当前位置:首页 > IT计算机/网络 > 电子商务 > 数据挖掘可视化系统研究与实现
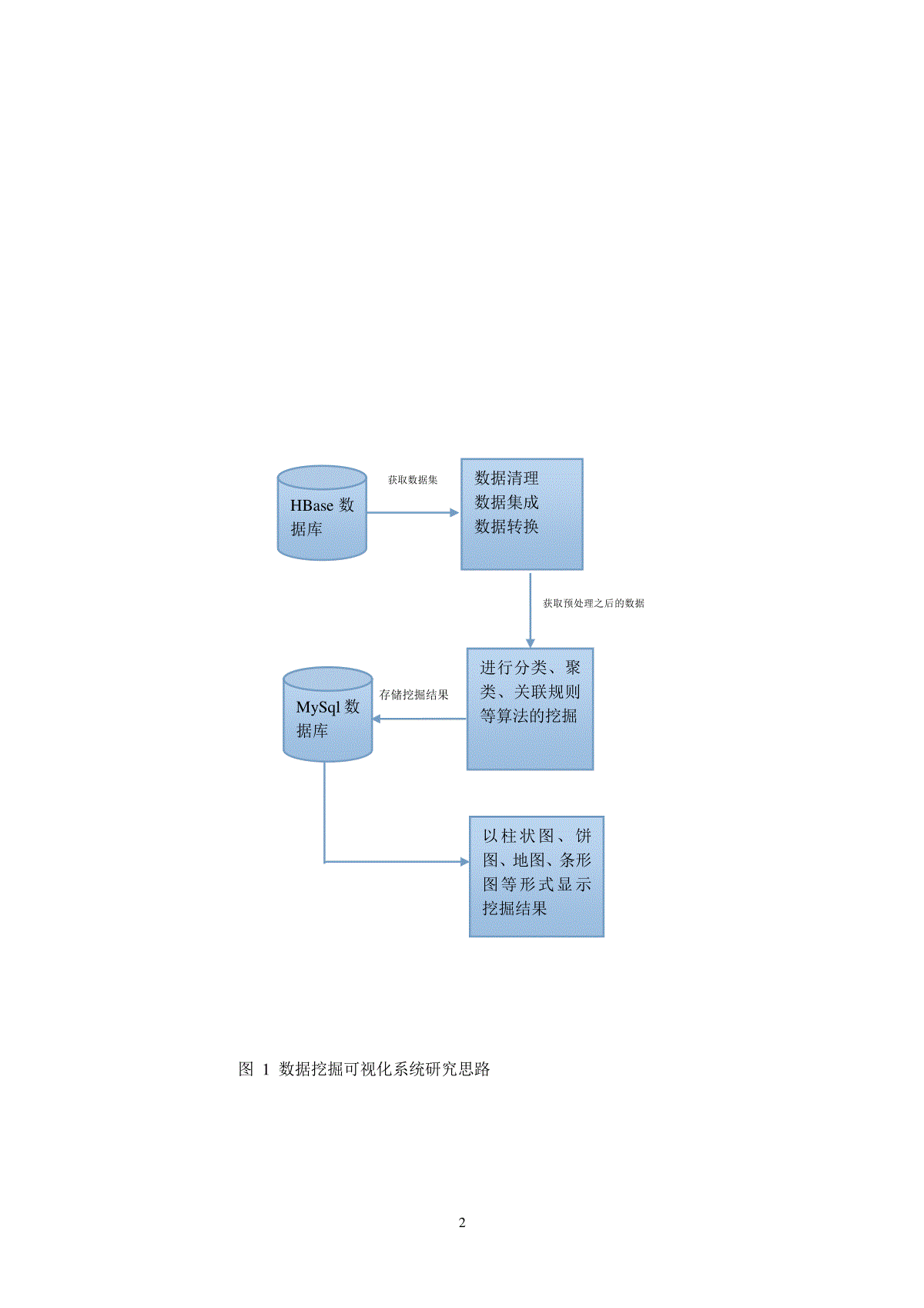
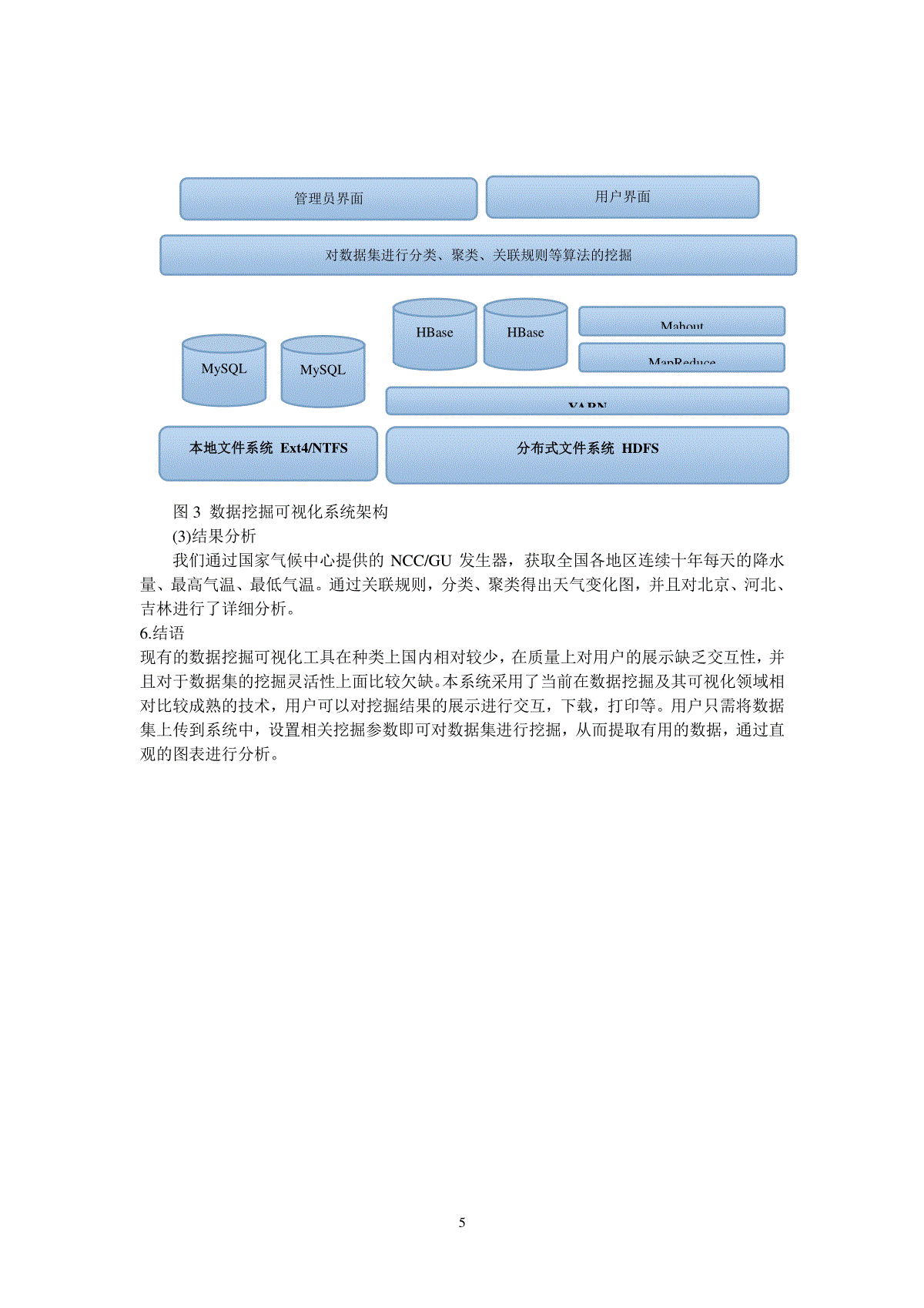
1数据挖掘可视化系统设计与实现摘要:针对当前数据可视化工具的种类、质量和灵活性的存在的不足,构建一个数据挖掘可视化平台。将获取的数据集上传到系统中,对数据集进行预处理,利用Mahout提供的分类、聚类等挖掘算法对数据集进行挖掘,使用ECharts将挖掘产生的结果进行可视化展示。关键词:数据挖掘;可视化展示;数据预处理;挖掘算法1引言大数据时代,通过数据挖掘,可以对数据库中的大量业务数据进行抽取、转换、分析和其他模型化处理,从而提取辅助商业决策的关键性信息。丰富而灵活的数据挖掘结果可视化技术使抽象的信息以简明的形式呈现出来,加深用户对数据含义的理解,更好地了解数据之间的相互关系和发展趋势。然而当前数据可视化工具的种类、质量和灵活性较大的影响数据挖掘系统的使用、解释能力和吸引力。为此,本系统使用分布式大数据处理技术进行数据的存储和计算,构建一个数据挖掘可视化平台,以多种挖掘算法的实现对原始数据集进行挖掘,从而发现数据中有用的信息。2.关键技术(1)MapReduce离线计算框架一种在YARN系统之上的大数集离线计算框架,使用MapReduce可以并行的对原始数据集进行计算处理,从而高效的得出结果。(2)HBase分布式数据库HBase是一个构建在Hadoop之上分布式的、面向列的开源数据库。HBase不同于一般的关系数据库,他是一个适合于非结构化数据存储的数据库。(3)MahoutMahout是ApacheSoftwareFoundation旗下的一个开源项目,提供一些可扩展的机器学习领域经典算法的实现。包括聚类、分类、推荐过滤、频繁子项挖掘等算法的实现。(4)EChartsEcharts是百度团队对ZRender做了一次大规模重构的产物。他被定义为商业级报表,创建了坐标系,图例,提示,工具箱等基础组件,并在此上构建出折线图、柱状图、散点图、K线图、饼图、雷达图、地图、和弦图、力导向布局图、仪表盘以及漏斗图,同时支持任意纬度的堆积和多图表混合实现。3.研究思路数据挖掘可视化系统包括以下模块:(1)前台展示通过对上传的数据集处理、挖掘、分析,将有价值的信息结果以图形化的形式展现给用户。(2)数据集的存储将要处理的数据集存储到HBase数据库中。HBase数据库能够对大数据提供随机、实时的读写访问功能。(3)后台数据处理通过使用Mahout数据挖掘包,对挖掘算法进行相关参数的设定,对从数据库中提取的数据集进行挖掘,从而提取出有用的信息。具体如图1所示:2图1数据挖掘可视化系统研究思路获取数据集获取预处理之后的数据集存储挖掘结果HBase数据库数据清理数据集成数据转换进行分类、聚类、关联规则等算法的挖掘MySql数据库以柱状图、饼图、地图、条形图等形式显示挖掘结果34、系统设计数据预处理、挖掘算法、可视化显示是数据可视化系统的三大核心模块,系统组建图如图2所示。图2数据挖掘可视化系统组建图(1)数据预处理通过系统提供的上传接口将数据集上传到分布式数据库HBase中,当用户需要对数据集进行挖掘,系统首先检查数据集是否符合系统规定,如果符合规定对数据集进行预处理。经过处理后的的数据集即可通过系统进行相关需求的数据挖掘。(2)挖掘算法系统使用开源的数据挖掘框架Mahout,用户只需对所需挖掘的算法进行相关的参数设定,即可完成相关算法的挖掘。(3)可视化显示挖掘之后的相关结果存放到MySql数据库中,前台从数据库中获取挖掘结果,并且使用ECharts进行可视化显示,用户可以通过前台提供的可视化结果进行数据分析,从而获取自己所需要的信息。45.系统实现(1)关键技术数据挖掘可视化系统使用的关键技术如表1所示。表1系统开发技术简介功能名称版本操作系统Linux(Ubuntui686)14.04LTS开发语言JAVA(JDK)1.7.0_67关系型数据库MySql5.6分布式数据库HBase0.96.2分布式计算框架MapReduce2.2.0图形化展示ECharts2.2.0数据挖掘包Mahout0.9Web框架JFinal1.9(2)系统架构本系统在操作系统之上构造了HDFS分布式文件系统,本地文件系统与分布式文件系统共同存在。在本地文件系统之上组织了关系型数据库MySql和分布式数据库HBase集群,其中MySql用来存储管理员账户信息和少量的数据信息,HBase用来存储用户上传的数据集。文件系统和数据库之上使用分布式计算框架MapReduce和Mahout数据挖掘包,对用户的数据集进行分类、聚类、关联规则等算法的挖掘。后台管理员界面负责选择数据集以及挖掘参数的设定,前台用户界面通过图表形式展示挖掘结果,帮助用户进行数据分析。系统架如图3所示。5图3数据挖掘可视化系统架构(3)结果分析我们通过国家气候中心提供的NCC/GU发生器,获取全国各地区连续十年每天的降水量、最高气温、最低气温。通过关联规则,分类、聚类得出天气变化图,并且对北京、河北、吉林进行了详细分析。6.结语现有的数据挖掘可视化工具在种类上国内相对较少,在质量上对用户的展示缺乏交互性,并且对于数据集的挖掘灵活性上面比较欠缺。本系统采用了当前在数据挖掘及其可视化领域相对比较成熟的技术,用户可以对挖掘结果的展示进行交互,下载,打印等。用户只需将数据集上传到系统中,设置相关挖掘参数即可对数据集进行挖掘,从而提取有用的数据,通过直观的图表进行分析。本地文件系统Ext4/NTFS分布式文件系统HDFSMySQLMySQLYARNHBaseHBaseMapReduce对数据集进行分类、聚类、关联规则等算法的挖掘Mahout管理员界面用户界面



 三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 扫描二维码
扫描二维码










 zhangqin1
zhangqin1
本文标题:数据挖掘可视化系统研究与实现
链接地址:https://www.777doc.com/doc-2333447 .html