您好,欢迎访问三七文档
当前位置:首页 > 行业资料 > 酒店餐饮 > 基因芯片数据分析中的标准化算法和聚类算法第一部分基因芯片的数
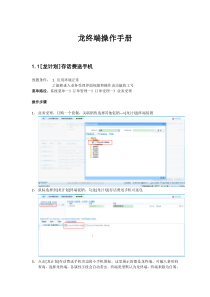
基因芯片数据分析中的标准化算法和聚类算法北京大学生命科学院生物信息专业王向峰学号:10211058摘要:基因芯片技术已经广泛的应用于各种模式生物的功能基因组的研究中,应用芯片技术可以高效,高通量的检测基因表达行为。芯片数据分析中的标准化主要分为芯片内标准化和芯片间标准化,芯片内标准化根据目的不同可分为消除染色偏差的LowessNormalization,消除点样针头引起的空间差异的Print-tipNormalization。常用的芯片间标准化有QuantileNormalization,GlobalNormalization。芯片数据分析中常见的聚类算法有分层聚类(Hierarchicalclustering)、K均值聚类(K-meansclustering)、自组织图谱SOM(selforganizingmap)、PCA(principlecomponentanalysis)等等。所有的聚类方法归结为有监督的学习和无监督的学习两种方法。第一部分基因芯片的数据标准化(Normalization)对基因芯片数据的标准化处理,主要目的是消除由于实验技术所导致的表达量(Intensity)的变化,并且使各个样本(sample)和平行实验的数据处于相同的水平,从而使我们可以得到具有生物学意义的基因表达量的变化。标准化的方法根据芯片的种类、数据处理的阶段和目的不同而有所差异。这里主要讨论一下双荧光染色(RedandGreenChip)的cDNA微列阵(cDNAmicroarray)的标准化方法。一、实验数据的预处理(datatransformation)双色cDNA芯片(two-colorcDNAmicroarray),指对参照基因(referencegene)和样本基因(samplegene)标上绿色和红色荧光标记。参照基因的制备主要是提取不同组织的不同时期的细胞进行培养(CulturedCell),以保证绝大部分的基因可以表达。样本基因是根据试验设计的目的从不同组织,不同发育阶段,不同条件下培养的细胞中提取的cDNA样本。通过样本基因对参照基因的比值,而判断不同条件下的基因表达量的变化。扫描仪对基因芯片的图像进行扫描,根据每个点的光密度值尝试相对应的绝对表达量(intensity)。然后图像分析软件通过芯片的背景噪音以及杂交点的光密度分析,对每个点的intensity校准,然后取样本基因和参照基因的比值(R/Gratio),作为每个样本基因的相对表达量(relativeintensity)。选择相对表达量,可以在一定程度上减少芯片之间,荧光染色,扫描所产生的系统偏差。然后对比值取对数,2log10=,选择以2为底的对数方便于对基因表达量变化的研究,比如R/G=1,则2log10=,即认为表达量没有发生变化,当R/G=2或者,R/G=0.5,则log值为1或–1,这是可以认为表达量都发生两倍的变化,只是一个是受到诱导的正调控,另一个受到抑制的负调控。以下的数据处理都是对2log/RGratio的形式进行分析。二、标准化(normalizationofMicroarray)1、数据过滤(datafiltering)通过图像扫描软件,将每个杂交点的光强度转化为表达量时,会产生负的数据值或者0,这主要是软件的算法对背景噪音处理时所产生的。由于负数和零是不能对数化的,所以过滤掉这些脏数据是非常必要的。忽略这些点的信息并不会对整体的分析产生影响,因为这些极弱的信号不足以为基因表达的差异提供证据。2、MAplotMAplot作图是用来观察芯片数据的分布情况,其中:22log/logMRGARG==×以M(logratio表达量)为纵坐标,A(logintensity表达量)为横坐标做出数据的散点分布图。3、芯片间的数据标准化(Crossslidenormalization)由于五种组织(seeding、tiller、root、panicle1、panicle2)是分别在五张芯片上作杂交试验的,所以第一步的标准化是将五张试验芯片的数据调整到同一水平,常用的方法是平均数、中位数标准化(meanormediannormalization)。即:将五组实验的数据的logratio中位数或平均数调整为0。2222log()log()log()log()iiaiiaiTTmeanTTmedianRTG′=−′=−=(脚标a为每组实验数据)从以上两图的比较可以看出,中位数标准化,可以将每组数据调整到同一水平。4、平行实验数据的标准化一般芯片的杂交实验很容易产生误差,所以经常一个样本要做3~6次的重复实验。平行实验间的数据差异可以通过QuantileNormalization去处掉。总平行实验的前提条件是假设n次实验的数据具有相同的分布,其算法主要分为三步:(1)对每张芯片的数据点排序。(2)求出同一位置的几次重复实验数据的均值,并用该均值代替该位置的基因的表达量。(3)将每个基因还原到本身的位置上。如图所示,水稻的一个样本的6次重复实验的数据分布用不同颜色的柱状图表示。从标准化前的分布来看,虽然6次实验的数据总体基本一致,但每个基因的表达差异依然存在;做过quantilenormalization后,6次重复实验有了完全一致的分布,另外,噪音的分布(次峰)也显露了出来。5、芯片内的数据标准化(withinslidenormalization)芯片内的数据标准化,主要是去除每张芯片的系统误差,这种误差主要是由荧光染色差异,点样机器(arrayerprint-tip),或者杂交试验所产生的,通过标准化,使每个基因的表达点都具有独立性。芯片内数据标准化的常用方法是局部加权回归分析:Lowess(LocallyWeightedLinearRegression)normalization。Lowess回归分析是一种非参数回归方法,也称为平滑方法,在计算两个变量的关系时采用开放式算法,不套用现成的函数公式,所拟合的曲线可以很好的描述变量之间关系的细微的变化。比如在分析某一点(x,y)的变量关系时,Lowess回归的步骤如下:Step1、首先确定以x为中心的一个区间(Window)内参加局部回归的观察值的个数q。q值设的越高则得到的拟和曲线越平滑,但对变量关系的细微变化越不敏感。小的q值会对细微的变化很敏感,但是得到的拟和曲线变得很粗糙。Step2、定义区间内所有点的权数,权数由权数函数来决定,任一点的权数是权数函数的曲线的高度。Step3、对每个区间内的q个散点拟和一条直线,拟合曲线描述这个区间内的变量关系。Step4、拟合值y值就是在x点的y的拟合值。依照上面四个步骤,所有的点都计算拟合值,昀终得到一组平滑曲线的平滑点,昀后在把这些平滑点用短直线连接起来,就得到了Lowess的回归曲线。(1)LowessNormalization22log/log/()iRGRGloessA′′=−每一点的logratio减去该点的经过loess加权函数得到值,得到残差即为M纵坐标。根据不同的加权函数可以得到不同的lowess拟合曲线,常用的还有globallowessnormalization、2-dimensionlowessnormalization等。(3)、print-ordernormalization在芯片试验中,还有很多操作过程是导致产生偏差的因素,比如点样的顺序,杂交的顺序,用不同的托盘等等,在大部分的实验中,可以通过以上介绍的几种方法对数据进行校正,但在有些试验中,由于背景噪声过强,还要进行有针对性的数据标准化。例如:print–ordernormalization等。基因芯片数据的标准化载芯片数据处理过程中占有极其重要的地位,为接下来的聚类分析、基因表达谱、代谢谱等分析奠定了基础。目前基因芯片数据的标准化问题一直是芯片研究中的热点问题,现在已经提出很多种标准化的方法。对于芯片间的中位数标准化,和芯片内的Lowess标准化,是芯片数据分析的常规方法。但是经过这两种方法标准化后的数据仍然存在偏差,这就需要针对具体的实验操作步骤再设计出具体的标准化方法,例如plate-ordernormalization,print-tipsnormalization,print-ordernormalization等等。第二部分基因芯片数据的聚类(Cluster)分析基因芯片数据在经过上述normalization后,接下来做聚类分析。聚类是指根据基因芯片的基因表达数据,将基因按照不同的功能,或者相同的表达行为进行归类,聚类的基因表达谱为研究人员提供基因表达差异,启动子分析,表达模式研究等等便利的条件。目前已经有很多种聚类的方法应用到基因芯片的研究当中,如分层聚类(Hierarchicalclustering)、K均值聚类(K-meansclustering)、自组织图谱SOM(selforganizingmap)、PCA(principlecomponetanalysis)等等。总的来说,可以把所有的聚类方法归结为有监督的学习和无监督的学习两种方法。1、分层聚类(Hierarchicalclustering)分层聚类是昀早也是昀普遍的应用在基因芯片数据分析研究中的聚类算法。步骤如下:(1)建立Gene-experiment矩阵seedingTillerrootPanicle1Panicle2Gene11.21.3-0.9-0.31.1Gene2-1.50.40.34.2-0.5。。。。。。Genen每一列是不同的组织,或者在不同条件下的样本,每一行是基因的编号,每个基因的表达量用标准化后2log/RG的表示。(2)计算所有基因之间的相关系数correlationcoefficient。基因的相似分值(similarityscore)可以由Pearsonscorrelation公式计算1,21,1(,)()()()ioffsetioffsetiNXYioffsetGiNXXYYSXYNGGN==−−=ΦΦ−Φ=∑∑offsetG一般取标准化后的中位数,或平均值,等于0,即2log/RG=0,表示表达无差异。(3)建立Gene-Gene的距离矩阵Gene1Gene2。。。。。GeneNGene1D11Gene2D12D22。。。。。。。。。。。。。。。。GeneND1ND2N。。。。DNN(4)建立系统发育树(dendrogram)根据Gene-Gene的距离矩阵的分值,首先找到距离昀近的两个基因,然后合并,再找距离相近两组再合并,直到所有的基因合并到一个组中。(5)建立表达图谱绘制表达谱图时,log值为正,用红色表示,越大红色越亮,表示,基因表达的水平越高,受到的诱导(induced)越强;log值为负则用绿色表示,越小绿色越亮,基因表达的水平越低,受到的抑制(depressed)越强。2、K-均值聚类(K-meanscluster)K–means聚类与分层聚类有本质的区别,首先要估计出将要分出几个类,然后将全部的基因按照相似性的距离,归入这几类中。步骤如下:首先也是要先将gene-expriments矩阵转化成gene-genedistance矩阵,但是计算基因的相关系数的方法与分层聚类有所不同,用欧及里距离(Euclideandistance)公式计算:21(,)()miiidXYXY==−∑X,Y为两个基因然后,将所有的基因随机的分配到K类中,计算出每个类中的基因的均值,然后,将每个基因分配到均值与它昀相近的那个类中。重复以上两个步骤,直到所有的基因都被分配到类中。3、自组织映射聚类(SOM)自组织映射聚类(Self-OrganizingMap,SOM),是由T.Konohen于1980年提出的模型,属于非监督学习的神经网络聚类,与K-means相似,采用SOM聚类算法之前,也要首先估计出想要得到的类的个数。再SOM神经网络中,输出层的神经元是以列阵的方式列阵的方式排列于一维或二维的空间中的。根据当前输入向量与神经元的竞争,利用欧式距离,寻找昀短距离当作昀有
 三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 扫描二维码
扫描二维码









 hyyihy
hyyihy
本文标题:基因芯片数据分析中的标准化算法和聚类算法第一部分基因芯片的数
链接地址:https://www.777doc.com/doc-359795 .html