您好,欢迎访问三七文档
当前位置:首页 > 商业/管理/HR > 质量控制/管理 > 编译原理词法分析实验报告
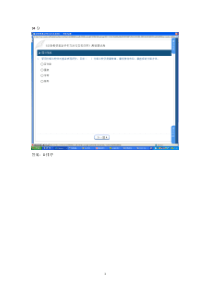
词法分析器实验报告一、实验目的选择一种编程语言实现简单的词法分析程序,设计、编制并调试一个词法分析程序,加深对词法分析原理的理解。二、实验要求待分析的简单的词法(1)关键字:beginifthenwhiledoend所有的关键字都是小写。(2)运算符和界符:=+-*/===;()#(3)其他单词是标识符(ID)和整型常数(SUM),通过以下正规式定义:ID=letter(letter|digit)*NUM=digitdigit*(4)空格有空白、制表符和换行符组成。空格一般用来分隔ID、SUM、运算符、界符和关键字,词法分析阶段通常被忽略。各种单词符号对应的种别码:表各种单词符号对应的种别码单词符号种别码单词符号种别码begin1:17If2:=18Then320while421do5=22end623lettet(letter|digit)*10=24dightdight*11=25+13;26—14(27*15)28/16#0词法分析程序的功能:输入:所给文法的源程序字符串。输出:二元组(syn,token或sum)构成的序列。其中:syn为单词种别码;token为存放的单词自身字符串;sum为整型常数。例如:对源程序beginx:=9:ifx9thenx:=2*x+1/3;end#的源文件,经过词法分析后输出如下序列:(1,begin)(10,x)(18,:=)(11,9)(26,;)(2,if)……三、词法分析程序的算法思想:算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。主程序示意图:主程序示意图如图3-1所示。其中初始包括以下两个方面:⑴关键字表的初值。关键字作为特殊标识符处理,把它们预先安排在一张表格中(称为关键字表),当扫描程序识别出标识符时,查关键字表。如能查到匹配的单词,则该单词为关键字,否则为一般标识符。关键字表为一个字符串数组,其描述如下:Char*rwtab[6]={“begin”,“if”,“then”,“while”,“do”,“end”,};否是图3-1(2)程序中需要用到的主要变量为syn,token和sum扫描子程序的算法思想:首先设置3个变量:①token用来存放构成单词符号的字符串;②sum用来整型单词;③syn用来存放单词符号的种别码。扫描子程序主要部分流程如图3-2所示。是是置初值调用扫描子程序输出单词二元组输入串结束结束变量初始化忽略空格是否文件结束?返回否字母数字其他运算符、符号界符等符号否是图3-2四、词法分析程序的源代码:#include#include#include#includecharprog[80],token[8],ch;intsyn,p,m,n,sum;char*rwtab[6]={begin,if,then,while,do,end};scaner();main(){p=0;printf(\npleaseinputastring(endwith'#'):/n);do{scanf(%c,&ch);prog[p++]=ch;}while(ch!='#');p=0;do{scaner();switch(syn){case11:printf((%-10d%5d)\n,sum,syn);break;case-1:printf(youhaveinputawrongstring\n);getch();exit(0);default:printf((%-10s%5d)\n,token,syn);break;}}while(syn!=0);getch();}scaner(){sum=0;for(m=0;m8;m++)token[m++]=NULL;ch=prog[p++];m=0;while((ch=='')||(ch=='\n'))ch=prog[p++];if(((ch='z')&&(ch='a'))||((ch='Z')&&(ch='A')))拼数syn=1111返回对不同符号给出相应的syn值报错拼字符串是否关键字?syn为对应关键字的单词种别码syn=10{while(((ch='z')&&(ch='a'))||((ch='Z')&&(ch='A'))||((ch='0')&&(ch='9'))){token[m++]=ch;ch=prog[p++];}p--;syn=10;for(n=0;n6;n++)if(strcmp(token,rwtab[n])==0){syn=n+1;break;}}elseif((ch='0')&&(ch='9')){while((ch='0')&&(ch='9')){sum=sum*10+ch-'0';ch=prog[p++];}p--;syn=11;}elseswitch(ch){case'':token[m++]=ch;ch=prog[p++];if(ch=='='){syn=22;token[m++]=ch;}else{syn=20;p--;}break;case'':token[m++]=ch;ch=prog[p++];if(ch=='='){syn=24;token[m++]=ch;}else{syn=23;p--;}break;case'+':token[m++]=ch;ch=prog[p++];if(ch=='+'){syn=17;token[m++]=ch;}else{syn=13;p--;}break;case'-':token[m++]=ch;ch=prog[p++];if(ch=='-'){syn=29;token[m++]=ch;}else{syn=14;p--;}break;case'!':ch=prog[p++];if(ch=='='){syn=21;token[m++]=ch;}else{syn=31;p--;}break;case'=':token[m++]=ch;ch=prog[p++];if(ch=='='){syn=25;token[m++]=ch;}else{syn=18;p--;}break;case'*':syn=15;token[m++]=ch;break;case'/':syn=16;token[m++]=ch;break;case'(':syn=27;token[m++]=ch;break;case')':syn=28;token[m++]=ch;break;case'{':syn=5;token[m++]=ch;break;case'}':syn=6;token[m++]=ch;break;case';':syn=26;token[m++]=ch;break;case'\':syn=30;token[m++]=ch;break;case'#':syn=0;token[m++]=ch;break;case':':syn=17;token[m++]=ch;break;default:syn=-1;break;}token[m++]='\0';}五、结果分析:输入beginy:=8:ifx=8thenx:=2*(1+1/3);end#经词法分析输出如下序列:如图所示:六、总结:虽然编译这门课很难,很多时候听都听不懂,但是做词法分析器还是比较有趣的。尽管这个程序不是100%由我所编写的,仍然花了我一些心思,这个程序是由我和同学共同编写、调试的,期间也有不少的磨合。也许,编译课上我并没有学到太多关于本学科的知识,但我从教员那里了解了、收获了很多书本上没有的东西,丰富了我的阅历,拓宽了视野,也学会了很多做人的道理。
 三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 扫描二维码
扫描二维码






![土建预算工程量计算实例[1]2](/doc-1208878.png)


 anjeff
anjeff
本文标题:编译原理词法分析实验报告
链接地址:https://www.777doc.com/doc-6050149 .html