您好,欢迎访问三七文档
当前位置:首页 > 商业/管理/HR > 质量控制/管理 > 62(统计量与抽样分布)
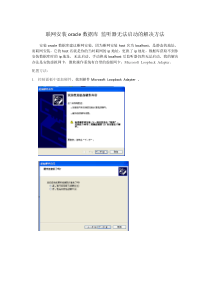
6.2统计量与抽样分布在利用样本推断总体的性质时,往往不能直接利用样本,而需要对它进行一定的加工,这样才能有效地利用其中的信息,否则,样本只是呈现为一堆“杂乱无章”的数据.第6章数理统计基础【例6.3】从某地区随机抽取50户农民,调查其人均年收入情况,得到数据(单位:元)如下:试对该地区农民收入的水平和贫富悬殊程度做个大致分析.92480091670487010408246905744909729881266684764940408804610852602754788962704712854888768848882119282087861484674682879287269664492680810107287428508647386.2统计量与抽样分布解:显然,如果不进行加工,面对这一大堆大小参差不齐的数据,很难得出什么印象.但是可以对这些数据稍事加工,如记各农户的人均年收入分别为x1,x2,...,x50,计算得到这样,就可以了解到该地区农民的平均收入和该地区农民贫富悬殊的大致情况:农民的年人均平均收入大约为809.52元,标准差约为155.85元,贫富悬殊不算很大.6.2统计量与抽样分布,52.809501501iixx85.155)(15015012iixxs由此可见对样本的加工是十分重要的.对样本加工,主要就是构造统计量.6.2.1统计量定义6.2设X1,X2,…,Xn为来自总体X的样本,称不含未知参数的样本的函数g(X1,X2,…,Xn)为统计量.若x1,x2,...,xn为样本观测值,则称g(x1,x2,...,xn)为统计量g(X1,X2,…,Xn)的观测值.统计量是处理、分析数据的主要工具.对统计量的一个最基本的要求就是可以将样本观测值代入进行计算,因而不能含有任何未知的参数.6.2统计量与抽样分布【例6.4】设X1,X2,…,Xn是来自总体X的样本,X~N(,2),其中、2为未知参数,则X1,min{X1,X2,…,Xn}均为统计量,但诸如等均不是统计量,因它含有未知参数或.常用的统计量有如下几种:6.2.1统计量,312121XX,)(112niiXn1X1.有关一维总体的统计量设X1,X2,…,Xn为总体X的样本,x1,x2,...,xn为样本观测值,(1)样本均值常用来作为总体期望(均值)的估计量,其观测值为6.2.1统计量niiXnX11niixnx11(2)样本方差(3)样本标准差样本方差和样本标准差刻画了样本数据的分散程度,常用来作为总体方差和标准差的估计量.观测值分别为6.2.1统计量niiXXnS122)(11,)(11122niixxns2SSniixxnss122)(11niiXnXn12211(4)样本k阶原点矩(简称样本k阶矩),(k=1,2,…)(5)样本k阶中心矩,(k=2,3,…)显然Ak和Bk的观测值分别记为6.2.1统计量nikikXnA11nikikXXnB1)(1,1XAniiXXnB122)(1,11nikikxnanikikxxnb1)(1定理6.1设总体X的期望E(X)=,方差D(X)=2,X1,X2,…,Xn为总体X的样本,,S2分别为样本均值和样本方差,则6.2.1统计量)()(XEXEnnXDXD2)()(22)()(XDSE)(2SEniiXXnE12)(11niiXnXnE12211niiXnEXEn122)()(11ninnn12222)(112X由辛钦大数定理和依概率收敛的性质可以证明定理6.2设总体X的k阶原点矩E(Xk)=k存在(k=1,2,…,m),X1,X2,…,Xn为总体X的样本,g(t1,t2,…,tm)是m元连续函数,则特别有6.2.1统计量),...,2,1,()(11mknXEXnAkkniPkik)(),...,,(),...,,(2121ngAAAgnPn),(XEXP212212122)(1)(1AAXnXnXXnBniinii).(212XDP2.有关二维总体的统计量设(X1,Y1),(X2,Y2),…,(Xn,Yn)为二维总体(X,Y)的样本,其观测值为(x1,y1),(x2,y2),…,(xn,yn),则下列各量为统计量:(1)样本协方差(2)样本相关系数其中SXY和RXY常分别用来作为总体X和Y的协方差Cov(X,Y)与相关系数XY的估计量.6.2.1统计量niiiXYYYXXnS1))((11YXXYXYSSSR,)(11122niiXXXnSniiYYYnS122)(11【实验6.2】用Excel对例6-3中的数据计算统计量样本均值、样本方差和样本标准差的观测值.实验准备:(1)函数AVERAGE的使用格式:AVERAGE(number1,number2,...)功能:计算给定样本的算术平均值.(2)函数VAR的使用格式:VAR(number1,number2,...)功能:计算给定样本的方差.(3)函数STDEV的使用格式:STDEV(number1,number2,...)功能:计算给定样本的标准差.6.2.1统计量实验方法一:(1)输入数据及统计量名,如图6-7左所示.(2)计算样本均值,在单元格H2中输入公式:=AVERAGE(A2:E11)(3)计算样本方差s2,在单元格H3中输入公式:=VAR(A2:E11)(4)计算样本标准差s,在单元格H4中输入公式:=STDEV(A2:E11)计算结果:、s2=24288.91、s=155.85,如图6-7右所示.6.2.1统计量图6-7计算统计量6.2.1统计量实验方法二:(1)输入整理数据,如图6-8左所示.(2)在Excel主菜单中选择“工具”“数据分析”,打开“数据分析”对话框,在“分析工具”列表中选择“描述统计”选项,单击“确定”按钮.(3)在打开的“描述统计”对话框中,依次输入“输入区域”和“输出区域”,选中“标志位于第一行”复选框,如图6-8中所示,单击“确定”按钮.得到描述统计的结果如图6-8右所示.6.2.1统计量图6-8描述统计6.2.1统计量6.2统计量与抽样分布6.2.2抽样分布统计量的分布称为抽样分布.为了研究抽样分布,先研究数理统计中三种重要的分布.1.2分布定义6.3设X1,X2,…,Xn为相互独立的随机变量,它们都服从标准正态N(0,1)分布,则称随机变量服从自由度为n的2分布,记为2~2(n).此处自由度指2中包含独立变量的个数.可以证明,2(n)的概率密度为其中()称为伽马函数,niiX1226.2.2抽样分布0,00,)(21)(212222xxexxfxnnn0,)(01dxexx2分布概率密度图6-92(n)分布的概率密度曲线可以看出,随着n的增大,的图形趋于“平缓”,其图形下区域的重心亦逐渐往右下移动.6.2.2抽样分布0,00,)(21)(212222xxexxfxnnn2分布具有下面性质:(1)(可加性)设是两个相互独立的随机变量,且(2)设证明(1)由2分布的定义易得证明.(2)因为存在相互独立、同分布于N(0,1)的随机变量X1,X2,…,Xn,使则6.2.2抽样分布2221,)(~),(~),(~212222122221221nnnn则niiX122)()(122niiXEE.2)(,),(~2222nDnEn)(则),(~22nniiXE12)(niinXD1)(由于Xi独立,且注意到N(0,1)的四阶矩为3,可得英国统计学家费歇(R.A.Fisher)曾证明,当n较大时,近似服从6.2.2抽样分布niiXDD122)()()(22n).1,12(nNniiiXEXE1224})]([)({nin12)13(2.t分布定义6.4设X~N(0,1),Y~2(n),X与Y独立,则称随机变量服从自由度为的t分布,又称为学生氏分布(Studentdistribution),记为T~t(n).可以证明t(n)的概率密度为图6-10t分布的概率密度曲线6.2.2抽样分布nYXTxnxnnnxfnt,1221)(212图6-10t分布的概率密度曲线显然t分布的概率密度是x的偶函数,图6-10描绘了n=1,3,7时t(n)的概率密度曲线.作为比较,还描绘了N(0,1)的概率密度曲线.6.2.2抽样分布xnxnnnxfnt,1221)(212可看出,随着n的增大,t(n)的概率密度曲线与N(0,1)的概率密度曲线越来越接近.可以证明t分布具有下面性质:即当n趋向无穷时,t(n)近似于标准正态分布N(0,1).一般地,若n30,就可认为t(n)基本与N(0,1)相差无几了.6.2.2抽样分布nexfxt,21)(223.F分布定义6.5设X~2(n1),Y~2(n2),且X与Y独立,称随机变量服从自由度为(n1,n2)的F分布,记为F~F(n1,n2).可以证明的概率密度函数为6.2.2抽样分布21nYnXF0,00,1222)(2212112221212111xxxnnnnxnnnnxfnnnnF6.2.2抽样分布图6-11F分布的概率密度曲线由F分布的定义容易看出,若F~F(n1,n2),则1/F~F(n2,n1).21nYnXF4.正态总体的抽样分布定理在数理统计问题中,正态分布占据着十分重要的位置,一方面因为在应用中,许多随机变量的分布或者是正态分布,或者接近于正态分布;另一方面,正态分布有许多优良性质,便于进行较深入的理论研究.因此,我们着重讨论正态总体下的抽样分布,给出有关最重要的统计量样本均值和样本方差S2的抽样分布定理.6.2.2抽样分布定理6.3设X1,X2,…,Xn为来自总体N(,2)的样本,,S2分别为样本均值和样本方差,则有(1)(2)(3)与S2相互独立;(4)证明:由正态分布的性质容易得到(1),略去(2)和(3)的证明,下面仅证明4.6.2.2抽样分布X);,(~2nNX;1~)1(222)(nSnX)1(~/ntnSX证明(4):由(1)知,从而由(2)(3)知根据t分布的定义6.2.2抽样分布);,(~)1(2nNX;1~)1()2(222)(nSn,2相互独立与SX)1(~/)4(ntnSX),(~2nNX,1~)1(222)(nSn)1,0(~/NnX)1(~/)1()1(/22ntnSXnSnnX相互独立;与2)3(SX【例6.5】某厂生产的灯泡寿命近似服从正态分布N(800,402),抽取16个灯泡的样本,求平均寿命小于775小时的概率.解:设灯泡寿命总体为X,因为X~N(800,402),n=16,所以样本均值故6.2.2抽样分布),1640,800(~2NX)100,800(~NX即1080077510800}775{XPXP0062.0)5.2(15.210800XP【例6.6】设总体X~N(,102),抽取容量为n的样本,样本均值记为.欲使与的偏差小于5的
 三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 扫描二维码
扫描二维码







 来学臭不要脸
来学臭不要脸
本文标题:62(统计量与抽样分布)
链接地址:https://www.777doc.com/doc-417140 .html