您好,欢迎访问三七文档
当前位置:首页 > 商业/管理/HR > 广告经营 > 信息论与编码之数据压缩
信息论与数据压缩班级姓名数据压缩的含义与简介01理论与应用03类型与流行算法04算法编码05内容大纲概要与原理02信息论在数据压缩技术中的应用数据压缩作为信息论研究中的一项内容,主要是有关数据压缩比和各种编码方法的研究,即按某种方法对源数据流进行编码,使得经过编码的数据流比原数据流占有较少的空间。数据压缩的主要目的是力求用最少的数据表示信源所发出的信号,使信号占用的存储空间尽可能小,以达到提高信息传输速度的目的。数据压缩在近代信息处理问题中有大量的应用,无论在数据存储或传送中,通过数据压缩不仅可以大大节省资源利用的成本,而且把一些原来无实用意义的技术,如多媒体技术中的一些问题,达到具有实用意义的标准。数据压缩技术的不断完善是依靠在信息论这门学科的成长上的,信息能否被压缩以及能在多大程度上被压缩与信息的不确定性有直接的关系,人工智能技术将会对数据压缩的未来产生重大影响。数据压缩的含义与简介含义:数据压缩是指在不丢失有用信息的前提下,缩减数据量以减少存储空间,提高其传输、存储和处理效率,或按照一定的算法对数据进行重新组织,减少数据的冗余和存储的空间的一种技术方法。简介:在计算机科学和信息论中,数据压缩或者源编码是按照特定的编码机制用比未经编码少的数据位元(或者其它信息相关的单位)表示信息的过程。例如,如果我们将“compression”编码为“comp”那么这篇文章可以用较少的数据位表示。一种流行的压缩实例是许多计算机都在使用的ZIP文件格式,它不仅仅提供了压缩的功能,而且还作为归档工具(Archiver)使用,能够将许多文件存储到同一个文件中。数据压缩概要对于任何形式的通信来说,只有当信息的发送方和接受方都能够理解编码机制的时候压缩数据通信才能够工作。例如,只有当接受方知道这篇文章需要用英语字符解释的时候这篇文章才有意义。同样,只有当接受方知道编码方法的时候他才能够理解压缩数据。一些压缩算法利用了这个特性,在压缩过程中对数据进行加密,例如利用密码加密,以保证只有得到授权的一方才能正确地得到数据。数据压缩能够实现是因为多数现实世界的数据都有统计冗余。例如,字母“e”在英语中比字母“z”更加常用,字母“q”后面是“z”的可能性非常小。无损压缩算法通常利用了统计冗余,这样就能更加简练地、但仍然是完整地表示发送方的数据。如果允许一定程度的保真度损失,那么还可以实现进一步的压缩。例如,人们看图画或者电视画面的时候可能并不会注意到一些细节并不完善。同样,两个音频录音采样序列可能听起来一样,但实际上并不完全一样。有损压缩算法在带来微小差别的情况下使用较少的位数表示图像、视频或者音频。原理压缩原理其实很简单,就是找出那些重复出现的字符串,然后用更短的符号代替,从而达到缩短字符串的目的。比如,有一篇文章大量使用中华人民共和国这个词语,我们用中国代替,就缩短了5个字符,如果用华代替,就缩短了6个字符。事实上,只要保证对应关系,可以用任意字符代替那些重复出现的字符串。本质上,所谓压缩就是找出文件内容的概率分布,将那些出现概率高的部分代替成更短的形式。所以,内容越是重复的文件,就可以压缩地越小。比如,ABABABABABABAB可以压缩成7AB。相应地,如果内容毫无重复,就很难压缩。极端情况就是,遇到那些均匀分布的随机字符串,往往连一个字符都压缩不了。比如,任意排列的10个阿拉伯数字(5271839406),就是无法压缩的;再比如,无理数(比如π)也很难压缩。压缩就是一个消除冗余的过程,相当于用一种更精简的形式,表达相同的内容。可以想象,压缩过一次以后,文件中的重复字符串将大幅减少。好的压缩算法,可以将冗余降到最低,以至于再也没有办法进一步压缩。理论与应用压缩的理论基础是信息论(它与算法信息论密切相关)以及率失真理论,这个领域的研究工作主要是由ClaudeShannon奠定的,他在二十世纪四十年代末期及五十年代早期发表了这方面的基础性的论文。Doyle和Carlson在2000年写道数据压缩“有所有的工程领域最简单、最优美的设计理论之一”。密码学与编码理论也是密切相关的学科,数据压缩的思想与统计推断也有很深的渊源。应用:一种非常简单的压缩方法是行程长度编码,这种方法使用数据及数据长度这样简单的编码代替同样的连续数据,这是无损数据压缩的一个实例。这种方法经常用于办公计算机以更好地利用磁盘空间、或者更好地利用计算机网络中的带宽。对于电子表格、文本、可执行文件等这样的符号数据来说,无损是一个非常关键的要求,因为除了一些有限的情况,大多数情况下即使是一个数据位的变化都是无法接受的。对于视频和音频数据,只要不损失数据的重要部分一定程度的质量下降是可以接受的。通过利用人类感知系统的局限,能够大幅度得节约存储空间并且得到的结果质量与原始数据质量相比并没有明显的差别。这些有损数据压缩方法通常需要在压缩速度、压缩数据大小以及质量损失这三者之间进行折衷。有损图像压缩用于数码相机中,大幅度地提高了存储能力,同时图像质量几乎没有降低。用于DVD的有损MPEG-2编解码视频压缩也实现了类似的功能。在有损音频压缩中,心理声学的方法用来去除信号中听不见或者很难听见的成分。人类语音的压缩经常使用更加专业的技术,因此人们有时也将“语音压缩”或者“语音编码”作为一个独立的研究领域与“音频压缩”区分开来。不同的音频和语音压缩标准都属于音频编解码范畴。例如语音压缩用于因特网电话,而音频压缩被用于CD翻录并且使用MP3播放器解码。类型数据压缩可分成两种类型,一种叫做无损压缩,另一种叫做有损压缩。无损压缩是指使用压缩后的数据进行重构(或者叫做还原,解压缩),重构后的数据与原来的数据完全相同;无损压缩用于要求重构的信号与原始信号完全一致的场合。一个很常见的例子是磁盘文件的压缩。根据目前的技术水平,无损压缩算法一般可以把普通文件的数据压缩到原来的1/2~1/4。一些常用的无损压缩算法有霍夫曼(Huffman)算法和LZW(Lenpel-Ziv&Welch)压缩算法。有损压缩是指使用压缩后的数据进行重构,重构后的数据与原来的数据有所不同,但不影响人对原始资料表达的信息造成误解。有损压缩适用于重构信号不一定非要和原始信号完全相同的场合。例如,图像和声音的压缩就可以采用有损压缩,因为其中包含的数据往往多于我们的视觉系统和听觉系统所能接收的信息,丢掉一些数据而不至于对声音或者图像所表达的意思产生误解,但可大大提高压缩比流行算法Lempel-Ziv(LZ)压缩方法是最流行的无损存储算法之一。DEFLATE是LZ的一个变体,它针对解压速度与压缩率进行了优化,虽然它的压缩速度可能非常缓慢,PKZIP、gzip以及PNG都在使用DEFLATE。LZW(Lempel-Ziv-Welch)是Unisys的专利,直到2003年6月专利到期限,这种方法用于GIF图像。另外值得一提的是LZR(LZ-Renau)方法,它是Zip方法的基础。LZ方法使用基于表格的压缩模型,其中表格中的条目用重复的数据串替换。对于大多数的LZ方法来说,这个表格是从最初的输入数据动态生成的。这个表格经常采用霍夫曼编码维护(例如,SHRI、LZX)。目前一个性能良好基于LZ的编码机制是LZX,它用于微软公司的CAB格式。算法编码算术编码由JormaRissanen发明,并且由Witten、Neal以及Cleary将它转变成一个实用的方法。这种方法能够实现比众人皆知的哈夫曼算法更好的压缩,并且它本身非常适合于自适应数据压缩,自适应数据压缩的预测与上下文密切相关。算术编码已经用于二值图像压缩标准JBIG、文档压缩标准DejaVu。文本输入系统Dasher是一个逆算术编码器。算术编码是近十多年来发展迅速的一种无失真信源编码,它与最佳的哈夫曼码相比,理论性能稍加逊色,而实际压缩率和编码效率却往往还优于哈夫曼码,且实现简单,故很受工程上的重视。算术编码不同于哈夫曼码,它是非分组(非块)码。它从全序列出发,考虑符号之间的关系来进行编码。算术编码利用了累积概率的概念。算术码主要的编码方法是计算输入信源符号序列所对应的区间。
 三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 扫描二维码
扫描二维码




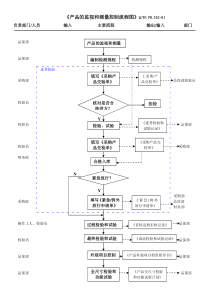



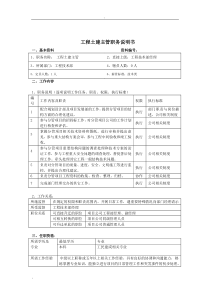

 heiyijushi
heiyijushi
本文标题:信息论与编码之数据压缩
链接地址:https://www.777doc.com/doc-5183741 .html