您好,欢迎访问三七文档
当前位置:首页 > IT计算机/网络 > 数据挖掘与识别 > 文章分享一个常见的大数据术语表
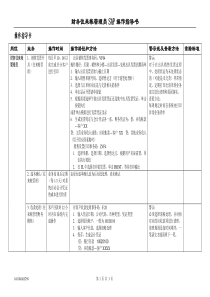
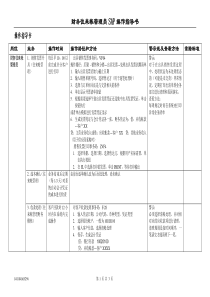
一个常见的大数据术语表(中英对照简版)大数据大数据的出现带来了许多新的术语,但这些术语往往比较难以理解。因此,我们通过本文给出一个常用的大数据术语表,抛砖引玉,供大家深入了解A聚合(Aggregation)–搜索、合并、显示数据的过程算法(Algorithms)–可以完成某种数据分析的数学公式分析法(Analytics)–用于发现数据的内在涵义异常检测(Anomalydetection)–在数据集中搜索与预期模式或行为不匹配的数据项。除了“Anomalies”,用来表示异常的词有以下几种:outliers,exceptions,surprises,contaminants.他们通常可提供关键的可执行信息匿名化(Anonymization)–使数据匿名,即移除所有与个人隐私相关的数据应用(Application)–实现某种特定功能的计算机软件人工智能(ArtificialIntelligence)–研发智能机器和智能软件,这些智能设备能够感知周遭的环境,并根据要求作出相应的反应,甚至能自我学习B行为分析法(BehaviouralAnalytics)–这种分析法是根据用户的行为如“怎么做”,“为什么这么做”,以及“做了什么”来得出结论,而不是仅仅针对人物和时间的一门分析学科,它着眼于数据中的人性化模式大数据科学家(BigDataScientist)–能够设计大数据算法使得大数据变得有用的人大数据创业公司(Bigdatastartup)–指研发最新大数据技术的新兴公司生物测定术(Biometrics)–根据个人的特征进行身份识别B字节(BB:Brontobytes)–约等于1000YB(Yottabytes),相当于未来数字化宇宙的大小。1B字节包含了27个0!商业智能(BusinessIntelligence)–是一系列理论、方法学和过程,使得数据更容易被理解C分类分析(Classificationanalysis)–从数据中获得重要的相关性信息的系统化过程;这类数据也被称为元数据(metadata),是描述数据的数据云计算(Cloudcomputing)–构建在网络上的分布式计算系统,数据是存储于机房外的(即云端)聚类分析(Clusteringanalysis)–它是将相似的对象聚合在一起,每类相似的对象组合成一个聚类(也叫作簇)的过程。这种分析方法的目的在于分析数据间的差异和相似性冷数据存储(Colddatastorage)–在低功耗服务器上存储那些几乎不被使用的旧数据。但这些数据检索起来将会很耗时对比分析(Comparativeanalysis)–在非常大的数据集中进行模式匹配时,进行一步步的对比和计算过程得到分析结果复杂结构的数据(Complexstructureddata)–由两个或多个复杂而相互关联部分组成的数据,这类数据不能简单地由结构化查询语言或工具(SQL)解析计算机产生的数据(Computergenerateddata)–如日志文件这类由计算机生成的数据并发(Concurrency)–同时执行多个任务或运行多个进程相关性分析(Correlationanalysis)–是一种数据分析方法,用于分析变量之间是否存在正相关,或者负相关客户关系管理(CRM:CustomerRelationshipManagement)–用于管理销售、业务过程的一种技术,大数据将影响公司的客户关系管理的策略D仪表板(Dashboard)–使用算法分析数据,并将结果用图表方式显示于仪表板中数据聚合工具(Dataaggregationtools)–将分散于众多数据源的数据转化成一个全新数据源的过程数据分析师(Dataanalyst)–从事数据分析、建模、清理、处理的专业人员数据库(Database)–一个以某种特定的技术来存储数据集合的仓库数据库即服务(Database-as-a-Service)–部署在云端的数据库,即用即付,例如亚马逊云服务(AWS:AmazonWebServices)数据库管理系统(DBMS:DatabaseManagementSystem)–收集、存储数据,并提供数据的访问数据中心(Datacentre)–一个实体地点,放置了用来存储数据的服务器数据清洗(Datacleansing)–对数据进行重新审查和校验的过程,目的在于删除重复信息、纠正存在的错误,并提供数据一致性数据管理员(Datacustodian)–负责维护数据存储所需技术环境的专业技术人员数据道德准则(Dataethicalguidelines)–这些准则有助于组织机构使其数据透明化,保证数据的简洁、安全及隐私数据订阅(Datafeed)–一种数据流,例如Twitter订阅和RSS数据集市(Datamarketplace)–进行数据集买卖的在线交易场所数据挖掘(Datamining)–从数据集中发掘特定模式或信息的过程数据建模(Datamodelling)–使用数据建模技术来分析数据对象,以此洞悉数据的内在涵义数据集(Dataset)–大量数据的集合数据虚拟化(Datavirtualization)–数据整合的过程,以此获得更多的数据信息,这个过程通常会引入其他技术,例如数据库,应用程序,文件系统,网页技术,大数据技术等等去身份识别(De-identification)–也称为匿名化(anonymization),确保个人不会通过数据被识别判别分析(Discriminantanalysis)–将数据分类;按不同的分类方式,可将数据分配到不同的群组,类别或者目录。是一种统计分析法,可以对数据中某些群组或集群的已知信息进行分析,并从中获取分类规则。分布式文件系统(DistributedFileSystem)–提供简化的,高可用的方式来存储、分析、处理数据的系统文件存贮数据库(DocumentStoreDatabases)–又称为文档数据库(document-orienteddatabase),为存储、管理、恢复文档数据而专门设计的数据库,这类文档数据也称为半结构化数据E探索性分析(Exploratoryanalysis)–在没有标准的流程或方法的情况下从数据中发掘模式。是一种发掘数据和数据集主要特性的一种方法E字节(EB:Exabytes)–约等于1000PB(petabytes),约等于1百万GB。如今全球每天所制造的新信息量大约为1EB提取-转换-加载(ETL:Extract,TransformandLoad)–是一种用于数据库或者数据仓库的处理过程。即从各种不同的数据源提取(E)数据,并转换(T)成能满足业务需要的数据,最后将其加载(L)到数据库F故障切换(Failover)–当系统中某个服务器发生故障时,能自动地将运行任务切换到另一个可用服务器或节点上容错设计(Fault-tolerantdesign)–一个支持容错设计的系统应该能够做到当某一部分出现故障也能继续运行G游戏化(Gamification)–在其他非游戏领域中运用游戏的思维和机制,这种方法可以以一种十分友好的方式进行数据的创建和侦测,非常有效。图形数据库(GraphDatabases)–运用图形结构(例如,一组有限的有序对,或者某种实体)来存储数据,这种图形存储结构包括边缘、属性和节点。它提供了相邻节点间的自由索引功能,也就是说,数据库中每个元素间都与其他相邻元素直接关联。网格计算(Gridcomputing)–将许多分布在不同地点的计算机连接在一起,用以处理某个特定问题,通常是通过云将计算机相连在一起。HHadoop–一个开源的分布式系统基础框架,可用于开发分布式程序,进行大数据的运算与存储。Hadoop数据库(HBase)–一个开源的、非关系型、分布式数据库,与Hadoop框架共同使用HDFS–Hadoop分布式文件系统(HadoopDistributedFileSystem);是一个被设计成适合运行在通用硬件(commodityhardware)上的分布式文件系统高性能计算(HPC:High-Performance-Computing)–使用超级计算机来解决极其复杂的计算问题I内存数据库(IMDB:In-memory)–一种数据库管理系统,与普通数据库管理系统不同之处在于,它用主存来存储数据,而非硬盘。其特点在于能高速地进行数据的处理和存取。物联网(InternetofThings)–在普通的设备中装上传感器,使这些设备能够在任何时间任何地点与网络相连。J法律上的数据一致性(Juridicaldatacompliance)–当你使用的云计算解决方案,将你的数据存储于不同的国家或不同的大陆时,就会与这个概念扯上关系了。你需要留意这些存储在不同国家的数据是否符合当地的法律。K键值数据库(KeyValueDatabases)–数据的存储方式是使用一个特定的键,指向一个特定的数据记录,这种方式使得数据的查找更加方便快捷。键值数据库中所存的数据通常为编程语言中基本数据类型的数据。L延迟(Latency)–表示系统时间的延迟遗留系统(Legacysystem)–是一种旧的应用程序,或是旧的技术,或是旧的计算系统,现在已经不再支持了。负载均衡(Loadbalancing)–将工作量分配到多台电脑或服务器上,以获得最优结果和最大的系统利用率。位置信息(Locationdata)–GPS信息,即地理位置信息。日志文件(Logfile)–由计算机系统自动生成的文件,记录系统的运行过程。MM2M数据(Machine2Machinedata)–两台或多台机器间交流与传输的内容机器数据(Machinedata)–由传感器或算法在机器上产生的数据机器学习(Machinelearning)–人工智能的一部分,指的是机器能够从它们所完成的任务中进行自我学习,通过长期的累积实现自我改进。MapReduce–是处理大规模数据的一种软件框架(Map:映射,Reduce:归纳)。大规模并行处理(MPP:MassivelyParallelProcessing)–同时使用多个处理器(或多台计算机)处理同一个计算任务。元数据(Metadata)–被称为描述数据的数据,即描述数据数据属性(数据是什么)的信息。MongoDB–一种开源的非关系型数据库(NoSQLdatabase)多维数据库(Multi-DimensionalDatabases)–用于优化数据联机分析处理(OLAP)程序,优化数据仓库的一种数据库。多值数据库(MultiValueDatabases)–是一种非关系型数据库(NoSQL),一种特殊的多维数据库:能处理3个维度的数据。主要针对非常长的字符串,能够完美地处理HTML和XML中的字串。N自然语言处理(NaturalLanguageProcessing)–是计算机科学的一个分支领域,它研究如何实现计算机与人类语言之间的交互。网络分析(Networkanalysis)–分析网络或图论中节点间的关系,即分析网络中节点间的连接和强度关系。NewSQL–一个优雅的、定义良好的数据库系统,比SQL更易学习和使用,比NoSQL更晚提出的新型数据库NoSQL–顾名思义,就是“不使用SQL”的数据库。这类数据库泛指传统关系型数据库以外的其他类型的数据库。这类数据库有更强的一致性,能处理超大规模和高并发的数据。O对象数据库(ObjectDatabases)–(也称为面象对象数据库)以对象的形式存储数据,用于面向对象编程。它不同于关系型数据库和图形数据库,大部分对象数据库都提供一种查询语言,允许使用声明式编程(declarativeprogramming)访问对象.基于对象图像分析(Object-basedImageAnalysis)–数字图像分析方法是对每一个像素的数据进行分析,而基于对象的图像分析方法则只分析相关像素的数据,这些相关像素被称为对象或图像对象。操作型数据库(OperationalDatabases)–这类数据库可以完成一个组织机构的常规操作,对商业运营非常重要,一般使用在线事务处理,允许用户访问
 三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 扫描二维码
扫描二维码







 aqiang1125
aqiang1125
本文标题:文章分享一个常见的大数据术语表
链接地址:https://www.777doc.com/doc-2338730 .html