您好,欢迎访问三七文档
当前位置:首页 > 临时分类 > 用最优化方法解决BP神经网络训练问题
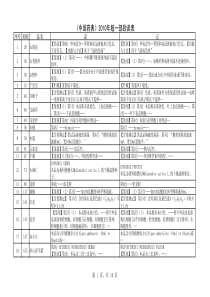
龙源期刊网用最优化方法解决BP神经网络训练问题作者:李翔苏成来源:《电脑知识与技术·学术交流》2008年第12期摘要:BP神经网络可以有效地对非线性系统进行逼近,但是传统的最速下降搜索方法存在收敛速度慢的问题。本文提出把BP神经网络转化为最优化问题,用一种共轭梯度算法代替最速下降法进行搜索迭代,极大地提高了收敛速度。关键词:神经网络;最优化;一种共轭梯度算法中图分类号:TP183文献标识码:A文章编号:1009-3044(2008)12-20000-00TrainingBPNeuralNetworkusingoptimizationmethodsLIXiang,SUCheng(Collegeofcomputerscience,ChinaUniversityofMiningandTechnology,Xuzhou221000,China)Abstract:BPneuralnetworkcanefficientlyapproximateanynonlinearsystem,butthereisaproblemofinefficientlearningspeedwiththeconventionalsteepestdescentalgorithm.Inthispaper,wetrytoconvertneuralnetworktoanoptimizationmodel,andapplyconjugategradientalgorithmtoittobringafasterlearningspeed.Keywords:Neuralnetwork;Optimization;Conjugategradientalgorithm1BP神经网络模型BP(前馈式)神经网络结构简单,可操作性强,能模拟任意的非线性输入输出系统,是目前应用广泛的神经网络模型。BP网络由输入层i、隐含层j、输出层k及各层之间的节点连接权组成,神经元拓扑如图1:网络的学习过程由信息正向传播和误差反向传播构成:龙源期刊网正向传播过程:输入信息从输入层经隐含层逐层处理,传向输出层。若输出层的实际输出与期望的输出不符,则转入误差的反向传播。典型的BP神经网络模型如图2所示:设网络中各个参数如下:xi为输入信号,yi为实际输出信号,Yi为期望输出信号wi为对应于各个输入信号的连接权值,θ为阈值,ε为给定的误差。(1)输入层:输入值一般为样本各分量输入值,输出值一般等于输入值xi。(2)隐含层:对于节点j,其输入值hj为其前一层各节点输出值xi的加权和,它的输出值为:(lixiang03.tif)(3)输出层:输出层类似于隐含层(lixiang04.tif)神经元结点的作用函数一般选用Sigmoid函数,即:(lixiang05.tif)误差函数一般选用(lixiang06.tif)神经网络的训练过程就是按最小误差准则来不断调整网络结点的权值,直至误差可以看到,BP神经网络实际可转化为求解一个最优化问题,它的目标函数是(lixiang07.tif)。2最速下降法2.1基本搜索方法针对神经网络的最优化问题,传统的搜索方法选用最速下降法,即通过多次迭代,对网络权值进行修正,使误差目标函数沿负梯度方向下降,迭代的公式如下:(lixiang08.tif)龙源期刊网这种方法在刚开始几步有较好的收敛效果,但当迭代深入后容易陷入振荡,出现锯齿现象,导致结果精度不够,训练过程较长。2.2纯梯度方法的改进针对最速下降法收敛速度慢的问题,很多研究者提出了一些改进方法,主要有以下几种:(1)确定学习率在基本网络算法中,Δwi=wi(t+1)-wi(t)引用了固定的学习率η=1,为了更好的控制网络的收敛性和学习速度,可以根据需要选择自适应的变学习率,一般取0(lixiang10.tif)学习步长η是网络学习的一个重要参数,在一定程度上也决定了网络的收敛速度。学习步长过小会导致权重值更新量过小,因而使收敛非常缓慢;学习步长过大又会导致在极值点附近振荡的可能性加大,乃至反复振荡而难以收敛。具体数值应根据对误差函数的影响来决定。(2)加入动量项这种措施又称为惯性校正法,其权值调整公式可用下式表示:(lixiang11.tif)α为动量系数,这种方法在调整权值时,不仅考虑了本次迭代,而且兼顾上次的调整结果,能够在加速收敛的同时一定程度地抑制振荡。(3)改进误差函数在基本网络算法中,引用的误差函数是(lixiang12.tif)。可以看到,这是一个误差的绝对量,不能有效地表征样本的相对误差程度。对于某个节点会出现误差的绝对量很大但是比例却很小的情况。为了避免上述问题,引入相对误差函数:首先,对(lixiang13.tif)变形,(lixiang14.tif),把不含有实际输出的Y提出,得到相对误差函数(lixiang15.tif)。相对误差函数Jp使用误差量的相对比例来表征样本误差ε,具有更好的效果。类似的针对最速下降法的改进方法还有很多,但是它们无法从根本上解决纯梯度方法的局部振荡性,收敛速度慢的问题仍然有待解决。为了解决收敛速度慢的问题,本文采用共轭梯度法代替沿负梯度方向的最速下降法,它比最速下降法在收敛速度上有很大的改进。龙源期刊网共轭梯度法是求解无约束优化问题(lixiang16.tif)的一类非常有效的方法,它的迭代格式为(lixiang17.tif)其中,(lixiang29.tif),dk为搜索方向,而αk0是通过某种线搜索获得的步长。纯量βk的选取应满足共轭性,βk的不同取法构成了不同的共轭梯度法。常用的有FR相关法(lixiang18.tif)和PRP相关法(lixiang19.tif)。为保证算法的强收敛性,本文选取一种新的共轭梯度法,它的βk公式如下:(lixiang20.tif)选取这种共轭梯度法的理由在于它在Wolfe搜索(lixiang21.tif)下具有全局收敛性质并且计算效果好于PRP等算法[1]。3.2搜索算法描述首先采用最速下降法先达到一个初步精度W(0)。实验表明,最速下降法“开局”的收敛速度是较好的。第二阶段采用共轭梯度法,步骤如下:(1)把最速下降法得到的初步精度作为初始权值W(0),并选定误差最终精度值ε。(2)置迭代次数k=0;(3)计算目标函数(lixiang22.tif)和(lixiang23.tif);(4)若k=0,令(lixiang24.tif);否则,(lixiang25.tif);其中(lixiang26.tif);(5)一维搜索求取步长αk,使其满足Wolfe搜索条件(lixiang27.tif)龙源期刊网=wk+αkdk;(6)计算J=f(wk+1);若J3.3算法实例本文利用以上算法对一个函数y=x12+x22+x32实现逼近,以Δx=0.1为步长取得多组训练样本数据对[x1,x2,x3,f(x1,x2,x3)]。构建三层前馈式神经网络,其中输入层为(x1,x2,x3),隐层结点取4个,它的权值为向量w,初始值取wi=0.5,i=1,2..4,期望输出为Y=f(x1,x2,x3),取定神经元的作用函数为Sigmoid函数(lixiang05.tif)阈值为θ,ε为给定的误差,取ε=10-4,则共轭搜索的目标函数为:(lixiang12.tif),原神经网络问题可转化为求最优化问题min(J),使用上述搜索算法得目标函数J的收敛数据如表1:4结论实验表明共轭梯度法具有较好的收敛特性,并且不会产生振荡,可以有效地解决传统BP网络的收敛速度问题。并且本文选用的因子在wolfe搜索下可以保证全局收敛性,比一般的因子有更好的效果。参考文献:[1]戴彧虹.非线性共轭梯度法研究[D].中国科学院计算数学与科学工程研究所,博士学位论文,1997.[2]DaiYH,YUANY.ANonlinearconjugategradientwithastrongglobalconvergenceproperty[J].SIAMJournalofoptimization,2000(10):177-182.[3]黄兆龙.用启发算法和神经网络法解决二维不规则零件排样问题[J].微计算机信息,2004(10):51-53.[4]杜华英,赵跃龙.人工神经网络典型模型的比较研究[J].计算机技术与发展,2006(05):97-99.[5]陆琼瑜,童学锋.BP算法改进的研究[J].计算机工程与设计,2007(03):648-650.龙源期刊网收稿日期:2008-03-27作者简介:李翔(1981-)男,江苏徐州人,中国矿业大学硕士研究生,主要从事神经网络,数据挖掘的研究;苏成,男,中国矿业大学副教授,硕士生导师,主要从事访问控制,网络安全的研究。注:“本文中所涉及到的图表、注解、公式等内容请以PDF格式阅读原文。”
 三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 扫描二维码
扫描二维码









 lovepeipei_ever
lovepeipei_ever
本文标题:用最优化方法解决BP神经网络训练问题
链接地址:https://www.777doc.com/doc-8569663 .html