您好,欢迎访问三七文档
当前位置:首页 > 商业/管理/HR > 经营企划 > 82逆向思维与统计研究
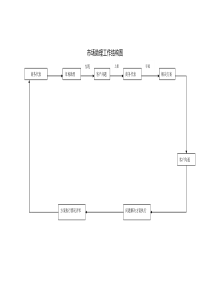
1聚类分析吴喜之2聚类•俗语说,物以类聚、人以群分。•但什么是分类的根据呢?•比如,要想把中国的县分成若干类,就有很多种分类法;•可以按照自然条件来分,•比如考虑降水、土地、日照、湿度等各方面;•也可以考虑收入、教育水准、医疗条件、基础设施等指标;•既可以用某一项来分类,也可以同时考虑多项指标来分类。3聚类分析•对于一个数据,人们既可以对变量(指标)进行分类(相当于对数据中的列分类),也可以对观测值(事件,样品)来分类(相当于对数据中的行分类)。•比如学生成绩数据就可以对学生按照理科或文科成绩(或者综合考虑各科成绩)分类,•当然,并不一定事先假定有多少类,完全可以按照数据本身的规律来分类。•本章要介绍的分类的方法称为聚类分析(clusteranalysis)。对变量的聚类称为R型聚类,而对观测值聚类称为Q型聚类。这两种聚类在数学上是对称的,没有什么不同。4饮料数据(drink.sav)•16种饮料的热量、咖啡因、钠及价格四种变量5如何度量远近?•如果想要对100个学生进行分类,如果仅仅知道他们的数学成绩,则只好按照数学成绩来分类;这些成绩在直线上形成100个点。这样就可以把接近的点放到一类。•如果还知道他们的物理成绩,这样数学和物理成绩就形成二维平面上的100个点,也可以按照距离远近来分类。•三维或者更高维的情况也是类似;只不过三维以上的图形无法直观地画出来而已。在饮料数据中,每种饮料都有四个变量值。这就是四维空间点的问题了。6两个距离概念•按照远近程度来聚类需要明确两个概念:一个是点和点之间的距离,一个是类和类之间的距离。•点间距离有很多定义方式。最简单的是歐氏距离,还有其他的距离。•当然还有一些和距离相反但起同样作用的概念,比如相似性等,两点越相似度越大,就相当于距离越短。•由一个点组成的类是最基本的类;如果每一类都由一个点组成,那么点间的距离就是类间距离。但是如果某一类包含不止一个点,那么就要确定类间距离,•类间距离是基于点间距离定义的:比如两类之间最近点之间的距离可以作为这两类之间的距离,也可以用两类中最远点之间的距离作为这两类之间的距离;当然也可以用各类的中心之间的距离来作为类间距离。在计算时,各种点间距离和类间距离的选择是通过统计软件的选项实现的。不同的选择的结果会不同,但一般不会差太多。7向量x=(x1,…,xp)与y=(y1,…,yp)之间的距离或相似系数:2()iiixy欧氏距离:Euclidean平方欧氏距离:SquaredEuclidean2()iiixy夹角余弦(相似系数1):cosine22(1)cosiiixyxyiiiixyCxyPearsoncorrelation(相似系数2):Chebychev:Maxi|xi-yi|Block(绝对距离):Si|xi-yi|Minkowski:1()qqiiixy当变量的测量值相差悬殊时,要先进行标准化.如R为极差,s为标准差,则标准化的数据为每个观测值减去均值后再除以R或s.当观测值大于0时,有人采用Lance和Williams的距离||1iiiiixypxy22()()(2)()()iiixyxyiiiixxyyCrxxyy8类Gp与类Gq之间的距离Dpq(d(xi,xj)表示点xi∈Gp和xj∈Gq之间的距离)min(,)pqijDdxx最短距离法:最长距离法:重心法:离差平方和:(Wald)类平均法:(中间距离,可变平均法,可变法等可参考各书).在用欧氏距离时,有统一的递推公式(假设Gr是从Gp和Gq合并而来):12121212()'(),()'(),()'()ipjqkpqipipjqjqxGxGkipqxGGDxxxxDxxxxDxxxxDDDDmax(,)pqijDdxxmin(,)pqpqDdxx121(,)ipjqpqijxGxGDdxxnn9Lance和Williams给出(对欧氏距离)统一递推公式:D2(k,r)=apD2(k,p)+aqD2(k,q)+bD2(p,q)+g|D2(k,p)-D2(k,q)|前面方法的递推公式可选择参数而得:方法ai(i=p,q)bg最短距离½0-1/2最长距离½01/2重心ni/nr-apaq0类平均ni/nr00离差平方和(ni+nk)/(nr+nk)-nk/(nr+nk)0中间距离1/2-1/40可变法(1-b)/2b(1)0可变平均(1-b)ni/nrb(1)010有了上面的点间距离和类间距离的概念,就可以介绍聚类的方法了。这里介绍两个简单的方法。11事先要确定分多少类:k-均值聚类•前面说过,聚类可以走着瞧,不一定事先确定有多少类;但是这里的k-均值聚类(k-meanscluster,也叫快速聚类,quickcluster)却要求你先说好要分多少类。看起来有些主观,是吧!•假定你说分3类,这个方法还进一步要求你事先确定3个点为“聚类种子”(SPSS软件自动为你选种子);也就是说,把这3个点作为三类中每一类的基石。•然后,根据和这三个点的距离远近,把所有点分成三类。再把这三类的中心(均值)作为新的基石或种子(原来的“种子”就没用了),重新按照距离分类。•如此叠代下去,直到达到停止叠代的要求(比如,各类最后变化不大了,或者叠代次数太多了)。显然,前面的聚类种子的选择并不必太认真,它们很可能最后还会分到同一类中呢。下面用饮料例的数据来做k-均值聚类。12•假定要把这16种饮料分成3类。利用SPSS,只叠代了三次就达到目标了(计算机选的种子还可以)。这样就可以得到最后的三类的中心以及每类有多少点FinalClusterCenters203.1033.71107.341.654.163.4913.0510.068.763.152.692.94CALORIECAFFEINESODIUMPRICE123ClusterNumberofCasesineachCluster2.0007.0007.00016.000.000123ClusterValidMissing13根据需要,可以输出哪些点分在一起。结果是:第一类为饮料1、10;第二类为饮料2、4、8、11、12、13、14;第三类为剩下的饮料3、5、6、7、9、15、16。15事先不用确定分多少类:分层聚类•另一种聚类称为分层聚类或系统聚类(hierarchicalcluster)。开始时,有多少点就是多少类。•它第一步先把最近的两类(点)合并成一类,然后再把剩下的最近的两类合并成一类;•这样下去,每次都少一类,直到最后只有一大类为止。显然,越是后来合并的类,距离就越远。再对饮料例子来实施分层聚类。16•对于我们的数据,SPSS输出为17例:5个样品距离阵令Dk为系统聚类法种第k次合并时的距离,如{Dk}为单调的,则称具有单调性.前面只有重心和中间距离法不具有单调性.0070()160938085740ijDd步骤:最短距离法最长距离法阶段bk(第k阶段类的集合)DkDkD(0)(1)(2)(3)(4)(5)00D(1)(1,3)(2)(4)(5)11D(2)(1,3)(2,4)(5)33D(3)(1,3)(2,4,5)45D(4)(1,3,2,4,5)69注:最短和最长距离法结果一样(一般不一定一样)18聚类要注意的问题•聚类结果主要受所选择的变量影响。如果去掉一些变量,或者增加一些变量,结果会很不同。•相比之下,聚类方法的选择则不那么重要了。因此,聚类之前一定要目标明确。•另外就分成多少类来说,也要有道理。只要你高兴,从分层聚类的计算机结果可以得到任何可能数量的类。但是,聚类的目的是要使各类之间的距离尽可能地远,而类中点的距离尽可能的近,而且分类结果还要有令人信服的解释。这一点就不是数学可以解决的了。32聚类分析结束回到选择?
 三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 扫描二维码
扫描二维码








 guobin19851030
guobin19851030
本文标题:82逆向思维与统计研究
链接地址:https://www.777doc.com/doc-4063827 .html