您好,欢迎访问三七文档
当前位置:首页 > 商业/管理/HR > 信息化管理 > 数据预处理(武汉大学-李春葆)
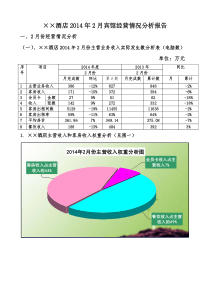
第3章数据预处理为什么要预处理数据数据清理数据集成和变换数据归约主要内容:数模题“公务员报考热”成为社会舆论关注的热门话题。几乎所有的国家机关和各省、市政府机关,以及公共事业单位都公开面向社会招聘公务员或工作人员,尤其是面向大中专院校的毕业生活动非常普遍。一般都是采取“初试+面试”的择优录用方法,特别是根据用人单位的工作性质,面试在招聘录取工作中占有突出的地位。某单位在一次招聘过程中,组成了一个5人专家小组,对101名通过初试者进行了面试,各位专家对每位初试者进行了打分(见附表),请你运用数学建模方法解决下列问题:(1)补齐表中缺失的数据,给出补缺的方法及理由。(2)给出101名初试者的录取顺序。(3)五位专家中哪位专家打分比较严格,哪位专家打分比较宽松。(4)你认为哪些初试者应给予第二次面试的机会。(5)如果第二次面试的专家小组只由其中的3位专家组成,你认为这个专家组应由哪3位专家组成。注:*表示专家有事外出未给初试者打分数据附表序号专家甲专家乙专家丙专家丁专家戊专家16873858886292697465833887676708048173849894583799583986846786566677676686486853966595949*977687641066938090731185958181691278669990711358867263811494847078861594818066921693669174971763749063921891798385841994956496952056679197562161807970692286967984752369906565762492858266682568*658487267166617594276174768778286380697684298668957184306483619096316085966787328284977860338892665995346091787881355997757688…………957464919479967055958369979394747385988583799571998163707995100868592877410192788570933.1为什么要预处理数据?现实世界的数据是“肮脏的”——数据多了,什么问题都会出现。不完整的:有些感兴趣的属性缺少属性值,或仅包含聚集数据。含噪声的:包含错误或者“孤立点”。不一致的:在编码或者命名上存在差异。没有高质量的数据,就没有高质量的挖掘结果。高质量的决策必须依赖高质量的数据。数据仓库需要对高质量的数据进行一致的集成。1.数据质量的多维度量一个广为认可的多维度量观点:精确度。完整度。一致性。合乎时机。可信度。附加价值。可访问性。跟数据本身的含义相关的内在的、上下文的、表象的。2.数据预处理的主要任务数据清理填写空缺的值,平滑噪声数据,识别、删除孤立点,解决不一致性。数据集成集成多个数据库、数据立方体或文件。数据变换规范化和聚集。数据归约得到数据集的压缩表示,它小得多,但可以得到相同或相近的结果。数据离散化数据归约的一部分,通过概念分层和数据的离散化来规约数据,对数字型数据特别重要。数据预处理的形式3.2数据清理主要任务:填充空缺的值、识别孤立点、消除噪声、并纠正数据中的不一致。3.2.1空缺值数据并不总是完整的例如:数据库表中,很多条记录的对应字段没有相应值,比如销售表中的顾客收入引起空缺值的原因设备异常与其他已有数据不一致而被删除因为误解而没有被输入的数据在输入时,有些数据因为得不到重视而没有被输入对数据的改变没有进行日志记载空缺值要经过推断而补上如何处理空缺值忽略元组:当类标号缺少时通常这么做(假定挖掘任务涉及分类或描述),当每个属性缺少值的百分比变化很大时,它的效果非常差。人工填写空缺值:工作量大,可行性低使用一个全局变量填充空缺值:比如使用unknown或-∞使用属性的平均值填充空缺值使用与给定元组属同一类的所有样本的平均值使用最可能的值填充空缺值:使用像Bayesian公式或判定树这样的基于推断的方法3.2.2噪声数据噪声:一个测量变量中的随机错误或偏差引起噪声数据的原因数据收集工具的问题数据输入错误数据传输错误技术限制命名规则的不一致如何处理噪声数据分箱(binning):首先排序数据,并将它们分到等深的箱中然后可以按箱的平均值平滑、按箱中值平滑、按箱的边界平滑等等聚类:监测并且去除孤立点计算机和人工检查结合计算机检测可疑数据,然后对它们进行人工判断回归通过让数据适应回归函数来平滑数据(1)数据平滑的分箱方法price的排序后数据(单位:美元):4,8,15,21,21,24,25,28,34划分为(等深的)箱:箱1:4,8,15箱2:21,21,24箱3:25,28,34用箱平均值平滑:箱1:9,9,9箱2:22,22,22箱3:29,29,29用箱边界平滑:箱1:4,4,15箱2:21,21,24箱3:25,25,34|4815||212124||252834|(4+8+15)/3=9(21+21+24)/3=22(25+28+34)/3=29(2)聚类通过聚类分析查找孤立点,消除噪声(3)回归xyy=x+1X1Y1Y1’3.3数据集成和变换任务:把数据转换成适合于挖掘的形式。3.3.1数据集成数据集成:将多个数据源中的数据整合到一个一致的存储中。模式集成:整合不同数据源中的元数据。实体识别问题:匹配来自不同数据源的现实世界的实体,比如:A.cust-id=B.customer_no。检测并解决数据值的冲突对现实世界中的同一实体,来自不同数据源的属性值可能是不同的。可能的原因:不同的数据表示,不同的度量等等。处理数据集成中的冗余数据集成多个数据库时,经常会出现冗余数据同一属性在不同的数据库中会有不同的字段名。一个属性可以由另外一个表导出,如“年薪”。有些冗余可以被相关分析检测到(A、B两个属性)BABAnBBAAr)1())((,B的均值B的标准差元组个数如果rA,B0,则A与B正相关,A的值随着B的值的增加而增加;如果rA,B0,则A与B负相关,A的值随着B的值的增加而减少;如果rA,B=0,则A与B独立。因此,|rA,B|很大时,A与B可以去除一个。3.3.2数据变换平滑:去除数据中的噪声(分箱、聚类、回归)聚集:汇总,数据立方体的构建数据概化:沿概念分层向上概化规范化:将数据按比例缩放,使之落入一个小的特定区间最小-最大规范化z-score规范化小数定标规范化属性构造通过现有属性构造新的属性,并添加到属性集中;以增加对高维数据的结构的理解和精确度1.最小-最大规格化对给定的数值属性A,[minA,maxA]为A规格化前的取值区间,[new_minA,new_maxA]为A规格化后的取值区间,最小-最大规格化根据下式将A的值v规格化为值v’AAAAAAvvnew_min)new_minnew_max(minmaxmin'假设某属性规格化前的取值区间为[-100,100],规格化后的取值区间为[0,1],采用最小-最大规格化66,得:83.00)01()100(100)100(66'v[-100,100][0,1]2.零-均值规格化对给定的数值属性A,、分别为A的平均值、标准差,零-均值规格化根据下式将A的值v规格化为值v’:AAAAvv'假设某属性的平均值、标准差分别为80、25,采用零-均值规格化66:56.0258066'v3.小数定标规范化jvv10'其中,j是使Max(|v’|)1的最小整数例如,假设属性A规格化前的取值区间为[-120,110],采用小数定标规格化66,A的最大绝对值为120,j为3,66规格化后为:066.01066'3v3.4数据归约任务:产生可以得到数据集的归约表示,并保持原数据的完整性。数据归约3.4.1数据立方体聚集将聚集操作用于数据立方体中的数据:汇总。最底层的方体对应于基本方体基本方体对应于感兴趣的实体在数据立方体中存在着不同级别的汇总数据立方体可以看成方体的格每个较高层次的抽象将进一步减少结果数据数据立方体提供了对预计算的汇总数据的快速访问使用与给定任务相关的最小方体在可能的情况下,对于汇总数据的查询应当使用数据立方体如何方便数据汇总:3.4.2维归约(属性归约)通过删除不相干的属性或维减少数据量。属性子集选择找出最小属性集,使得数据类的概率分布尽可能的接近使用所有属性的原分布。减少出现在发现模式上的属性的数目,使得模式更易于理解。删除部分不适合的属性。启发式的(探索性的)方法粗糙集理论在属性归约中有重要的应用。在后面介绍其方法。判定(决策)树方法能将所有记录分类3.4.3记录归约给定关系表、各个属性的概念层次树及属性阈值,面向属性归纳对各个属性进行如下处理:(1)根据属性A的概念层次树,将关系表中A的属性值转换为最低层的相应概念,也称为叶概念,统计关系表中属性A的不同叶概念个数,如果属性A的不同叶概念个数大于属性A的属性阈值,再根据属性A的概念层次树,将关系表中属性A的叶概念转换为上一层的相应概念。(2)如此重复,直至关系表中A的不同概念个数小于等于A的属性阈值;最后合并相同记录,并统计重复记录数目。例如,假设气温如表5.2所示,“地名”、“气温”属性的概念层次树分别如下所示。玉溪市宣威市云南省玉溪地区曲靖地区昆明市通海县五华区曲靖市安宁市气温表地名气温玉溪市18通海县18五华区17安宁市16曲靖市15宣威市14-40+~0-40+~40+0~40+-20~0-40+~-2020~40+0~20-40+~-30-30~-20-20~-10-10~00~1010~2020~3030~40+“气温”属性的概念层次树“地区”属性的概念层次树气温表地名气温玉溪市18通海县18五华区17安宁市16曲靖市15宣威市14面向属性归纳后气温表地名气温count玉溪地区10~202昆明市10~202曲靖地区10~202设属性阈值均为4,采用面向属性归纳进行记录归纳,气温如表5.3所示,记录由6个归约为3个,count的值表示重复记录数目3.4.4数值归约通过选择替代的、较小的数据表示形式来减少数据量有参方法:使用一个参数模型估计数据,最后只要存储参数即可。线性回归方法:Y=α+βX多元回归:线性回归的扩充对数线性模型:近似离散的多维数据概率分布无参方法:直方图聚类选样(1)直方图一种流行的数据归约技术。将某属性的数据划分为不相交的子集或桶,桶中放置该值的出现频率。桶和属性值的划分规则。等宽等深V-最优MaxDiff05101520253035401000030000500007000090000(2)聚类将数据集划分为聚类,然后通过聚类来表示数据集。如果数据可以组成各种不同的聚类,则该技术非常有效,反之如果数据界线模糊,则方法无效。数据可以分层聚类,并被存储在多层索引树中。聚类的定义和算法都有很多选择。(3)选样允许用数据的较小随机样本(子集)表示大的数据集对数据集D的样本选择:简单随机选择n个样本,不回放:由D的N个元组中抽取n个样本。简单随机选择n个样本,回放:过程同上,只是元组被抽取后,将被回放,可能再次被抽取。聚类选样:D中元组被分入M个互不相交的聚类中,可在其中的m个聚类上进行简单随机选择(mM)。分层选样:D被划分为互不相交的“层”,则可通过对每一层的简单随机选样得到D的分层选样。选样——SRS原始数据选样——聚类/分层选样原始数据聚类/分层选样3.5离散化和概念分层生成三种类型的属性值:名称型——e.g.无序集合中的值序数——e.g.有序集
 三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 扫描二维码
扫描二维码







 doreen303
doreen303
本文标题:数据预处理(武汉大学-李春葆)
链接地址:https://www.777doc.com/doc-4175263 .html