您好,欢迎访问三七文档
当前位置:首页 > 商业/管理/HR > 企业财务 > chap4-信源编码3
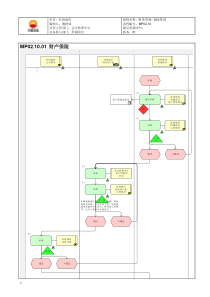
1MH编码:文件传真是指一般文件、图纸、手写稿、表格、报纸等文件的传真,这种信源是黑白二值的,也即信源为二元信源(q=2)。MH编码是一维编码方案,它是一行一行的对文件传真数据进行编码。编码将游程编码和霍夫曼码相结合,是一种改进的霍夫曼码。游程编码-------------------MH编码2MH码以国际电话电报咨询委员会(CCITT)确定的8幅标准文件样张为样本信源,对这8幅样张作统计,计算出“黑”、“白”各种游程长度的出现概率,然后根据这些概率分布,分别得出“黑”、“白”游程长度的霍夫曼码表。MH码分别对“黑”、“白”像素的不同游程长度进行霍夫曼编码,形成黑、白两张霍夫曼码表。MH码的编、译码都通过查表(P134-135,表5.4.1,表5.4.2)进行。游程编码-------------------MH编码3MH码编码规范游程编码中MH(1)游程长度在0~63时,直接查表用相应的结尾码作为码字;如:20白40黑(2)游程长度在64~1728范围内时,用组合码加上结尾码作为相应的码字;如:856000100|000001101100856=832+24=64*13+240000001001101|000000101114MH编码编码规范(续)(3)每行的第一个游程规定为白游程(长度可以为零),每行用一个结束码(EOL)终止;(4)在传输时,每页数据之前加一个结束码,每页尾部连续使用6个结束码。5MH编码编码规范(续)5)译码时,每一行的码都应恢复出1728个像素,否则有错。6)为了在传输时可实现同步操作,规定T为每个编码行的最小传输时间,一般规定T最小为20,最大为5。若编码行传输时间小于T,则在结束码之前填上足够的“0”码元(称填充码)。如果采用编码仅仅是用于存储,则可省去步骤中的4)至6)步。6MH码---------------------------例题设某页传真文件中某一扫描行的像素点为:17白5黑55白10黑l641白解:通过查表可得该扫描行的码为:该行经编码后只需用54位二元码元,而原来一行共有1728个像素,如用“0”表示白,用“l”表示黑,则共需1728位二元码元。可见,这一行数据的压缩比为1728:54=32,因此压缩效率很高。17白5黑55白10黑1600白41白EOL1010110011010110000000100010011010001010100000000000017多元游程序列多元序列也存在相应的游程序列多元序列变换成游程序列再进行压缩编码没有多大意义游程编码只适用于二元序列,对于多元信源,一般不能直接利用游程编码8算术编码非分组码的编码方法之一——算术码原理:从全序列出发,考虑符号之间的依赖关系来进行编码5.4.2算术编码9算术编码不同于哈夫曼码,它是非分组(非块)码。它从全序列出发,考虑符号之间的关系来进行编码。算术编码利用了积累概率的概念。算术码主要的编码方法是计算输入信源符号序列所对应的区间。因为在编码过程中,每输入一个符号要进行乘法和加法运算,所以称此编码方法为算术编码。算术编码10从整个符号序列出发,将各信源序列的概率映射到[0,1)区间上,使每个符号序列对应于区间内的一点,也就是一个二进制的小数。这些点把[0,1)区间分成许多小段,每段的长度等于某一信源序列的概率。再在段内取一个二进制小数,其长度可与该序列的概率匹配,达到高效率编码的目的。算术编码------------------基本思路11算术编码------------------概率区间由于Fi和Fi-1都是小于“1”的正数,可用[0,1)区间内的两个点来表示,而pi-1就是这两个点之间的长度,如图所示。112221312111,,,,0nnniiiipFFpFppFpFFpF那么可得为:定义各符号的累计概率F1F2F3F4F(cad)=F(ca)+p(ca)F(d)=0.514A(cad)=A(ca)p(d)=0.006=p(cad)符号abcd概率p0.10.40.20.3积累概率F00.10.50.7010.10.50.7A(a)A(b)A(c)A(d)0.50.70.50.520.5140.52对序列cada做算术编码F(c)=0.5A(c)=0.2=p(c)F(ca)=F(c)+p(c)F(a)=0.5A(ca)=A(c)p(a)=0.02=p(ca)F(cadb)=F(cad)+p(cad)F(b)=0.5146A(cadb)=A(cad)p(b)=0.0024=p(cadb)0.520.5140.514613算术编码--------------------递推公式我们可取该小区间内的一点来代表这个信源符号序列,那么选取此点方法可以有多种,实际中常取小区间的下界值。对信源符号序列的编码方法也可有多种,下面介绍常用的一种算术编码方法。的联合概率为符号序列的累积概率,为符号序列累积概率的递推公式区间宽度的递推公式SSpSSFrFSpSFSrFSrprpSprpSASrA)()()()()()()()()()()()(14算术编码--------------------二元码15算术编码---------------二元码递推公式的联合概率为符号序列的累积概率,为符号序列累积概率的递推公式区间宽度的递推公式SSpSSFpSpSFFSpSFSFSFSFSrprpSprpSASrA)()()0()()()1()()()1()()0()()()()()()(r=0,1,F(0)=0;F(1)=p(0)16算术编码--------------------编码方法将信源符号序列S的累积概率值写成二进位的小数F(S)=0.c1c2……cL,ci∈{0,1},取小数点后L位,若后面有尾数,就进位到第L位,并使L满足:式中表示大于或等于x的最小整数。这样得到信源符号序列所对应的一个算术码:x12Lccc)(1logSpL17例:设二元无记忆信源S={0,1},其p(0)=1/4,p(1)=3/4。对二元序列11111100做算术编码。解:p(S=11111100)=p2(0)p6(1)=(3/4)6(1/4)2=0.01112366算术编码-------------------------例7)(1logSpL18F(Sr)=F(S)+p(S)F(r)在二元码中F(S0)=F(S)F(S1)=F(S)+p(S)F(1)=F(S)+p(S)p(0)F(S=11111100)=p(0)+p(1)p(0)+p(1)2p(0)+p(1)3p(0)+p(1)4p(0)+p(1)5p(0)=0.82202148=(0.110100100111……)2算术编码------------------------例(续)19信源符号序列S的累积概率值的变化及区间宽度减小的过程如图所示。算术编码------------------------例(续)20取S二进制表示小数点后L位,得到信源符号序列的算术码字为1101010本例对输入信源符号序列进行算术编码后平均码长为:编码效率为:78L()0.8110.9277/8HSL算术编码------------------------例(续)21算术码的译码:对二元算术码而言,其译码过程是一系列比较过程:每一步比较C-F(S)与A(S)p(0),这里S为前面已译出的序列串,A(S)是序列串S对应的宽度,F(S)是序列S的累积概率值,即为S对应区间的下界限,A(S)p(0)是此区间内下一个输入为符号“0”所占的子区间宽度。译码规则为:若C-F(S)<A(S)p(0),则译输出符号为“0”;若C-F(S)>A(S)p(0),则译输出符号为“1”。算术编码----------二元算术码译码22算术编码----------编译码例题其中[x,y]表示半开放间隔,即包含x不包含y。上面的信息可综合在下表中。符号ABCD概率0.10.40.20.3初始编码间隔[0,0.1)[0.1,0.5)[0.5,0.7)[0.7,1]23如果二进制消息序列的输入为:CADACDB。242526从性能上来看,算术编码具有许多优点,它所需的参数较少、编码效率高、编译码简单,不象霍夫曼码那样需要一个很大的码表,在实际实现时,常用自适应算术编码对输入的信源序列自适应地估计其概率分布。算术编码在图像数据压缩标准(如JPEG)中得到广泛的应用。27在算术编码中有几个问题需要注意:由于实际的计算机的精度不可能无限长,一个明显的问题是运算中出现溢出,但多数机器都有16、32或者64位的精度,因此这个问题可使用比例缩放方法解决。算术编码器对整个消息只产生一个码字,这个码字是在间隔[0,1]中的一个实数,因此译码器在接受到表示这个实数的所有位之前不能进行译码。算术编码也是一种对错误很敏感的编码方法,如果有一位发生错误就会导致整个消息译错。28通用编码哈夫曼编码与算术编码都要预先知道信源符号的概率分布。实际问题中往往无法知道或没有必要去统计信源各个符号的概率,希望有一种通用的非概率的编码方法。我们把这种不依靠概率知识就能进行压缩编码的方法叫做通用编码。由于通用,因而普适。它已经成为一种应用广泛的文件压缩技术。现已找到多种通用编码方法,如目前在计算机上常用的ZIP、RAR等。29通用编码----------------------LZ码最有影响力的通用编码是L-Z码。它是以色列的研究人员兰培尔(A.Lamprl)和齐夫(J.Ziv)于20世纪70年代提出的。鉴于实际各类文件中总有许多字词、短语、甚至段落会经常重复出现,就为L-Z码的发明提供了可以利用的契机。30LZ码-------------------------基本思路L-Z码的基本思路是把信源序列分成许多长短不同的小段,凡是后面出现了前面出现过的段落时,就不重复输出,而用代号表达,使文字数量减少,长度变短。一点说明:尽管L-Z码并没有刻意地统计每个字符的概率,但是编码过程中查看是否有前面出现过的词语,这本身就是一种无意地统计,它属于边统计边编码的自适应编码方法。31LZ77-------------------------指针编码原理:当待编字符串在早先输出的数据流中已经出现过时,则不必重复输出,而用指向早先那个字符串(称为匹配字符串)的指针(指示匹配字符串的位置)来代替。32LZ78----------------------词典算法其想法是企图从输入的数据中创建一个“短语词典”,这种短语不一定具有语义,它可以是任意字符的组合编码数据过程中当遇到已经在词典中出现的“短语”时,编码器就输出这个词典中的短语的“索引号”,而不是短语本身编码过程一方面是查字典:对新输入的字符串寻找词典中最长的匹配词条;另一方面是写字典:把没找到的新词条不断扩充进词典中。33LZ78码举例设q=4,输入信源序列为输出数据流(n,s)(n为所找到的最长匹配词条在词典中的序号,S为当前待编字符)序号1234567词条a0a0a2a3a1a1a0a0a0a0a2a3a0a0a2a3a1a1a0a0a0a0a2a3…0,a01,a20,a30,a14,a01,a02,a334转换为二进制编码字典表共7段,所以l=3位二元码符号集q=4,所以需要2位二元码,分别为a0–00a1–01a2–10a3–11输出数据流0,a01,a20,a30,a14,a01,a02,a30000000110000110000110000001000011135LZ码---------------------------小结L-Z编码的原理:从实际文件出发,凡出现过的都记下来,以后再出现时就用序号来代替。字典编码的算法:字典的设计、建立、添加与整理;边查字典边输出,边搜寻新词边补充;字典编码的实质-----
 三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 扫描二维码
扫描二维码








 hhandpp
hhandpp
本文标题:chap4-信源编码3
链接地址:https://www.777doc.com/doc-4003179 .html