您好,欢迎访问三七文档
当前位置:首页 > 商业/管理/HR > 经营企划 > SPSS数据的基本统计分析
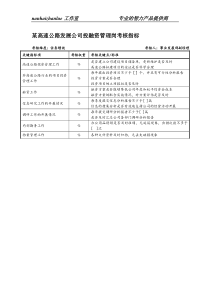
SPSS基本统计分析单变量的频数分析单变量的基本描述统计量的计算多变量的交叉频数表的编制和分析探索性分析数据的多选项分析1.频数分析通过频数分析能够了解变量取值的状况,把握数据的分布特征,能反映样本是否具有总体代表性,抽样是否存在系统偏差等。频数分布分析过程(1)程序:分析(analyze)-描述统计(descriptive)-频数(frequency)(2)选择一个或多个频数分析变量放进‘变量’框中(3)选中右下角‘显示频数表格’(4)点击‘统计量’、‘图表’、‘格式’依次进行设置源变量框待分析变量要求输出频数分析表格选择统计量选择图表选择输出格式•制作频数分布表(频数、百分比):以表格形式呈现各个数据的次数分布情况,包括频数、百分比,有效百分比、累计百分比。百分位数选项第25、50、75个百分位数点对应的变量值把数值平均分为n份,每个等分位点对应的变量值(2≤n≤100)指定输出多个百分位数数据分布形态的偏斜度和方向数据分布形态的陡缓程度离散趋势测量集中趋势测量对于分组数据,计算百分位数值和中位数时,用各组的组中值代表各组数据。分位数是变量在不同分位点上的取值,从一个侧面清楚地刻画了变量的取值分布状态。分位数差是一种描述数据离散程度的方式。分位数差越大,表示数据在相应分位段上的离散程度越大。峰度(Kurtosis):是描述某变量所有取值的分布形态陡缓程度的统计量,而峰度对陡缓程度的度量是与正态分布进行比较的结果。如果峰度等于0,其数据分布的陡缓程度与正态分布相同;峰度大于0,其数据分布比正态分布更陡峭;峰度小于0,其数据分布比正态分布更平坦。偏度(Skewness):是描述数据分布对称性的统计量,而且也是与正态分布的对称性相比较而得到的。如果分布的偏度等于0,则其数据分布的对称性与正态分布相同;如果偏度大于0,则其分布为正偏或右偏;如果偏度小于0,则为负偏或左偏。集中趋势Centraltendency(一组数据向某一中心靠拢的倾向)离散趋势Dispersion(一组数据远离其‘中心值’的程度)定类众数Mode异众比率V定序中位数Median四分位差Quartiles定距定比均值Mean全距Range方差Variance标准差Std.deviant不同等级的变量描述性指标均值:某变量所有取值的平均水平,其大小易受到数据中极端值的影响。众数Mode:是一组数据中出现次数最多的数据。中位数Median:一组数据按升序排序后处于中间位置的数据。均值标准误差:是描述样本均值与总体均值之间差异程度的统计量。标准差:反映变量取值距离均值的平均离散程度。其值越大,变量间的差异越大。方差:是标准差的平方,反映变量取值离散程度。其值越大,变量间的差异越大。全距range:也称为极差,是数据最大值与最小值之间的绝对差,也是反映变量取值的离散程度。对称分布均值=中位数=众数右偏众数中位数均值左偏均值中位数众数直方图:是用矩形的面积来表示频数分布变化的图形。适用于连续性数据,即:定距数据条形图、饼图:适用于离散型数据,即定序、定类和分组后的定距数据。其中,条形图(barchart)是用宽度相同的条形的高度或长短来表示频数分布变化的图形;饼图(piechart)是用圆形或圆内扇形的面积来表示频数分布变化的图形。不输出任何图形输出条形图输出饼图直方图输出正态分布曲线案例分析:居民储蓄调查数据目标一:分析储户的户口和职业的基本情况;目标二:分析储户一次存(取)款金额的分布,并对城镇储户和农村储户进行分析比较。目标一:被调查者的户口和职业情况的频数分布表和统计图目标二:分析储户一次存(取)款金额的分布,并对城镇储户和农村储户进行分析比较。分析思路:由于存(取)款金额属于定距型变量,直接采用频数分析不利于对分布形态的把握。运用数据预处理中的‘数据分组’功能对数据分组后再编制频数分布表。如:将(取)款金额重新分成5组:少于500元、500-2000、2000-3500、3500-5000、5000以上。对比城镇储户和农村储户情况,可采用数据预处理中的‘数据拆分’并计算样本存(取)款金额的四分位数、峰度、偏度等。储户一次存(取)款金额的分布情况:被调查者有近一半的储户一次存取款金额在500元以下,2000-3500元的最少。从图形看来,储户的存(取)款金额呈明显的右偏分布,即一次存取款金额偏低的占较大比例,也有少数金额偏高的储户。城镇和农村居民储户一次存(取)款金额的比较:从均值以及四分位数差可以看出城镇储户存取款金额的离散度大于农村储户(尤其在高金额区),且城镇储户的存取款金额高于农村储户。基本的描述性统计量大致有三类:一是刻画集中趋势的描述统计量;二是刻画离散程度的描述统计量;三是刻画分布形态的描述统计量。通过以上三类统计量能较为准确地把握数据的分布特点。基本的描述统计分析过程:(1)程序:分析(analyze)-描述统计(descriptivestatistics)-描述(descriptive)(2)选择要描述的一个或多个数值型变量(3)点击‘选项’按钮,做二级对话框设置(4)选中右下角‘标准化得分保存为变量’可将数据标准化后的取值保存到数据文档中。2.基本描述性统计分析对数据标准化,并作为新变量保存在文件中。uxiiZ案例分析:居民储蓄调查数据目标一:计算存(取)款金额的基本描述统计量,并分别对城镇储户和农村储户进行比较;目标二:分析储户一次存(取)款金额的数量是否存在不均衡现象。目标一的分析结果:城镇储户的平均存取款金额(2687.2)高于农村储户(1944.97);从标准差及全距可看出,城镇储户存取款金额的离散程度低于农村储户。从峰度和偏度看来,城镇和农村储户存取款金额的分布均呈现右偏和尖峰分布,只是农村储户右偏斜程度及尖峰程度更大;总体而言,城镇储户和农村储户中的大部分人一次存取款金额都低于平均水平,且农村储户表现得更为明显。分析储户一次存(取)款金额的数量是否存在不均衡现象,可以从分析金额是否有大量的异常值入手。一般而言,若储户存取款金额服从正态分布,那么根据3σ准则(3个标准差准则),异常值通常为3个标准差之外的变量值。可通过数据的标准化处理来判断。(先标准化,再依据标准化值分组,后用频数分析)目标二的分析思路:从频数分析可得,低异常组占比0%,高异常组占比2.6%。一般认为异常组的总比例大于理论值0.3%,可以认为存取款金额存在一定的不均衡现象。交叉分组下的频数分析又称为列联表分析。主要包括两大基本任务:一是根据收集到样本数据产生交叉列联表;二是在交叉列联表的基础上,对两两变量间是否存在一定的相关性进行分析。交叉列联表是两个或两个以上的变量交叉分组后形成的频数分布表。程序:分析(analyze)-描述统计(descriptivestatistics)-交叉表(crosstable)3.交叉分组下的频数分析—列联表分析行变量(自变量)的选取列变量(因变量)的选取显示每组变量的条形分类图相关统计量的计算输出表格的形式表格排列顺序分层变量(控制变量)的选取不输出列联表测量级别相关系数取值范围PRE意义检验方法SPSS程序类-类(类-序)λ[0.1]λχ2crosstabs序-序G/rs[-1.1]G/rs2T检验Crosstabs/correlation类\序-距(≥3)E/E2[0.1]E2F检验crosstabs/Oneway/means距-距r[-1.1]r2T检验crosstabs/correlation/linear相关分析的概念定类变量定序变量λE系数类-距G相关进行分层卡方检验得到相对风险测评的OR值选中进行配对卡方检验一致性检验。(行列变量的数目相同)当Kappa≥0.75时,表明两者一致性较好;0.75Kappa≥0.4时,表明一致性一般;Kappa0.4时,表明两者一致性较差。计算r和rs系数.相关性检验观测频数期望频数行百分比列百分比总百分比频数案例分析:居民储蓄调查数据目标一:分析城镇和农村储户‘对未来两年内收入状况的变化趋势’是否持相同的态度;目标二:分析城镇和农村储户‘对储蓄是否合算’的认同是否一致;目标一的分析结果从总样本看来认为未来收入会增加、不变、减少的样本比重分别为24.6%、63.6%、11.8%;其中城镇储户认为未来收入会不变的占比较高(62.8%),农村储户认为收入会不变的占比也较高(65.6%)且认为收入会减少的比例(21.1%)高于会增加的比例(13.3%);但认为收入会增加的样本中,城镇储户和农村储户占比分别为84.4%和15.6%;认为收入不变的样本中,城镇储户和农村储户占比分别为70.4%和29.6%;认为会减少的样本中,城镇储户和农村储户占比分别为48.6%和51.4%。总体而言,较大部分储户认为未来收入会基本不变且认为收入会增加的比例高于会减少的比例;城镇储户认为收入会增加的比例高于会减少的比例,但农村储户认为收入会增加的比例低于会减少的比例。可见,城镇和农村储户对’未来收入情况‘的看法上存在分歧。‘城镇和农村储户对未来收入看法’的一致性检验结果卡方检验的零假设:城镇和农村储户对未来收入的看法是一致的。备择假设:二者不一致。从本例的统计量15.819,sig值0.000,可看出:在5%的水平下,城镇和农村储户对未来收入的看法是不一致的。注意:当样本数较大时,似然比卡方与Pearson卡方非常接近,检验结论通常是一致的。线性相关卡方是检验列联表中行列变量的线性相关性,零假设是行列变量零相关,只适用于定序变量,不能用于定类型变量。目标二的分析结果从交叉列联表看来,无论是城镇储户还是农村储户均认为‘买东西’比‘存钱’合算。卡方检验的统计量0.504,sig值0.478,可看出:在5%的水平下,城镇和农村储户对储蓄是否合算的看法是一致的。对于2×2列联表中行列变量关系的检验,SPSS除用Pearson统计量进行检验之外,还采用了连续性校正和Fisher检验方法。在小样本时可主要参考连续性校正和Fisher检验的结果。SPSS中列联表分析的其他方法—两定类变量案例分析:分析城镇和农村储户‘对储蓄是否合算’的认同是否一致。从检验结果表看来,Phi系数(ψ)、Cramer’V系数、(列联系数Contingencycoefficient)相依系数绝对值越接近1,表明行列变量有较强的相关关系;越接近0,表明行列变量相关性越弱。零假设:行列变量独立的假设(城镇和农村储户对未来收入的看法是一致的)。备择假设:二者不一致。统计量0.040,sig值0.478,可看出:在5%的水平下,城镇和农村储户对储蓄是否合算的看法是一致的。SPSS中列联表分析的其他方法—两定序变量案例分析:分析储户收入水平和对物价水平看法的相关性分析。定序变量相关性检验的方法有:Gamma系数、Somres’d系数、Kendall’stau-b系数、Kendall’stau-c系数、Gamma系数。一般认为系数绝对值越接近1,表明行列变量有较强的相关关系;越接近0,表明行列变量相关性越弱。其中,Kendall’stau-b系数通常适用于‘方形列联表’;Kendall’stau-c系数通常用于‘任意格数的列联表’;Gamma系数通常用于2×2的列联表。本例运用Kendall’stau-c系数进行检验得到的统计量0.137,转换后的系数近似服从T分布,最后得到sig值0.003,可看出:在5%的水平下,储户收入水平和对物价水平的看法是有关系的,只是关系相对较弱。SPSS中列联表分析的其他方法—一定类、一定距变量案例分析:分析不同户口与一次存(取)款金额的相关性检验。一定类、一定距变量的相关性检验的方法是:Eta系数。其思想类似于单因素方差分析。Eta系数越接近1,表示两变量的相关性越强。本例第一行是以存取款金额为控制变量,户口为观测变量(因变量)的分析结果,表示存取款金额对户口的解释能力;本例第二行是以为户口控制变量,存取款金额为观
 三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 扫描二维码
扫描二维码








 suxingmomo
suxingmomo
本文标题:SPSS数据的基本统计分析
链接地址:https://www.777doc.com/doc-5009398 .html