您好,欢迎访问三七文档
当前位置:首页 > 商业/管理/HR > 质量控制/管理 > 聚类方法(Clustering)
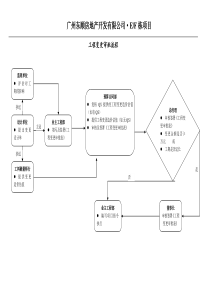
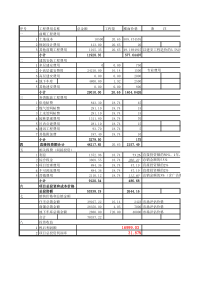
聚类方法(Clustering)统研会学术交流篇之——演讲人:上海财经大学统计学系吕江平主讲内容聚类方法原理介绍案例分析(SAS/EnterpriseMiner)推荐参考书目什么是聚类聚类(Clustering)就是将数据分组成为多个类(Cluster)。在同一个类内对象之间具有较高的相似度,不同类之间的对象差别较大。什么是聚类早在孩提时代,人就通过不断改进下意识中的聚类模式来学会如何区分猫和狗,动物和植物聚类分析无处不在谁经常光顾商店,谁买什么东西,买多少?按忠诚卡记录的光临次数、光临时间、性别、年龄、职业、购物种类、金额等变量分类这样商店可以….识别顾客购买模式(如喜欢一大早来买酸奶和鲜肉,习惯周末时一次性大采购)刻画不同的客户群的特征(用变量来刻画,就象刻画猫和狗的特征一样)什么情况下需要聚类为什么这样分类?因为每一个类别里面的人消费方式都不一样,需要针对不同的人群,制定不同的关系管理方式,以提高客户对公司商业活动的相应率。聚类分析无处不在挖掘有价值的客户,并制定相应的促销策略:如,对经常购买酸奶的客户对累计消费达到12个月的老客户针对潜在客户派发广告,比在大街上乱发传单命中率更高,成本更低!聚类分析无处不在谁是银行信用卡的黄金客户?利用储蓄额、刷卡消费金额、诚信度等变量对客户分类,找出“黄金客户”!这样银行可以……制定更吸引的服务,留住客户!比如:一定额度和期限的免息透资服务!百盛的贵宾打折卡!在他或她生日的时候送上一个小蛋糕!聚类的应用领域经济领域:帮助市场分析人员从客户数据库中发现不同的客户群,并且用购买模式来刻画不同的客户群的特征。谁喜欢打国际长途,在什么时间,打到那里?对住宅区进行聚类,确定自动提款机ATM的安放位置股票市场板块分析,找出最具活力的板块龙头股企业信用等级分类……生物学领域推导植物和动物的分类;对基因分类,获得对种群的认识数据挖掘领域作为其他数学算法的预处理步骤,获得数据分布状况,集中对特定的类做进一步的研究有贡献的研究领域数据挖掘聚类可伸缩性、各种各种复杂形状类的识别,高维聚类等统计学主要集中在基于距离的聚类分析,发现球状类机器学习无指导学习(聚类不依赖预先定义的类,不等同于分类)空间数据技术生物学市场营销学什么情况下需要聚类以上分析,没有大量的数据去支持,DataMining就什么都挖不出来。大量的数据不等于大量的垃圾,我们需要针对客户市场细分所需要的资料。如需要知道白金持卡人和金卡持卡人的流动率,各自平均消费水平有多少,等;聚类分析可以辅助企业进行客户细分,但是Datamining的客户细分不等同于商业领域的细分,看不懂结果,也可能造成企业管理层无法对结果善加利用。聚类分析原理介绍聚类分析中“类”的特征:聚类所说的类不是事先给定的,而是根据数据的相似性和距离来划分聚类的数目和结构都没有事先假定聚类分析原理介绍聚类方法的目的是寻找数据中:潜在的自然分组结构astructureof“natural”grouping感兴趣的关系relationship聚类分析原理介绍什么是自然分组结构Naturalgrouping?我们看看以下的例子:有16张牌如何将他们分为一组一组的牌呢?AKQJ聚类分析原理介绍分成四组每组里花色相同组与组之间花色相异AKQJ花色相同的牌为一副Individualsuits聚类分析原理介绍分成四组符号相同的牌为一组AKQJ符号相同的的牌Likefacecards聚类分析原理介绍分成两组颜色相同的牌为一组AKQJ颜色相同的配对Blackandredsuits聚类分析原理介绍分成两组大小程度相近的牌分到一组AKQJ大配对和小配对Majorandminorsuits聚类分析原理介绍这个例子告诉我们,分组的意义在于我们怎么定义并度量“相似性”Similar因此衍生出一系列度量相似性的算法AKQJ大配对和小配对Majorandminorsuits聚类分析原理介绍相似性Similar的度量(统计学角度)距离Q型聚类(主要讨论)主要用于对样本分类常用的距离有(只适用于具有间隔尺度变量的聚类):明考夫斯基距离(包括:绝对距离、欧式距离、切比雪夫距离)兰氏距离马氏距离斜交空间距离此不详述,有兴趣可参考《应用多元分析》(第二版)王学民相似系数R型聚类用于对变量分类,可以用变量之间的相似系数的变形如1-rij定义距离这里不详细介绍这种聚类度量方法聚类分析原理介绍变量按测量尺度(MeasurementLevel)分类间隔(Interval)尺度变量连续变量,如长度、重量、速度、温度等有序(Ordinal)尺度变量等级变量,不可加,但可比,如一等、二等、三等奖学金名义(Nominal)尺度变量类别变量,不可加也不可比,如性别、职业等当对象是同时被各种类型的变量描述时,怎样描述对象之间的相异度呢?一种可取的办法是把所有变量一起处理,将不同类型的变量组合在单个相异矩阵中,把所有有意义的变量转换到【0,1】的区间上,只进行一次聚类分析。详见参考书主要聚类算法的分类层次的方法(也称系统聚类法)(hierarchicalmethod)划分方法(partitioningmethod)基于密度的方法(density-basedmethod)基于网格的方法(grid-basedmethod)基于模型的方法(model-basedmethod)……其中,前两种算法是利用统计学定义的距离进行度量层次的方法(也称系统聚类法)(hierarchicalmethod)定义:对给定的数据进行层次的分解:分类:凝聚的(agglomerative)方法(自底向上)(案例介绍)思想:一开始将每个对象作为单独的一组,然后根据同类相近,异类相异的原则,合并对象,直到所有的组合并成一个,或达到一个终止条件为止。分裂的方法(divisive)(自顶向下)思想:一开始将所有的对象置于一类,在迭代的每一步中,一个类不断地分为更小的类,直到每个对象在单独的一个类中,或达到一个终止条件。层次的方法(也称系统聚类法)(hierarchicalmethod)特点:类的个数不需事先定好需确定距离矩阵运算量要大,适用于处理小样本数据广泛采用的类间距离:最小距离法(singlelinkagemethod)极小异常值在实际中不多出现,避免极大值的影响广泛采用的类间距离:最大距离法(completelinkagemethod)可能被极大值扭曲,删除这些值之后再聚类广泛采用的类间距离:类平均距离法(averagelinkagemethod)类间所有样本点的平均距离该法利用了所有样本的信息,被认为是较好的系统聚类法广泛采用的类间距离:重心法(centroidhierarchicalmethod)类的重心之间的距离对异常值不敏感,结果更稳定广泛采用的类间距离离差平方和法(wardmethod)D2=WM-WK-WL即对异常值很敏感;对较大的类倾向产生较大的距离,从而不易合并,较符合实际需要。LKLKMkLKLXXXXnnnD2ClusterKClusterLClusterM层次的方法缺陷:一旦一个步骤(合并或分裂)完成,就不能被撤销或修正,因此产生了改进的层次聚类方法,如BRICH,BURE,ROCK,Chameleon。详见参考书划分方法(Partitioningmethod)较流行的方法有:动态聚类法(也称逐步聚类法),如k-均值算法、k-中心点算法思想:随机选择k个对象,每个对象初始地代表一个类的平均值或中心,对剩余每个对象,根据其到类中心的距离,被划分到最近的类;然后重新计算每个类的平均值。不断重复这个过程,直到所有的样本都不能再分配为止。(图解)划分方法(Partitioningmethod)特点:k事先定好创建一个初始划分,再采用迭代的重定位技术不必确定距离矩阵比系统聚类法运算量要小,适用于处理庞大的样本数据适用于发现球状类划分方法(Partitioningmethod)缺陷:不同的初始值,结果可能不同有些k均值算法的结果与数据输入顺序有关,如在线k均值算法用爬山式技术(hill-climbing)来寻找最优解,容易陷入局部极小值基于距离的方法进行聚类只能发现球状类,当类的形状是任意的时候怎么识别?(黑板图示)下面介绍其中一种常用的算法:基于密度的方法(density-basedmethod)主要有DBSCAN,OPTICS法思想:只要临近区域的密度超过一定的阀值,就继续聚类特点:可以过滤噪声和孤立点outlier,发现任意形状的类基于网格的方法(grid-basedmethod)把样本空间量化为有限数目的单元,形成一个网络结构,聚类操作都在这个网格结构(即量化空间)上进行基于模型的方法(model-basedmethod)为每个类假定一个模型,寻找数据对给定模型的最佳拟合。此不详述,有兴趣可以参考《DataMingConceptsandTechniques》即《数据挖掘概念于技术》JiaweiHanMichelineKamber机械工业出版社不稳定的聚类方法受所选择变量的影响如果去掉或者增加一些变量,结果会很不同.因此,聚类之前一定要明确目标,选择有意义的变量。变量之间的相关性也会影响聚类结果,因此可以先用主成分或因子分析法把众多变量压缩为若干个相互独立的并包含大部分信息的指标,然后再进行聚类。不稳定的聚类方法输入参数凭主观导致难以控制聚类的质量很多聚类算法要求输入一定的参数,如希望产生的类的数目,使得聚类的质量难以控制,尤其是对于高维的,没有先验信息的庞大数据。首先要明确聚类的目的,就是要使各个类之间的距离尽可能远,类中的距离尽可能近,聚类算法可以根据研究目的确定类的数目,但分类的结果要有令人信服的解释。在实际操作中,更多的是凭经验来确定类的数目,测试不同类数的聚类效果,直到选择较理想的分类。不稳定的聚类方法算法的选择没有绝对当聚类结果被用作描述或探查工具时,可以对同样的数据尝试多种算法,以发现数据可能揭示的结果。不稳定的聚类方法聚类分析中权重的确定当各指标重要性不同的时候,需要根据需要调整权重。如加权欧式距离,权重可以用专家法确定。案例演示有一个电信公司的数据,变量为:ID:用户电话号码Mobile:移动电话通话时间Fixed:固定电话通话时间DDD:长途直拨通话时间IP:IP电话通话时间研究目的:挖掘不同人群拨打电话的特征下面用SAS/EnterpriseMiner演示Q&A推荐参考书目《应用多元分析》(第二版)王学民上海财经大学出版社《应用多元统计分析》即《AppiedMultivariateSatistics》5thEdRichardA.Johnson,DeanW.Wichern中国统计出版社《数据仓库》即《BuildingtheDataWarehouse》3thEd,W.H.Inman机械工业出版社《数据挖掘原理》《PrinciplesofDataMining》DavidHandHeikkiMannilaPadhraicSmgth机械工业出版社《DataMiningIntroductionandAdvancedTopics》MargaretH.Dunham《数据挖掘概念于技术》即《DataMingConceptsandTechniques》JiaweiHanMichelineKamber机械工业出版社《数据挖掘——客户关系管理的科学与艺术》即《MasteringDataMiningTheArtandScienceofCustermerRelationshipManagement》MichaelJ.A.Berry,GordonS.Linoff中国财政经济出版社《统计学教学案例》王吉利,何书
 三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 扫描二维码
扫描二维码








 42425799
42425799
本文标题:聚类方法(Clustering)
链接地址:https://www.777doc.com/doc-5691459 .html