您好,欢迎访问三七文档
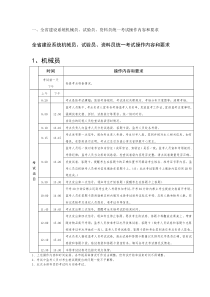
1.6某台主频为400MHz的计算机执行标准测试程序,程序中指令类型、执行数量和平均时钟周期数如下:指令类型指令执行数量平均时钟周期数整数450001数据传送750002浮点80004分支15002求该计算机的有效CPI、MIPS和程序执行时间。解:(1)CPI=(45000×1+75000×2+8000×4+1500×2)/129500=1.776(或259460)(2)MIPS速率=f/CPI=400/1.776=225.225MIPS(或2595180MIPS)(3)程序执行时间=(45000×1+75000×2+8000×4+1500×2)/400=575s1.7将计算机系统中某一功能的处理速度加快10倍,但该功能的处理时间仅为整个系统运行时间的40%,则采用此增强功能方法后,能使整个系统的性能提高多少?解由题可知:可改进比例=40%=0.4部件加速比=10根据Amdahl定律可知:5625.1104.04.011系统加速比采用此增强功能方法后,能使整个系统的性能提高到原来的1.5625倍。2.11某台处理机的各条指令使用频度如下表所示:指令使用频度指令使用频度指令使用频度ADD43%JOM6%CIL2%SUB13%STO5%CLA22%JMP7%SHR1%STP1%请分别设计这9条指令操作码的哈弗曼编码、3/3/3扩展编码和2/7扩展编码,并计算这3种编码的平均码长。解:根据给出的九条指令的使用频度和哈弗曼生成算法的结构的不用构造了两种不同的哈夫曼树。(左边为A,右边为B)各编码如下:由表可知,三种编码的平均码长为:(公式:L=∑Pi*Li)哈弗曼编码:2.42位3/3/3编码:2.52位2/7编码:2.70位平均码长:2*43%+2*22%+4*(1-43%-22%)=2.72.12.某机指令字长16位。设有单地址指令和双地址指令两类。若每个地址字段为6位.且双地址指令有X条。问单地址指令最多可以有多少条?解:双地址指令结构为:(4位操作码)(6位地址码)(6位地址码)单地址指令结构为:(10位操作码)(6位地址码)因此,每少一条双地址指令,则多2^6条单地址指令,指令IiPi哈弗曼A哈弗曼B3/3/32/7ADDI10.43000000CLAI20.22101000101SUBI30.13110101101000JMPI40.0711100110011001001JOMI50.0611101110111011010STOI60.0511110111011101011CILI70.02111110111101111001100SHRI80.0111111101111101111011101STPI90.0111111111111111111101110双地址指令最多是2^(16-6-6)=2^4=16条,所以单地址指令最多有(16-X)*2^6条。2.13.若某机要求:三地址指令4条,单地址指令255条,零地址指令16条。设指令字长为12位.每个地址码长为3位。问能否以扩展操作码为其编码?如果其中单地址指令为254条呢?说明其理由。解:(1)不能用扩展码为其编码。指令字长12位,每个地址码占3位,三地址指令最多是2^(12-3-3-3)=8条,现三地址指令需4条,所以可有4条编码作为扩展码,而单地址指令最多为4×2^3×2^3=2^8=256条,现要求单地址指令255条,所以可有一条编码作扩展码因此零地址指令最多为1×2^3=8条不满足题目要求,故不可能以扩展码为其编码。(2)若单地址指令254条,可以用扩展码为其编码。依据(1)中推导,单地址指令中可用2条编码作为扩展码,零地址指令为2×2^3=16条,满足题目要求3.6有一指令流水线如下所示入1234出50ns50ns100ns200ns(1)求连续输入10条指令,该流水线的实际吞吐率和效率;(2)该流水线的“瓶颈”在哪一段?请采取两种不同的措施消除此“瓶颈”。对于你所给出的两种新的流水线,连续输入10条指令时,其实际吞吐率和效率各是多少?解:(1)2200(ns)2009200)10050(50t)1n(tTmaxm1iipipeline)(ns2201TnTP1pipeline45.45%1154400TPmtTPEm1ii(2)瓶颈在3、4段。变成八级流水线(细分)850(ns)509850t1)(ntTmaxm1iipipeline)(ns851TnTP1pipeline58.82%17108400TPmtiTPEm1i重复设置部件)(ns851TnTP1pipeline58.82%1710885010400E3.7有一个流水线由4段组成,其中每当流经第3段时,总要在该段循环一次,然后才能流到第4段。如果每段经过一次所需要的时间都是t,问:(1)当在流水线的输入端连续地每t时间输入任务时,该流水线会发生什么情况?(2)此流水线的最大吞吐率为多少?如果每t2输入一个任务,连续处理10个任务时的实际吞吐率和效率是多少?(3)当每段时间不变时,如何提高该流水线的吞吐率?仍连续处理10个任务时,其123-13-24-14-24-34-4123_13_24_14_4入出50ns50ns50ns50ns50ns50ns123_13_24_14_24_34_411112222333344445555666677778899101089108910850ns时间段吞吐率提高多少?解:(1)会发生流水线阻塞情况。第1个任务S1S2S3S3S4第2个任务S1S2stallS3S3S4第3个任务S1stallS2stallS3S3S4第4个任务S1stallS2stallS3S3S4(2)54.35%925045TPE2310TnTp23T21TPpipelinepipelinemaxtttt(3)重复设置部件tt751410TnTPpipeline段时间12341111122222333334444455555666667777788888999991010101010t23123_13_24ΔtΔtΔtΔtΔt段时间1123_13_24111122222333334444455555666667777788888999991010101010t14吞吐率提高倍数=tt231075=1.643.8有一条静态多功能流水线由5段组成,加法用1、3、4、5段,乘法用1、2、5段,第3段的时间为2△t,其余各段的时间均为△t,而且流水线的输出可以直接返回输入端或暂存于相应的流水寄存器中。现要在该流水线上计算,画出其时空图,并计算其吞吐率、加速比和效率。解:首先,应选择适合于流水线工作的算法。对于本题,应先计算A1+B1、A2+B2、A3+B3和A4+B4;再计算(A1+B1)×(A2+B2)和(A3+B3)×(A4+B4);然后求总的结果。其次,画出完成该计算的时空图,如图所示,图中阴影部分表示该段在工作。由图可见,它在18个△t时间中,给出了7个结果。所以吞吐率为:tTP817如果不用流水线,由于一次求积需3△t,一次求和需5△t,则产生上述7个结果共需(4×5+3×3)△t=29△t。所以加速比为:该流水线的效率可由阴影区的面积和5个段总时空区的面积的比值求得:5.1解释下列术语指令级并行:简称ILP。是指指令之间存在的一种并行性,利用它,计算机可以并行执行两12345乘法加法△t△t2△t△t△t)(41iiiBA时间段12345012345678910111213141516输入A1B1A2B2A3B3A4B4ABCDABCDA×BA×BC×DA×B×C×DA=A1+B1B=A2+B2C=A3+B3D=A4+B4C×D171861.18192ttS223.01853354E条或两条以上的指令。指令调度:通过在编译时让编译器重新组织指令顺序或通过硬件在执行时调整指令顺序来消除冲突。指令的动态调度:是指在保持数据流和异常行为的情况下,通过硬件对指令执行顺序进行重新安排,以提高流水线的利用率且减少停顿现象。是由硬件在程序实际运行时实施的。指令的静态调度:是指依靠编译器对代码进行静态调度,以减少相关和冲突。它不是在程序执行的过程中、而是在编译期间进行代码调度和优化的。保留站:在采用Tomasulo算法的MIPS处理器浮点部件中,在运算部件的入口设置的用来保存一条已经流出并等待到本功能部件执行的指令(相关信息)。CDB:公共数据总线。动态分支预测技术:是用硬件动态地进行分支处理的方法。在程序运行时,根据分支指令过去的表现来预测其将来的行为。如果分支行为发生了变化,预测结果也跟着改变。BHT:分支历史表。用来记录相关分支指令最近一次或几次的执行情况是成功还是失败,并据此进行预测。分支目标缓冲:是一种动态分支预测技术。将执行过的成功分支指令的地址以及预测的分支目标地址记录在一张硬件表中。在每次取指令的同时,用该指令的地址与表中所有项目的相应字段进行比较,以便尽早知道分支是否成功,尽早知道分支目标地址,达到减少分支开销的目的。前瞻执行:解决控制相关的方法,它对分支指令的结果进行猜测,然后按这个猜测结果继续取指、流出和执行后续的指令。只是指令执行的结果不是写回到寄存器或存储器,而是放到一个称为ROB的缓冲器中。等到相应的指令得到“确认”(即确实是应该执行的)后,才将结果写入寄存器或存储器。ROB:ReOrderBuffer。前瞻执行缓冲器。超标量:一种多指令流出技术。它在每个时钟周期流出的指令条数不固定,依代码的具体情况而定,但有个上限。超流水:在一个时钟周期内分时流出多条指令。超长指令字:一种多指令流出技术。VLIW处理机在每个时钟周期流出的指令条数是固定的,这些指令构成一条长指令或者一个指令包,在这个指令包中,指令之间的并行性是通过指令显式地表示出来的。循环展开:是一种增加指令间并行性最简单和最常用的方法。它将循环展开若干遍后,通过重命名和指令调度来开发更多的并行性。7.9假设在3000次访存中,第一级Cache失效110次,第二级Cache失效55次。试问:在这种情况下,该Cache系统的局部失效率和全局失效率各是多少?解第一级Cache的失效率(全局和局部)是110/3000,第二级Cache的局部失效率是55/110,第二级Cache的全局失效率是55/3000,7.10给定以下的假设,试计算直接映象Cache和两路组相联Cache的平均访问时间以及CPU的性能。由计算结果能得出什么结论?(1)理想Cache情况下的CPI为2.0,时钟周期为2ns,平均每条指令访存1.2次;(2)两者Cache容量均为64KB,块大小都是32字节;(3)组相联Cache中的多路选择器使CPU的时钟周期增加了10%;(4)这两种Cache的失效开销都是80ns;(5)命中时间为1个时钟周期;(6)64KB直接映象Cache的失效率为1.4%,64KB两路组相联Cache的失效率为1.0%。解:平均访问时间=命中时间+失效率×失效开销平均访问时间1-路=2.0+1.4%*80=3.12ns平均访问时间2-路=2.0*(1+10%)+1.0%*80=3.0ns两路组相联的平均访问时间比较低CPUtime=(CPU执行+存储等待周期)*时钟周期CPUtime=IC(CPI执行+总失效次数/指令总数*失效开销)*时钟周期=IC((CPI执行*时钟周期)+(每条指令的访存次数*失效率*失效开销*时钟周期))CPUtime1-way=IC(2.0*2+1.2*0.014*80)=5.344ICCPUtime2-way=IC(2.2*2+1.2*0.01*80)=5.36IC相对性能比:1waytime2waytimeCPUCPU5.36/5.344=1.003直接映象cac
 三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 扫描二维码
扫描二维码








 灵刃风舞
灵刃风舞
本文标题:体系结构
链接地址:https://www.777doc.com/doc-4285855 .html