您好,欢迎访问三七文档
当前位置:首页 > 商业/管理/HR > 质量控制/管理 > 预测预报的数据处理与统计分析
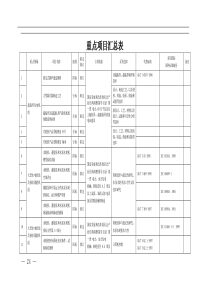
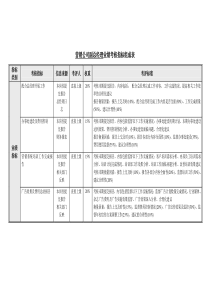
预测预报的数据处理与统计分析第四章预报模型的组建病虫害的预测预报从内容上可以分为两大类;第—类为生物学预测法,如有效积温法,期距法、发育进度预测法、生物气候图法、聚点图法、增殖系数预测法、经验指数法、形态指标预测法、物候预测法等;第二类为数理统计预测法,如相关回归预测法、判别分析法,时间序列法、动力学预测法等多种数理统计预测方法。数理统计预测方法就是通过对病虫害发生情况调查的历史资料进整理和分析,利用统计学的原理,找出病虫害发生与环境之间以及病虫害自身发生变化的规律性,组建起数理统计模型,然后根据当前病虫害发生和环境因子的现状,来预报未来病虫害发生的情况。数理统计预测要有多年的系统资料,选择其中相关部分进行统计分析,建立预测预报适用的数学模型,才能加以运用。因此系统资料对建立数学模型的关系很大,必须经过精挑细选,才能得到昀优化的数学模型。统计预测模型不同于一般的数学模型,数学模型所使用的方程式能够反映自变量与因变量之间的函数关系,而统计预测模型反映的是自变量与因变量的随机统计关系,不是函数关系,表现在统计模型比数学模型多一个随机误差项。常用的数理统计学方法有相关分析、回归分析、聚类分析、判别分析、时间序列分析等。第一节相似性分析预测相似性分析预测是依据预报年获得的预报因子数据,分别与历史上实测资料中相应的因子进行比较,找出相似年,用统计方法分析判断,发布病虫预报的方法。一、相关系数法【例4-1】某地区测报站用该法预测第一代玉米螟卵峰期,其运算步骤如下。1资料处理一代玉米螟卵峰期(月/日)为预报量y,5月份平均温度(℃)为预报因子x1,越冬代幼虫化蛹初盛期(月/日)为预报因子x2。设卵峰期以6月10日=0,即6月11日为1,6月12日为2,…。越冬幼虫化蛹初盛期以5月31日为起点计算天数,5月31日为0,6月1日为1,6月2日为2,…,5月30日为-1,5月29日为-2,…。见表4-1。表4-1年序1234567891011y6521587167141216x118.116.717.415.219.117.416.418.815.516.317.1x2-63-3710145171414(本数据保存在data4_1.xls)92预报模型的组建2计算相关系数运行Excel,把表4-1数据输入到工作表中。在Excel中用相关系数函数(CORREL)计算相关系数r,=CORREL(y的数据区,x的数据区)计算得到rx1y=0.7224rx2y=0.84823相关系数的显著性检验相关系数的显著性检验科可用t检验,t统计量的计算公司为:()()22122/1rnrnrrsrtr−−=−−==查t表,当tt0.05,n-2,说明x与y相关显著;当tt0.01,n-2,说明x与y相关极显著;当tt0.05,n-2,说明x与y无显著相关。本例自由度:11-2=9,根据r值计算得到:|tx1y|=3.13,|tx1y|=4.08。在Excel中用函数“TINV”求得:t0.05,n-2=2.26,t0.01,n-2=3.25。tx1yt0.05,9,tx2yt0.01,9。表明x1,x2与y之间均存在显著性的线性关系。4预报预报年的预报因子x1是16.5(五月平均温度)、x2是4(越冬幼虫初孵盛期6月4日)。①列出相似年:与x1相距昀近的有2、7、10;与x2相距昀近的有2、8。②计算相似度:把与预报因子x1、x2相似年的相关系数的绝对值添入表3-2中,再计算相似年的相似度(rx1y+rx2y),将结果填入表3-2。表3-2相似年27810x10.72240.72240.7224x20.84820.8482相似度1.57060.72240.84820.7224③计算预报值在表3-2中取相似度较大的相似年2、8年y值的平均数作为预报值:yˆ=(y2+y8)/2=(5+7)2=6预报值6,根据上述分级原则,6月10日为0,则10+6=16,即可预报为第一代玉米螟卵峰期为6月16日。二、相似评分法将预报量有关的各因子与历史上相应的各因子之间作相似性评分。各因子得分高说明与预报93预测预报的数据处理与统计分析对象相似性好,即各因子的级别与预报对象的级别相关性好。【例4-2】某地预报对象棉铃虫第四代百株卵量(y)与5个有关因子:第一代基数(x1)、第二代基数(x2)、第三代基数(x3)、7月份雨量(x4)、7月份气温(x5)有关,并都将之划分为4级(也可划分为5级)。按年份排列在下表。共有历史资料17年,现预报第18年的第四代卵量。1计算相似得分预报年(第18年)5个因子的分级数依次为4、4、4、3、4,将它们分别与历史上各年相应因子的级别对比,评定出相似得分数。本例规定凡与预报年相同级的得2分,差1级的得1分,差2级的得0分,差3级的得-2分(评分的标准可以酌情自定)。例如历史上x1第1年为4级,与预报年x1因子4级相同,故第1年x1得相似分数2分;x1第2年为2级,与预报年x1相差2级,故第2年x1得0分;依此类推记入表4-3。在Excel(data4_2.xls)中可用下式计算各历史年得分:=IF(C2=x’,2,IF(ABS(C2-x’)=1,1,IF(ABS(C2-x’)=2,0,-2)))式中x表示历史年分级数单元格,为相对引用;x’表示预报年因子级数,为常量。例如(计算x1得分:=IF(E2=4,2,IF(ABS(E2-4)=1,1,IF(ABS(E2-4)=2,0,-2)))总的计算的得分情况见表4-3。表4-3预报因子的分级和相似得分情况x1x2x3x4x5年序y得分得分得分得分得分得分和1442424241429222031202131334424242414294431424241428522042201020262424242321-267120201-2321-2-283311-242324259342314241428103423131322061111-2421-21031-112442424241429132202042324261411-21-21-2321-2-615331313132316163314231324281711-2311-21042-118(预报年)44434(本例保存在data4_2.xls)94预报模型的组建2计算得分和在计算得到各个因子的得分后,再将每年的各个因子相似得分数求和,记入“得分和”栏,它表示每年与预报年的相似程度。3预报从表4-3中看出,第1、3、12年份的“得分和”值昀大(为9分),表示这3年与预报年相似程度昀大。再查看这3年对应y的级数都为4级,因此可以预测预报年的发生级为4级。如果昀相似的n年中的y值不等,则可依据大多数年的y级数来预报,或者取其平均级数来预报。以上的评分标准是要求完全相等的为满分,故是一种线性的相关关系。但在确定评分标准和具体作评分时还是应该注意某些因子x与y间是非线性相关关系。如x为1级时,y为2级;x为2级时,y为4级,这也是很好的对应关系。实际上这是一种非线性关系。如有这种情况,在评分规则中也应反映出来。另外,预测因子间的分级数也不一定要求完全相同,可以在评分规则中加以协调。如果预测因子与预测对象之间的机理关系尚不明确时,则应多选几个因子来参加评定,避免某些偶然巧合的误差出现。三、相似性的量化计算图4-11相似系数(cosθ)在图(4-1)上横轴x1,和纵轴x2组成的直角坐标上有两个点a(xla,x2a)和b(x1b,x2b)把oa和ob看成是两个矢量,它们之间的夹角为ab的余弦是:222122212211cosbbaababaabxxxxxxxx+++=θ∑∑∑====21221221iibiiaiibiaxxxx用上式来衡量ad两个年份的相似性,预报因子为两个xl、x2。a年因子的取值是xla、x2a,b年的取值为xlb、x2b。它们的相似程度可用两矢量之间的夹角的余弦cosθab来度量。cosθab在-1~1之间。当cosθab=1时,θ=0o,表示两年度很相似(但不一定相等);当cosθab=0时,θ=90o,表示两年间不相似;当cosθab=-1时,θ=180o,则两者呈相反关系。因此取0~1之间作比较。如果有m个因子,即x1、x2、…、xm,则公式应改为:∑∑∑====miibmiiamiibiaabxxxx212121cosθ95预测预报的数据处理与统计分析【例4-3】某站用7个因子预测棉铃虫第四代卵量共18年资料,用第19年(预报年)相对应7个因子资料对历史资料作相关相似分析,己获得预报年与第7年以及第10年昀相似。现对这两年用相似性系数作进一步量化比较。具体计算过程在Excel中进行(见data4_3.xls),计算结果见表4-4。表4-4a(预报年)b(第7年)c(第10年)因子x1ax21ax1bx21bx1ax1bx1cx21cx1ax1cx16364162441624x26365253052530x324112396x463624123918x524396244x61141645255x763639182412合计15380969299平方根12.378.949.59相似系数0.870.83(保存在data4_3.xls文件中)计算相似系数cosθab=96/(12.37×8.94)=0.87cosθac=99/(12.37×9.59)=0.83可见预报年与第7年的相似系数昀大,可以把第7年y发生级作为预报级。2距离系数D两个年份a、b的两个因子数值(xla、x2a)和(xlb、x2b)在座标图4-1上所形成的a、b两点。除用上述cosθ来作度量外,还可用两点间的距离来度量,当两点越靠近,即因子的数值越接近,则两年份的预报量越相似。度量两点间的距离用直角三角形求边定律公式计算:∑=−=−+−=′212222211)()()(iiaibababbaxxxxxxD如果因子有m个,则有:∑=−=′miiaibbaxxD12)(由于此式D受因子数目的影响。因此,要完善地表示两个年份之间的相似程度,宜采用距离系数。∑=−=miiaibbaxxmD12)(196预报模型的组建Dab越小则ab越相似。Dab=0则两者完全相等。Dab与m有关,是m的函数,故又称为距离函数。仍用以上例子中预测年a与关系密切的历史第7年b和第12年c相比较,计算过程在Excel中进行(data4_4.xls),计算结果见表4-5。表4-5a(预报年)b(第7年)c(第10年)因子x1ax1bx1b-x1a(x1b-x1a)2x1cx1c-x1a(x1c-x1a)2x164-244-24x265-115-11x321-11311x462-4163-39x52311200x614395416x763-392-416合计4147平均5.866.71距离系数2.422.59根据表中数据可得:42.2741==baD59.2747==caD由此可见,第7年的距离系数昀小,可以根据第7年y的级数来预测预报年的级数。相似分析法可做发生期、发生量的预报。该方法运用了群众中利用相似预报的经验,结合统计方法发预报,一般是有效的、可行的。但要求至少积累10年以上的数据。资料越多,可比较的相似年越多,预报效果也越好。第二节回归分析相关分析只能说明变量间(x,y)相互关系的程度和方向。而回归分析是要建立数学表达式来描述x与y之间关系的一种统计方法。x表示自变量,是固定独立的,一般是实验时预先设定的,没有误差或误差很小;y表示依存变量或称因变量,它随自变量x的变化而随机变动,因而存在随机误差。在确定独立自变量和依存变量的基础上,建立y与x的回归方程式,就可以确定当x为某—值时,y将会在什么范围内变动。这种分析方法称之为回归分析。一、一元线性回归模型一元线性回归模型:ebxay++=式中是回归直线在y轴上的截距;b为回归直线的斜率,即回归系数。e是回归误差。a【例4-4】湖北省汉阳县历年越冬代二化螟发蛾盛期与当年三月上旬平均气温的数据如表4-6,分析三月上旬平均温度与越冬
 三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 扫描二维码
扫描二维码








 26525557
26525557
本文标题:预测预报的数据处理与统计分析
链接地址:https://www.777doc.com/doc-4855936 .html