您好,欢迎访问三七文档
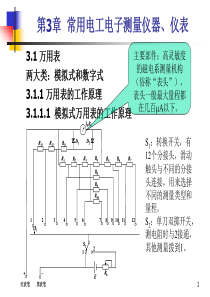
python爬虫工作梳理遇到的困难爬虫的方法下一步打算工作现状python爬虫爬虫方法1.直接使用python内置的库,用BeautifulSoup解析使用selenium构造浏览器访问并使用BeautifulSoup解析Python爬虫方法可以使用的方法2.使用selenium构造浏览器访问3.使用爬虫框架——scrapy最后使用的方法遇到的困难尝试添加cookies失败,只能寻找别的办法1.添加cookies访问2.访问次数过多被禁止由于需要登录,所以必须添加cookies访问当在一定时间内的请求次数过多,账号被封,第二天解封网站登录验证码网站登录需要识别验证码,所以选择selenium+chrom的方式访问网站不需要添加cookies,但是效果降低工作现状爬虫速度比较慢爬虫比较稳定扒了一千多道选择题因为是使用selenium,所以速度会比使用内置库函数访问较慢,但太快反而会被冻结账号间隔时间长,给selenium充分的时间访问,不容易因为网络问题出现异常接下来还会继续扒后续打算Python后续打算继续扒题加快速度学习scrapy框架尝试添加cookies访问方式PPT模板:素材:背景:图表:下载:教程:资料下载:范文下载:试卷下载:教案下载:论坛:课件:语文课件:数学课件:英语课件:美术课件:科学课件:物理课件:化学课件:生物课件:地理课件:历史课件:谢谢!
 三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 扫描二维码
扫描二维码







 xuli124
xuli124
本文标题:爬虫工作梳理
链接地址:https://www.777doc.com/doc-6133580 .html