您好,欢迎访问三七文档
当前位置:首页 > 行业资料 > 其它行业文档 > 第4章参数估计和假设检验.
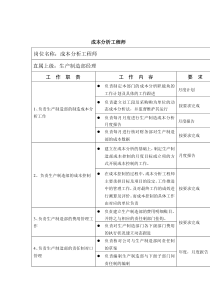
中央财经大学统计学院参数估计与假设检验4.1参数估计4.2假设检验中央财经大学统计学院24.1参数估计4.1.1参数估计的基本概念4.1.2总体均值和比例的区间估计4.1.3必要样本容量的确定中央财经大学统计学院34.1.1参数估计的基本概念总体样本算术平均数x统计量用来推断总体参数的统计量称为估计量(estimator),其取值称为估计值(estimate)。同一个参数可以有多个不同的估计量。参数是唯一的,但估计量(统计量)是随机变量,取值是不确定的。?参数中央财经大学统计学院4点估计点估计:用估计量的数值作为总体参数的估计值。一个总体参数的估计量可以有多个。例如,在估计总体方差时,和都可以作为估计量。nxxnii12)(1)(12nxxnii中央财经大学统计学院5点估计量的常用评价准则:无偏性无偏性:估计量的数学期望与总体待估参数的真值相等:ˆ()EP()BA无偏有偏ˆˆ中央财经大学统计学院6点估计量的常用评价准则:有效性在两个无偏估计量中方差较小的估计量较为有效。AB的抽样分布的抽样分布1ˆ2ˆP()ˆˆ中央财经大学统计学院7估计量的常用评价准则:一致性指随着样本容量的增大,估计量越来越接近被估计的总体参数。AB较小的样本容量较大的样本容量P(X)X中央财经大学统计学院8区间估计根据事先确定的置信度1-给出总体参数的一个估计范围。置信度1-的含义是:在同样的方法得到的所有置信区间中,有100(1-)%的区间包含总体参数。抽样分布是区间估计的理论基础。估计值(点估计)置信下限置信上限置信区间抽样分布SamplingDistribution从总体中抽取一个样本量为n的随机样本,我们可以计算出统计量的一个值。如果从总体中重复抽取样本量为n的样本,就可以得到统计量的多个值。统计量的抽样分布就是这一统计量所有可能值的概率分布。中央财经大学统计学院10抽样分布:几个要点抽样分布是统计量的分布而不是总体或样本的分布。在统计推断中总体的分布一般是未知的,不可观测的(常常被假设为正态分布)。样本数据的统计分布是可以直接观测的,最直观的方式是直方图,可以用来对总体分布进行检验。抽样分布一般利用概率统计的理论推导得出,在应用中也是不能直接观测的。其形状和参数可能完全不同于总体或样本数据的分布。中央财经大学统计学院11抽样分布的一个演示:重复抽样时样本均值的抽样分布(1)设一个总体含有4个个体,分别为X1=1、X2=2、X3=3、X4=4。总体的均值、方差及分布如下。均值和方差5.21NXNii25.1)(122NXNii总体的频数分布14230.1.2.3中央财经大学统计学院12抽样分布的一个演示:重复抽样时样本均值的抽样分布(2)现从总体中抽取n=2的简单随机样本,在重复抽样条件下,共有42=16个样本。所有样本的结果如下表.3,43,33,23,132,42,32,22,124,44,34,24,141,441,33211,21,11第二个观察值第一个观察值所有可能的n=2的样本(共16个)中央财经大学统计学院13抽样分布的一个演示:重复抽样时样本均值的抽样分布(3)各样本的均值如下表,并给出样本均值的抽样分布x样本均值的抽样分布1.00.1.2.3P(x)1.53.04.03.52.02.53.53.02.52.033.02.52.01.524.03.53.02.542.542.03211.51.01第二个观察值第一个观察值16个样本的均值(x)中央财经大学统计学院14所有样本均值的均值和方差1.样本均值的均值(数学期望)等于总体均值2.样本均值的方差等于总体方差的1/nnMxnixix222122625.016)5.20.4()5.20.1()(5.2160.45.10.11MxniixM为样本数目中央财经大学统计学院15样本均值的抽样分布与总体分布的比较=2.5σ2=1.25总体分布14230.1.2.3抽样分布5.2x625.02x样本均值的抽样分布1.00.1.2.3P(x)1.53.04.03.52.02.5中央财经大学统计学院16样本均值的抽样分布=50=10X总体分布n=4抽样分布X5x50xn=165.2x一般的,当总体服从N(μ,σ2)时,来自该总体的容量为n的样本的均值X也服从正态分布,X的期望为μ,方差为σ2/n。即X~N(μ,σ2/n)。f(X)X小样本中心极限定理从均值为,方差为2的一个任意总体中抽取容量为n的样本,当n充分大时,样本均值的抽样分布近似服从均值为μ、方差为σ2/n的正态分布。大样本(n30)xnx中央财经大学统计学院18标准误(StandardError)简单随机抽样、重复抽样时,样本均值抽样分布的标准差等于,这个指标在统计上称为标准误。统计软件在对变量进行描述统计时一般会输出这一结果。n中央财经大学统计学院19有限总体校正系数FinitePopulationCorrectionFactor简单随机抽样、不重复抽样时,样本均值抽样分布的方差略小于重复抽样的方差,等于这一系数称为有限总体校正系数。当抽样比(n/N)0.05时可以忽略有限总体校正系数。12NnNn1NnN中央财经大学统计学院204.2总体均值和比例的区间估计中央财经大学统计学院21相关理论总体正态?n≥30?σ2已知?否是是否否是实际中总体方差总是未知的,因而这是应用最多的公式。在大样本时t值可以用z值来近似。根据中心极限定理得到的近似结果。σ未知时用s来估计。nZx2nstx2nZx2增大n?数学变换?中央财经大学统计学院22当时总体比例的置信区间可以使用正态分布来进行区间估计。(样本比例记为,总体比例记为π)总体比例的置信区间)1,0(~)1(ˆNnpznppZp)ˆ1(ˆˆ25)ˆ1(,5ˆpnpnpˆ中央财经大学统计学院23关于置信区间的补充说明置信区间的推导:有限总体不重复抽样时,样本均值或比例的方差需要乘以“有限总体校正系数”(当抽样比f=n/N小于0.05时可以忽略不计),前面的公式需要进行相应的修改。12/ZnxPnZxnZx221NnNnx1)ˆ1(ˆˆNnNnppp中央财经大学统计学院24关于置信度含义的说明样本均值的抽样分布在所有的置信区间中,有(1-)*100%的区间包含总体真实值。对于计算得到的一个具体区间,“这个区间包含总体真实值”这一结论有(1-)*100%的可能是正确的。说“总体均值有95%的概率落入某一区间”是不严格的,因为总体均值是非随机的。=1-/2/2X_σx_xExample:用SPSS进行区间估计例:儿童电视节目的赞助商希望了解儿童每周看电视的时间。下面是对100名儿童进行随机调查的结果(小时)。计算平均看电视时间95%的置信区间。39.719.534.727.041.315.120.531.318.317.021.529.915.016.436.823.424.128.923.424.440.646.423.639.435.519.529.331.220.634.915.531.638.938.727.226.514.715.628.424.043.920.629.19.521.042.413.932.829.832.933.038.028.720.619.738.637.117.015.123.421.021.829.321.322.823.432.511.343.830.815.823.220.333.530.037.824.426.929.027.727.122.036.123.022.126.522.926.930.225.223.835.321.635.730.822.724.521.926.550.3SPSS输出结果(数据:tv.xls)操作:分析-描述统计-探索统计量标准误均值27.191.8373均值的95%置信区间下限25.530上限28.8525%修整均值26.977中值26.500方差70.104标准差8.3728极小值9.5极大值50.3中央财经大学统计学院27总体比例的置信区间:例子解:显然有因此可以用正态分布进行估计。Z/2=1.6450215.0217.0995)217.01(217.0645.1217.0)ˆ1(ˆˆ2nppZp结论:我们有90%的把握认为悉尼青少年中每天都抽烟的青少年比例在19.55%~23.85%之间。1986年对悉尼995名青少年的随机调查发现,有216人每天都抽烟。试估计悉尼青少年中每天都抽烟的青少年比例的90%的置信区间。5)ˆ1(,5ˆpnpnSPSS的计算结果在SPSS中将“是否吸烟”输入为取值为1和0的属性变量,权数分别为216和779。计算这一变量均值的置信区间即为比例的置信区间。统计量标准误均值.2171.01308均值的90%置信区间下限.1956上限.23865%修整均值.1857中值.0000方差.170标准差.41247极小值.00极大值1.00范围1.00四分位距.00中央财经大学统计学院294.3必要样本量的计算样本量越大抽样误差越小。由于调查成本方面的原因,在调查中我们总是希望抽取满足误差要求的最小的样本量。中央财经大学统计学院30关于抽样误差的几个概念实际抽样误差抽样平均误差最大允许误差中央财经大学统计学院31实际抽样误差样本估计值与总体真实值之间的绝对离差称为实际抽样误差。由于在实践中总体参数的真实值是未知的,因此实际抽样误差是不可知的;由于样本估计值随样本而变化,因此实际抽样误差是一个随机变量。|ˆ|抽样平均误差抽样平均误差:样本均值的标准差,也就是前面说的标准误。它反映样本均值(或比例)与总体均值(比例)的平均差异程度。例如对简单随机抽样中的样本均值有:或(不重复抽样)我们通常说“抽样调查中可以对抽样误差进行控制”,就是指的抽样平均误差。由上面的公式可知影响抽样误差的因素包括:总体内部的差异程度;样本容量的大小;抽样的方式方法。nx1NnNnx2ˆ)ˆ(E中央财经大学统计学院33最大允许误差最大允许误差(allowableerror):在确定置信区间时样本均值(或样本比例)加减的量,一般用E来表示,等于置信区间长度的一半。在英文文献中也称为marginoferror。置信区间=最大允许误差是人为确定的,是调查者在相应的置信度下可以容忍的误差水平。Ex中央财经大学统计学院34如何确定必要样本量?必要样本量受以下几个因素的影响:1、总体标准差。总体的变异程度越大,必要样本量也就越大。2、最大允许误差。最大允许误差越大,需要的样本量越小。3、置信度1-。要求的置信度越高,需要的样本量越大。4、抽样方式。其它条件相同,在重复抽样、不重复抽样;简单随机抽样与分层抽样等不同抽样方式下要求的必要样本容量也不同。中央财经大学统计学院35简单随机抽样下估计总体均值时样本容量的确定2222/2/,EZnnZE式中的总体方差可以通过以下方式估计:根据历史资料确定通过试验性调查估计中央财经大学统计学院36简单随机抽样下估计总体比例时样本容量的确定222/)1(,)1(2/EZnnZE式中的总体比例π可以通过以下方式估计:根据历史资料确定通过试验性调查估计取为0.5。中央财经大学统计学院37不重复抽样时的必要样本量比重复抽样时的必要样本量要小。式中n0是重复抽样时的必要样本容量。Nnnn001中央财经大学统计学院38样本量的确定(实例1)需要多大规模的样本才能在90%的置信水平上保证均值
 三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 扫描二维码
扫描二维码








 greatfuldays
greatfuldays
本文标题:第4章参数估计和假设检验.
链接地址:https://www.777doc.com/doc-1803551 .html