学物质(药物)引起。IfDisease/chemicallyinducedANDChemical/adverseeffectsThenDiseaseisCausedbyChemical.形成规则。将这样的规则运用的具体的其他文献集合中,就会发现文献中报道了大量的具体疾病是由某一种具体药物引起的。形成关系。背景知识规则的文字形式:“如果某一文献记录中含有属于1类的主题词A并且和副主题词X在一起,AND该引文还包括属于2类的主题词B并且和副主题词Y在一起,那么建议A和B通过关系Z相关(A和B有Z关系)。”根据Medline主题词和副主题词在同一篇文献中出现的情况,建立起主题词和副主题词之间的关联规则,然后将这些规则返回到具体的文献中形成了具体概念之间的关系。本课题目标寻找发现规则的方法。将获得规则用于某一领域,得到具体的关系。运用具体的关系开发出专题的知识库。技术路线下载专题文献截取高频M/S共词聚类分析高频M/S组合形成待检规则得不到关系得到关系返回具体文献发现新知识形成规则Swanson模式专家评价开发知识库分析样本:下载文献三个层次–微观层次:各个大类下的10个末级主题词–中观层次:针对每一种副主题词进行检索–宏观层次:直接以大类名为检索策略关键点1.确定高频主题词截取阈值,共词聚类分析最佳分组数目,伪F检验。2.候选规则检验。规则是否成立。3.规则是否可靠?专家评分,敏感度等。4.不成立组合的分析:swanson模式,关系?5.知识库开发。取得的成果方法是可行的。得到的规则。开发出相应的数据挖掘平台。–BICOMS–MeSH_Manager建立各种专题、主题的知识库。规则样例M1S1M2S2M1/S1SRM2/S2A02PathologyG06null的病态结构作为…的结果代谢过程A02PhysiologyG11Physiology的生理功能是...的位置的生理变化A02PhysiopathologyG11Physiology的异常功能破坏的生理变化A02MetabolismG04Physiology的代谢变化是...的位置的生理变化A02MetabolismD09Metabolism的代谢变化是...的位置的分解代谢A03DrugEffectsG06DrugEffects受药物作用发生了受药物作用A05DrugEffectsA05Metabolism受药物作用影响的代谢变化A07MetabolismD27Pharmacology的代谢变化受...影响的药理作用A07DrugEffectsG09DrugEffects受药物作用发生了受药物作用A07DrugEffectsA07Physiology受药物作用影响的生理功能A08DrugEffectsG05DrugEffects受药物作用发生了受药物作用今后的方向应用领域上,向生物信息学靠拢;实行中,寻求获得经济效益的可能;学科上,最终目标是知识发现;方法上,探索本体论在医学领域中的应用。二、数据挖掘工具文本挖掘的主要内容1.术语识别2.信息抽取3.发现关系TextMiningToolsSemanticKnowledgeRepresentation/语义知识表征项目,SKR美国国立医学图书馆,1998年启动文本中所包含知识进行正确表达利用美国国立医学图书馆现有的资源,尤其是一体化医学语言系统(UMLS)的知识库和SPECIALIST系统所提供的自然语言处理工具,开发出可以表达生物医学文本的实用程序。(1)我们使用血液过滤方法来治疗伴有难治性高血钾的地高辛过量(2)命题(proposition),大写的谓词(如TREATS、CAUSES等)表示的是个体之间的关系,这种关系都是在UMLS语义网络中所规定的语义关系;每一个体也是来自于UMLS超级词表中的规范化的概念。命题的集合组成了对文本(1)的语义表达,从上面例子可以看出,尽管这种表达并不完全,但是还是把文本中的主要概念及其关系表达出来了。MetaMapIndexing,MMI超级匹配标引,主动标引项目(IndexingInitiativeproject)的一部分。MetaMap用于对生物医学文献,尤其是MEDLINE中的记录进行自动标引。MetaMap在指定的记录中寻找的概念,根据这些概念在文本中出现的位置(如标题)以及该概念的独特性排序,按照一定阈值选取标引词。目前美国国立医学图书馆的标引人员在MEDLINE标引中使用MMI生成的概念排序作为参考。MataMap和SemRepMetaMap最初是为了改善MEDLINE检索而开发出来的,用通过MetaMap发现的超级词表概念来代替文本。EDGAR和ARBITEREDGAR(ExtractionofDrugs,GenesandRelations)–在MEDLINE中确定药物、基因关系的程序。–以前面几项工具为基础,以癌症治疗有关的药物和基因作为研究的主要领域,从文本中确认药物、基因和细胞株的名称。ARBITER(AssessandRetrieveBindingTerminology)–从生物医学文本中抽取大分子键联关系。Medline文献集合DonR.Swanson的研究潜在的联系雷诺氏病文献食用鱼油文献血液粘稠度红细胞脆性闭合式的知识发现ARROWSMITH3.0可作为生物武器的潜在病毒能够成为生物武器:致病性,传播性。同时涉及到病毒这两个特性的文章却特别少。A:病毒毒力遗传方面(virulence-genetic)C:病毒疾病传播力–病毒的昆虫媒介传播(insectvectors)–空气传播(air)–在空气中的稳定性(stabilityofvirusesinair)通过与A和C有共同联系B找出更多符合条件的病毒。将得到的文献经过一些系列的处理,Arrowsmith列出了三个有意义的B-LIST(病毒的集合),通过进一步的统计学分析和查阅文献,最终找出相对有意义的病毒(B)发现科研机构间潜在的合作方向利用Arrowsmith程序,发现美国斯坦福大学和哥伦比亚大学在医学信息学研究领域的潜在合作方向尝试将这种方法运用到寻求发现科研机构合作与交流的领域中。结果表明,利用Arrowsmith所挖掘的科研合作与交流的内容详细、明确,能体现出研究所使用的具体方法和侧重点,能更好地体现出两个机构研究内容的相似点(可以合作之处)和不同点(可以相互交流、学习之处)。开放式的知识发现BITOLA输入单个的概念(疾病A),找到该概念的第一层相关概念并加以归类(药物B)。从第一层相关概念(药物B)出发,找到它们的相关概念,并加以归类(基因C)。检验基因和疾病是否有关联。如果没有,该基因与疾病有潜在的联系而且并没有文献报道。提示:与疾病、生理学反应或者其他表型相关的新基因、药物或者神经科学。BITOLABITOLA:openBITOLA:closeBITOLA:closeBITOLA:closeMedlineR用于Medline文献数据挖掘的手写开放性R语言资源库-MedlineR。MedlineR库包括:1.在NCBIPubmed数据库查找医学文献的程序2.构建共现矩阵的程序3.检索词的网络拓扑结构的可视化程序。这个库的开放特性使得读者在R统计程序语言中免费扩展。只用10行代码来分析主题词的相关性。对于生物信息学家和统计学家来说,MedlineR是建立更加复杂的文献数据挖掘应用的基础。MedlineR为生物医学家和统计学家建立的文献数据挖掘工具的免费资源库MedlineR的源代码可以从中获得。MedlineRMedlineR结果是可视化的网状结构:每个节点代表一个基因,每条边代表一个文献中的联系。PajekMedlineR下载R统计软件(包括XML程序包)下载Pajek软件复制粘贴MedlineR的命令填入需要分析的基因名称运行R运行pajek://pubmatrix.grc.nia.nih.gov/://三、申请课题的体会–内容:创新是根本,对自己领域的掌握,阅读相关文献–形式:内在的逻辑,对标书格式的理解。–评审中看到的问题:•基础不等于研究内容•具体方法的使用(具体、数目)
 三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 扫描二维码
扫描二维码









 7614436
7614436
本文标题:运用文本数据库中元数据关联规则进行知识发现的研究探究
链接地址:https://www.777doc.com/doc-3451820 .html