您好,欢迎访问三七文档
当前位置:首页 > 商业/管理/HR > 经营企划 > 连锁店和生产基地增设以及货物配送问题数学建模
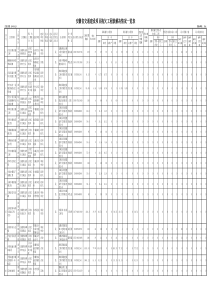
第一题:1、问题重述华商公司在全省县级及以上城镇设立销售连锁店,主要销售鲜猪肉。已知全省县级及以上城镇地理位置及道路连接。目前公司现有2个生产基地(分别设在120号和63号城镇)、23家销售连锁店,连锁店的日销售量见附录1。若运输成本为0.45元/吨公里,请你为公司设计生产与配送方案,使运输成本最低。2、问题分析本题首先使用matlab软件将全省交通网络数据转换成矩阵,即若两点之间有路线,则采用矩阵的形式标注出来,若没有直接路线,则用相对很大的数如M表示,这对其求最短路没有影响。然后采用Floyd算法算出任意两个城镇之间的距离,得出新的最短路矩阵,然后从中挑选出每个连锁店与生产基地所在地城镇63和城镇120之间距离的最小值。由于每个连锁店的日销量都是给定的,并且生产基地必须满足所有连锁店的需求,因此,本题所求的运输成本最低可以转化为生产基地到连锁店的总路线最短。3、模型假设(1)位于同一个城镇里的生产基地和连锁店之间的距离视为0,不计入运输成本。(2)由于要求运输成本最小,所以假定除了距离外,没有其他因素影响运输成本(3)在求出的最短路中,皆是可行的路线。4、符号说明:从到的只以集合中的节点为中间节点的最短路径的长度5、模型建立由于要求的问题可转化为最短路问题,而解决任意两点之间的最短路问题,一般而言最为经典的模型便是Floyd算法,所以此模型即为Floyd算法的模型。即状态转移方程如下:1.若最短路径经过点k,则;2.若最短路径不经过点k,则。因此,。在实际算法中,为了节约空间,可以直接在原来空间上进行迭代,这样空间可降至二维。6、模型求解全省交通网络图如下:先把全省交通网络数据转换成矩阵,其matlab程序见附件程序一(注:如问题分析所说,若两点之间没有直接路线,则用大M表示,分析此题,可用1000代替大M,对程序运行结果无影响),然后采用Floyd算法,求出一个154*154的矩阵,D(i,j)表示i,j之间的最短距离。Floyd算法程序见附件程序二。我们算出任意两个城镇之间的距离,然后分别比较城镇63和城镇120与23个连锁店的距离,比如:如果城镇63与连锁店i的距离小于城镇120与连锁店i的距离,则连锁店i的猪肉由生产基地在城镇63的生产基地供应。最终所得方案如下:表1运输成本最小方案生产基地连锁店所在城镇最短距离(公里)日销售量(kg)运费(元)城镇63210663.7382231095.662295514161.729258257.13169291134.3114744891.1199881136151.1911503782.61235651334119.5445124.2606431442110.589489472.1821291594170.1712773978.11163451914572.85396531299.9244732116103.6414783689.449554221235.111808141.5772595城镇120431114.66239471235.593359610108.368481413.55052276519.0915570133.75408587928.1738759491.32846351227135.19265563.2656751611179.156103492.00860251724128.943251188.6327732022168.956375484.675312523647.3118406.05268最终可得总费用最小为:10540.8935元注:由于连锁店3和18都在63号城镇、连锁店1和10都在120号城镇,可以将这四个连锁店的运输成本忽略不计。7、模型评价(1)优点:容易理解,可以算出任意两个节点之间的最短距离,代码编写简单(2)缺点:时间复杂度比较高,不适合计算大量数据。第二题1、问题重述根据近5年全省各城镇的鲜猪肉月度需求数据,分析各城镇需求特征,并预测未来何时全省鲜猪肉需求达到峰值,并筛选出达到峰值时需求达到前5位和后5位的城镇。2、问题分析本题有三个小问题,我们着重考虑第二个小问,即预测何时全省鲜猪肉需求达到峰值。关于第一小问,由于数量过于庞大,用描述统计的方法即可得到各个城镇数据的大致特征。对于第二小问,应反复使用不同的曲线模型进行拟合,然后选出最合适的模型,求出达到峰值的时间。关于第三小问,为避免计算量过大,我们挑选出第一小问中平均值前十位和后十位的城镇逐个预测,最终能筛选出达到峰值时需求达到前5位和后5位的城镇。3、模型的建立与求解3.1对于第一小问我们利用描述统计的方法,计算出每个城镇数据的全距、均值以及方差。详细数据见附录。(1)城镇68、63、76、86、31的数据全局均在500以上,说明这些城镇数据变化范围较广。(2)城镇31、63的数据均值都在4000以上,说明这两个城市对猪肉的需求量很大,然而也有例如城镇74、94、30、84对猪肉的月平均需求量在120以下。(3)城镇4、92、98、19、43、3、48、93、60、82、96、99、88、89、5、29、16、34、17、84、30、74数据的标准差均在10以下,说明这些城镇数据的波动较小、很平缓。然而也有城镇数据波动性较大,如城镇68、63、76、86、31、1、83、41、40、79、69的标准差都在100以上。3.2对于第二小问:(1)模型假设:题目所给数据季节波动性很弱,可以忽略它的影响。相邻时间段的数据之间基本不存在自回归现象;(2)符号说明:y表示全省鲜猪肉月度需求量x表示时间,例如x=1表示2008年1月。(3)模型的建立和求解我们用SPSS对数据进行曲线拟合,发现拟合度最高的为二次曲线,如下:y=106296.987+373.206x-2.573x^2对方程两边求导,令y’=373.206—2*2.573x=0得x=72.52351即2014年1月中旬全省鲜猪肉需求量达到峰值。3.3对于第三小问:我们根据第一问的结果挑选出月度猪肉需求量均值前10位和后10位的城镇。如下表:表2月度猪肉需求量均值前10位城镇城镇47118210274月需求量均值(公斤)122.8122.4275120.9895112.2618109.4933城镇308410912994月需求量均值(公斤)107.5695104.9897101.615299.2745107.8893表3月度猪肉需求量均值后10位城镇城镇1203163106104月需求量均值(公斤)8634.494484.374136.113438.242141.91城镇1211007956101月需求量均值(公斤)1991.061826.461761.841684.562097.49经过对以上20个城镇的数据逐个拟合,发现城镇31、120、106、121、100、79、56、118、74、30、84的数据没有明显上升或下降的趋势,预测值与平均值不会相差太远,所以在此取其均值作为达到峰值时的预测值。然而城镇101、104、2、47、94、129二次曲线的拟合度都很高,城镇63、109线性拟合度很高。模型如下:城镇101:y(101)=1364.246+40.076x-0.398x^2城镇104:y(104)=1270.008+53.841x-0.626x^2城镇2:y(2)=75.318+1.985x-0.012x^2城镇47:y(47)=74.578+1.86x-0.007x^2城镇94:y(94)=37.881+3.127x-0.021x^2城镇129:y(129)=70.645+1.273x-0.008x^2城镇63:y(63)=4555.160-13.739x城镇109:y(109)=74.016+0.905x将x=72.52351带入以上方程,得出结果如下:y(101)=2177.353705,y(104)=1882.199453,y(2)=156.1612533,y(47)=172.6541121,y(94)=154.2091662,y(129)=120.8901522,y(63)=3558.759496,y(109)=139.6497766从而筛选出全省鲜猪肉需求达到峰值时需求达到前5位和后5位的城镇,如下表:城镇需求量(公斤)表4前五位城镇表5后五位城镇城镇需求量(公斤)1208634.4912314484.374633558.7594961063438.2411012177.353705即全省鲜猪肉需求达到峰值时需求达到前5位的城镇是120、31、63、106、101,后5位的城镇是84、30、74、102、129。问题三1、问题重述已知城镇对公司产品每日需求预测数据,公司未来各城镇每日需求预测数据.但公司产品的需求量与销售量不完全一致,若在当地(同一城镇)购买,则这一部分需求量与销售量相同,若在不足10公里的其他城镇的销售连锁店购买,则这一部分需求量只能实现一半,而在超过10公里的其他城镇的销售连锁店购买,销售量只能达到需求量的三成。公司决定在各城镇增设销售连锁店,且原有的23家销售连锁店销售能力可在现有销售量的基础上上浮20%,增设的销售连锁店销售能力控制在每日20吨至40吨内,并且要求增设的销售连锁店的销售量必须达到销售能力的下限。同一城镇可设立多个销售连锁店。要求规划增设销售连锁店方案,使全省销售量达到最大。2、问题分析由题意知,本题需决定连锁店的增建方案,以使全省销售量最大。那么就需要解决增建多少连锁店,建在哪里的问题。这是一个优化问题,如果用lingo做规划可以解决,但是题中的数据比较大,难以导入,关联性极大,程序也很繁杂。所以,我们将采用先分析,再筛选的方法来解此题。由题意知,在超过10公里以外的城镇购买销售量是原来的三成,反过来说,如果我们从已有的21个已经有连锁店的城镇入手,在距他们10公里以外的城镇(这些城镇的猪肉都由84104.989730107.569574109.4933102112.2618129120.8901522离他们最近的连锁店提供)建立新的连锁店,那么建了新连锁店的城镇的销售量将增加七成,相比在10公里内建新连锁店效果更好。此外,为了达到销售量最大和单个连锁店销售能力下限,在超过10公里的基础上筛选出日销售量比较大的城镇和已有连锁店的城镇作为新建连锁店的试点,再通过由筛选模型建立起来的程序,用matlab进行筛选,最终得到连锁店的个数和选址。由于在选择试点的个数时会有所不同也会有个人倾向,所以,我们得到的只是与最大值比较相近的结果。3、模型假设(1)假设购买者只去距离他们最近的连锁店购买猪肉,不去其他连锁店购买。即各连锁店对其他连锁店所在城镇的销售量无影响。(2)假设买不到猪肉的购买者去个体户或者其他公司购买。即在计算最大销售量时,若销售能力小于需求量时,按最大销售能力计算,反之,最大销售量按需求量计算。4、模型的建立与解答为了规划新增连锁店的个数和地址,以达到全省最大销售量。我们假设各城镇都去离他们最近的连锁店购买猪肉,以此为标准,我们将所有的城镇分成21(有两个城镇原来有2家连锁店)片,每一片中的城镇的猪肉都由这一片中的连锁店提供。然后,将题中所给的每个城镇的猪肉需求量进行排序,并从中挑出除去已存在连锁店的城镇后需求量排在前20位的城镇,然后再按片区从中挑出距离已有连锁店超过10公里的城镇和已有连锁店的城镇,作为建立新连锁店的试点,再用按以下筛选模型建立的程序来筛选出满足销售量大于单个连锁店的销售能力下限(20吨)或者满足大于原有连锁店销售能力的1.2倍加上20吨的城镇。最后,通过比较各种兴建方式的销售量大小来确定建立新连锁店的城镇。而新连锁店的个数将用新建连锁店后该城镇的销售量减去原有连锁店的销售能力的1.2倍(原来没有连锁店的不需要减),再除以20取整便可。筛选过程如下:首先,找出除去已存在连锁店的城镇后需求量排在前20位的城镇表6筛选前的城镇表7筛选后的城镇然后由第2小问的结论,按片区挑选出距离已有的连锁店超过10公里的城镇。表8城镇号需求量(公斤
 三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 扫描二维码
扫描二维码









 heyi72
heyi72
本文标题:连锁店和生产基地增设以及货物配送问题数学建模
链接地址:https://www.777doc.com/doc-631006 .html