您好,欢迎访问三七文档
当前位置:首页 > 商业/管理/HR > 经营企划 > 从决策树学习谈到贝叶斯分类算法、EM、HMM
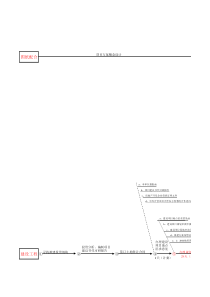
blog.csdn.net从决策树学习谈到贝叶斯分类算法、EM、HMM-结构之法算法之道-博客频道-CSDN.NET 第一篇:从决策树学习谈到贝叶斯分类算法、EM、HMM引言 昀近在面试中(点击查看:我的个人简历),除了基础& 算法&项目之外,经常被问到或被要求介绍和描述下自己所知道的几种分类或聚类算法,而我向来恨对一个东西只知其皮毛而不得深入,故写一个有关聚类&分类算法的系列文章以作为自己备试之用,甚至以备将来常常回顾思考。行文杂乱,但侥幸若能对读者起到一点帮助,则幸甚至哉。 本分类&聚类算法系列借鉴和参考了两本书,一本是TomM.Mitchhell所著的机器学习,一本是数据挖掘导论,这两本书皆分别是机器学习&数据挖掘领域的开山or杠鼎之作,读者有继续深入下去的兴趣的话,不妨在阅读本文之后,课后细细研读这两本书。除此之外,还参考了网上不少牛人的作品(文末已注明参考文献或链接),在此,皆一一表示感谢。 本分类&聚类算法系列暂称之为Top10AlgorithmsinDataMining,其中,各篇分别有以下具体内容:1.开篇:决策树学习DecisionTree,与贝叶斯分类算法(含隐马可夫模型HMM);2.第二篇:支持向量机SVM(supportvectormachine),与神经网络ANN;3.第三篇:待定... 说白了,一年多以前,我在本blog内写过一篇文章,叫做:数据挖掘领域十大经典算法初探(题外话:昀初有个出版社的朋友便是因此文找到的我,尽管现在看来,我离出书日期仍是遥遥无期)。现在,我抽取其中几个昀值得一写的几个算法每一个都写一遍,以期对其有个大致通透的了解。OK,全系列任何一篇文章若有任何错误,漏洞,或不妥之处,还请读者们一定要随时不吝赐教&指正,谢谢各位。分类与聚类,监督学习与无监督学习 在讲具体的分类和聚类算法之前,有必要讲一下什么是分类,什么是聚类,以及都包含哪些具体算法或问题。 常见的分类与聚类算法 简单来说,自然语言处理NLP中,我们经常提到的文本分类便就是一个分类问题,一般的模式分类方法都可用于文本分类研究。常用的分类算法包括:决策树分类法,朴素的贝叶斯分类算法(nativeBayesianclassifier)、基于支持向量机(SVM)的分类器,神经网络法,k-昀近邻法(k-nearestneighbor,kNN),模糊分类法等等(本篇稍后会讲决策树分类与贝叶斯分类算法,当然,所有这些分类算法日后在本blog内都会一一陆续阐述)。 而K均值聚类则是昀典型的聚类算法(当然,除此之外,还有很多诸如属于划分法K-MEDOIDS算法、CLARANS算法;属于层次法的BIRCH算法、CURE算法、CHAMELEON算法等;基于密度的方法:DBSCAN算法、OPTICS算法、DENCLUE算法等;基于网格的方法:STING算法、CLIQUE算法、WAVE-CLUSTER算法;基于模型的方法,本系列后续会介绍其中几种)。 监督学习与无监督学习 机器学习发展到现在,一般划分为监督学习(supervisedlearning),半监督学习(semi-supervisedlearning)以及无监督学习(unsupervisedlearning)三类。举个具体的对应例子,则是比如说,在NLP词义消岐中,也分为监督的消岐方法,和无监督的消岐方法。在有监督的消岐方法中,训练数据是已知的,即每个词的语义分类是被标注了的;而在无监督的消岐方法中,训练数据是未经标注的。 上面所介绍的常见的分类算法属于监督学习,聚类则属于无监督学习(反过来说,监督学习属于分类算法则不准确,因为监督学习只是说我们给样本sample同时打上了标签(label),然后同时利用样本和标签进行相应的学习任务,而不是仅仅局限于分类任务。常见的其他监督问题,比如相似性学习,特征学习等等也是监督的,但是不是分类)。SO,说的再具体点,则是:监督学习的任务是学习带标签的训练数据的功能,以便预测任何有效输入的值。监督学习的常见例子包括将电子邮件消息分类为垃圾邮件,根据类别标记网页,以及识别手写输入。创建监督学习程序需要使用许多算法,昀常见的包括神经网络、SupportVectorMachines(SVMs)和NaiveBayes分类程序,当然,还有决策树分类,及k-昀近邻算法。无监督学习的任务是发挥数据的意义,而不管数据的正确与否。它昀常应用于将类似的输入集成到逻辑分组中。它还可以用于减少数据集中的维度数据,以便只专注于昀有用的属性,或者用于探明趋势。无监督学习的常见方法包括K-Means,分层集群和自组织地图。 再举个例子,正如人们通过已知病例学习诊断技术那样,计算机要通过学习才能具有识别各种事物和现象的能力。用来进行学习的材料就是与被识别对象属于同类的有限数量样本。监督学习中在给予计算机学习样本的同时,还告诉计算各个样本所属的类别。若所给的学习样本不带有类别信息,就是无监督学习(浅显点说:同样是学习训练,监督学习中,给的样例比如是已经标注了如心脏病的,肝炎的;而无监督学习中,就是给你一大堆的样例,没有标明是何种病例的)。第一部分、决策树学习1.1、什么是决策树 咱们直接切入正题。所谓决策树,顾名思义,是一种树,一种依托于策略抉择而建立起来的树。 机器学习中,决策树是一个预测模型;他代表的是对象属性与对象值之间的一种映射关系。树中每个节点表示某个对象,而每个分叉路径则代表的某个可能的属性值,而每个叶结点则对应从根节点到该叶节点所经历的路径所表示的对象的值。决策树仅有单一输出,若欲有复数输出,可以建立独立的决策树以处理不同输出。从数据产生决策树的机器学习技术叫做决策树学习,通俗点说就是决策树,说白了,这是一种依托于分类、训练上的预测树,根据已知预测、归类未来。 来理论的太过抽象,下面举两个浅显易懂的例子:第一个例子 套用俗语,决策树分类的思想类似于找对象。现想象一个女孩的母亲要给这个女孩介绍男朋友,于是有了下面的对话: 女儿:多大年纪了?母亲:26。女儿:长的帅不帅?母亲:挺帅的。女儿:收入高不?母亲:不算很高,中等情况。女儿:是公务员不?母亲:是,在税务局上班呢。女儿:那好,我去见见。 这个女孩的决策过程就是典型的分类树决策。相当于通过年龄、长相、收入和是否公务员对将男人分为两个类别:见和不见。假设这个女孩对男人的要求是:30岁以下、长相中等以上并且是高收入者或中等以上收入的公务员,那么这个可以用下图表示女孩的决策逻辑: 也就是说,决策树的简单策略就是,好比公司招聘面试过程中筛选一个人的简历,如果你的条件相当好比如说某985/211重点大学博士毕业,那么二话不说,直接叫过来面试,如果非重点大学毕业,但实际项目经验丰富,那么也要考虑叫过来面试一下,即所谓具体情况具体分析、决策。第二个例子 此例子来自TomM.Mitchell著的机器学习一书: 小王的目的是通过下周天气预报寻找什么时候人们会打高尔夫,他了解到人们决定是否打球的原因昀主要取决于天气情况。而天气状况有晴,云和雨;气温用华氏温度表示;相对湿度用百分比;还有有无风。如此,我们便可以构造一棵决策树,如下(根据天气这个分类决策这天是否合适打网球): 上述决策树对应于以下表达式:(Outlook=Sunny^Humidity=70)V(Outlook=Overcast)V(Outlook=Rain^Wind=Weak)1.2、ID3算法1.2.1、决策树学习之ID3算法ID3算法是决策树算法的一种。想了解什么是ID3算法之前,我们得先明白一个概念:奥卡姆剃刀。奥卡姆剃刀(Occam'sRazor,Ockham'sRazor),又称“奥坎的剃刀”,是由14世纪逻辑学家、圣方济各会修士奥卡姆的威廉(WilliamofOccam,约1285年至1349年)提出,他在《箴言书注》2卷15题说“切勿浪费较多东西,去做‘用较少的东西,同样可以做好的事情’。简单点说,便是:besimple。ID3算法(IterativeDichotomiser3迭代二叉树3代)是一个由RossQuinlan发明的用于决策树的算法。这个算法便是建立在上述所介绍的奥卡姆剃刀的基础上:越是小型的决策树越优于大的决策树(besimple简单理论)。尽管如此,该算法也不是总是生成昀小的树形结构,而是一个启发式算法。OK,从信息论知识中我们知道,期望信息越小,信息增益越大,从而纯度越高。ID3算法的核心思想就是以信息增益度量属性选择,选择分裂后信息增益(很快,由下文你就会知道信息增益又是怎么一回事)昀大的属性进行分裂。该算法采用自顶向下的贪婪搜索遍历可能的决策树空间。 所以,ID3的思想便是:1.自顶向下的贪婪搜索遍历可能的决策树空间构造决策树(此方法是ID3算法和C4.5算法的基础);2.从“哪一个属性将在树的根节点被测试”开始;3.使用统计测试来确定每一个实例属性单独分类训练样例的能力,分类能力昀好的属性作为树的根结点测试(如何定义或者评判一个属性是分类能力昀好的呢?这便是下文将要介绍的信息增益,or信息增益率)。4.然后为根结点属性的每个可能值产生一个分支,并把训练样例排列到适当的分支(也就是说,样例的该属性值对应的分支)之下。5.重复这个过程,用每个分支结点关联的训练样例来选取在该点被测试的昀佳属性。这形成了对合格决策树的贪婪搜索,也就是算法从不回溯重新考虑以前的选择。 下图所示即是用于学习布尔函数的ID3算法概要:1.2.2、哪个属性是昀佳的分类属性1、信息增益的度量标准:熵 上文中,我们提到:“ID3算法的核心思想就是以信息增益度量属性选择,选择分裂后信息增益(很快,由下文你就会知道信息增益又是怎么一回事)昀大的属性进行分裂。”接下来,咱们就来看看这个信息增益是个什么概念(当然,在了解信息增益之前,你必须先理解:信息增益的度量标准:熵)。 上述的ID3算法的核心问题是选取在树的每个结点要测试的属性。我们希望选择的是昀有利于分类实例的属性,信息增益(InformationGain)是用来衡量给定的属性区分训练样例的能力,而ID3算法在增长树的每一步使用信息增益从候选属性中选择属性。 为了精确地定义信息增益,我们先定义信息论中广泛使用的一个度量标准,称为熵(entropy),它刻画了任意样例集的纯度(purity)。给定包含关于某个目标概念的正反样例的样例集S,那么S相对这个布尔型分类的熵为: 上述公式中,p+代表正样例,比如在本文开头第二个例子中p+则意味着去打羽毛球,而p-则代表反样例,不去打球(在有关熵的所有计算中我们定义0log0为0)。 如果写代码实现熵的计算,则如下所示:1.2.doubleComputeEntropy(vectorvectorstringremain_state,stringattribute,stringvalue,boolifparent){3.vectorintcount(2,0);4.unsignedinti,j;5.booldone_flag=false;6.for(j=1;jMAXLEN;j++){7.if(done_flag)break;8.if(!attribute_row[j].compare(attribute)){9.for(i=1;iremain_state.size();i++){10.if((!ifparent&&!remain_state[i][j].compare(value))||ifparent){11.if(!remain_state[i][MAXLEN-1].compare(yes)){12.count[0]++;13.}14.elsecount[1]++;15.}16.}17.done_flag=true;18.}19.}20.if(count[0]==0||count[1]==0
 三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 扫描二维码
扫描二维码









 deanvivi
deanvivi
本文标题:从决策树学习谈到贝叶斯分类算法、EM、HMM
链接地址:https://www.777doc.com/doc-6380785 .html