您好,欢迎访问三七文档
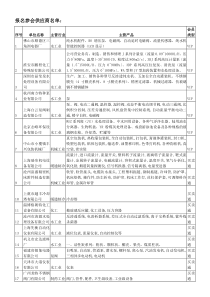
1决策树(DecisionTree)2019/8/2921、分类的意义数据库了解类别属性与特征预测分类模型—决策树分类模型—聚类一、分类(Classification)2019/8/293数据库分类标记性别年龄婚姻否是否是FemaleMale35≧35未婚已婚2019/8/292、分类的技术(1)决策树4(2)聚类2019/8/293、分类的程序5模型建立(ModelBuilding)模型评估(ModelEvaluation)使用模型(UseModel)2019/8/29决策树分类的步骤6数据库2019/8/29训练样本(trainingsamples)建立模型测试样本(testingsamples)评估模型例:7资料训练样本婚姻年龄家庭所得否是否是未婚已婚35≧35低高否小康1.建立模型测试样本2.模型评估错误率为66.67%修改模型3.使用模型2019/8/294、分类算法的评估8预测的准确度:指模型正确地预测新的或先前未见过的数据的类标号的能力。训练测试法(training-and-testing)交叉验证法(cross-validation)例如,十折交叉验证。即是将数据集分成十分,轮流将其中9份做训练1份做测试,10次的结果的均值作为对算法精度的估计,一般还需要进行多次10倍交叉验证求均值,例如10次10倍交叉验证,更精确一点。2019/8/292019/8/299速度:指产生和使用模型的计算花费。建模的速度、预测的速度强壮性:指给定噪声数据或具有缺失值的数据,模型正确预测的能力。可诠释性:指模型的解释能力。102019/8/29决策树归纳的基本算法是贪心算法,它以自顶向下递归各个击破的方式构造决策树。贪心算法:在每一步选择中都采取在当前状态下最好/优的选择。在其生成过程中,分割方法即属性选择度量是关键。通过属性选择度量,选择出最好的将样本分类的属性。根据分割方法的不同,决策树可以分为两类:基于信息论的方法(较有代表性的是ID3、C4.5算法等)和最小GINI指标方法(常用的有CART、SLIQ及SPRINT算法等)。二、决策树(DecisionTree)(一)决策树的结构11根部节点(rootnode)中间节点(non-leafnode)(代表测试的条件)分支(branches)(代表测试的结果)叶节点(leafnode)(代表分类后所获得的分类标记)2019/8/292019/8/2912(二)决策树的形成例:13根部节点中间节点停止分支?2019/8/29(三)ID3算法(C4.5,C5.0)142019/8/29Quinlan(1979)提出,以Shannon(1949)的信息论为依据。ID3算法的属性选择度量就是使用信息增益,选择最高信息增益的属性作为当前节点的测试属性。信息论:若一事件有k种结果,对应的概率为Pi。则此事件发生后所得到的信息量I(视为Entropy)为:I=-(p1*log2(p1)+p2*log2(p2)+…+pk*log2(pk))Example1:设k=4p1=0.25,p2=0.25,p3=0.25,p4=0.25I=-(.25*log2(.25)*4)=2Example2:设k=4p1=0,p2=0.5,p3=0,p4=0.5I=-(.5*log2(.5)*2)=1Example3:设k=4p1=1,p2=0,p3=0,p4=0I=-(1*log2(1))=02019/8/29152019/8/2916信息增益17Example(Gain)n=16n1=4I(16,4)=-((4/16)*log2(4/16)+(12/16)*log2(12/16))=0.8113E(年龄)=(6/16)*I(6,1)+(10/16)*I(10,3)=0.7946Gain(年龄)=I(16,4)-E(年龄)=0.0167Gain(年龄)=0.0167Max:作为第一个分类依据2019/8/29Gain(性别)=0.0972Gain(家庭所得)=0.0177Example(续)18Gain(家庭所得)=0.688I(7,3)=-((3/7)*log2(3/7)+(4/7)*log2(4/7))=0.9852Gain(年龄)=0.9852Gain(年龄)=0.2222I(9,1)=-((1/9)*log2(1/9)+(8/9)*log2(8/9))=0.5032Gain(家庭所得)=0.50322019/8/29Example(end)ID3算法19分类规则:IF性别=FemaleAND家庭所得=低所得THEN购买RV房车=否IF性别=FemaleAND家庭所得=小康THEN购买RV房车=否IF性别=FemaleAND家庭所得=高所得THEN购买RV房车=是IF性别=MaleAND年龄35THEN购买RV房车=否IF性别=MaleAND年龄≧35THEN购买RV房车=是资料DecisionTree2019/8/29(四)DecisionTree的建立过程201、决策树的停止决策树是通过递归分割(recursivepartitioning)建立而成,递归分割是一种把数据分割成不同小的部分的迭代过程。如果有以下情况发生,决策树将停止分割:该群数据的每一笔数据都已经归类到同一类别。该群数据已经没有办法再找到新的属性来进行节点分割。该群数据已经没有任何尚未处理的数据。2019/8/292、决策树的剪枝(pruning)21决策树学习可能遭遇模型过度拟合(overfitting)的问题,过度拟合是指模型过度训练,导致模型记住的不是训练集的一般性,反而是训练集的局部特性。如何处理过度拟合呢?对决策树进行修剪。树的修剪有几种解决的方法,主要为先剪枝和后剪枝方法。2019/8/29(1)先剪枝方法22在先剪枝方法中,通过提前停止树的构造(例如,通过决定在给定的节点上不再分裂或划分训练样本的子集)而对树“剪枝”。一旦停止,节点成为树叶。确定阀值法:在构造树时,可将信息增益用于评估岔的优良性。如果在一个节点划分样本将导致低于预定义阀值的分裂,则给定子集的进一步划分将停止。测试组修剪法:在使用训练组样本产生新的分岔时,就立刻使用测试组样本去测试这个分岔规则是否能够再现,如果不能,就被视作过度拟合而被修剪掉,如果能够再现,则该分岔予以保留而继续向下分岔。2019/8/29(2)后剪枝方法23后剪枝方法是由“完全生长”的树剪去分枝。通过删除节点的分枝,剪掉叶节点。案例数修剪是在产生完全生长的树后,根据最小案例数阀值,将案例数小于阀值的树节点剪掉。成本复杂性修剪法是当决策树成长完成后,演算法计算所有叶节点的总和错误率,然后计算去除某一叶节点后的总和错误率,当去除该叶节点的错误率降低或者不变时,则剪掉该节点。反之,保留。2019/8/29应用案例:在农业中的应用2019/8/2924第一步:属性离散化2019/8/2925第二步:概化(泛化)2019/8/2926第三步:计算各属性的期望信息2019/8/2927=(17/30)*LOG((17/30),2)+(10/30)*LOG((10/30),2)+(3/30)*LOG((3/30),2)计算各属性的信息增益2019/8/2928第四步:决策树2019/8/2929案例2:银行违约率2019/8/29302019/8/2931案例3对电信客户的流失率分析2019/8/2932数据仓库条件属性类别属性客户是否流失案例4:在银行中的应用2019/8/2933案例5:个人信用评级2019/8/2934个人信用评级决策树(五)其他算法35C4.5与C5.0算法GiniIndex算法CART算法PRISM算法CHAID算法2019/8/291、C4.5与C5.0算法36C5.0算法则是C4.5算法的修订版,适用在处理大数据集,采用Boosting(提升)方式提高模型准确率,又称为BoostingTrees,在软件上的计算速度比较快,占用的内存资源较少。2019/8/29类别属性的信息熵2、GiniIndex算法37ID3andPRISM适用于类别属性的分类方法。GiniIndex能数值型属性的变量来做分类。着重解决当训练集数据量巨大,无法全部放人内存时,如何高速准确地生成更快的,更小的决策树。2019/8/29集合T包含N个类别的记录,那么其Gini指标就是如果集合T分成两部分N1和N2。则此分割的Gini就是提供最小Ginisplit就被选择作为分割的标准(对于每个属性都要经过所有可以的分割方法)。GiniIndex算法382()11jNginiTpjpjj为类別出现的频率)()()(2211TginiNNTginiNNTginisplit2019/8/29案例:在汽车销售中的应用2019/8/29392019/8/29402019/8/2941NNYYYNYYYNNN3、CART算法42由Friedman等人提出,1980年以来就开始发展,是基于树结构产生分类和回归模型的过程,是一种产生二元树的技术。CART与C4.5/C5.0算法的最大的区别是:其在每一个节点上都是采用二分法,也就是一次只能够有两个子节点,C4.5/5.0则在每一个节点上可以产生不同数量的分枝。2019/8/292019/8/2943构建树的步骤:2019/8/29442019/8/2945
 三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 扫描二维码
扫描二维码








 xuan0630
xuan0630
本文标题:3第三章决策树
链接地址:https://www.777doc.com/doc-609221 .html