当前位置:首页 > 商业/管理/HR > 管理学资料 > 编译原理实验七:LL(1)文法的判断
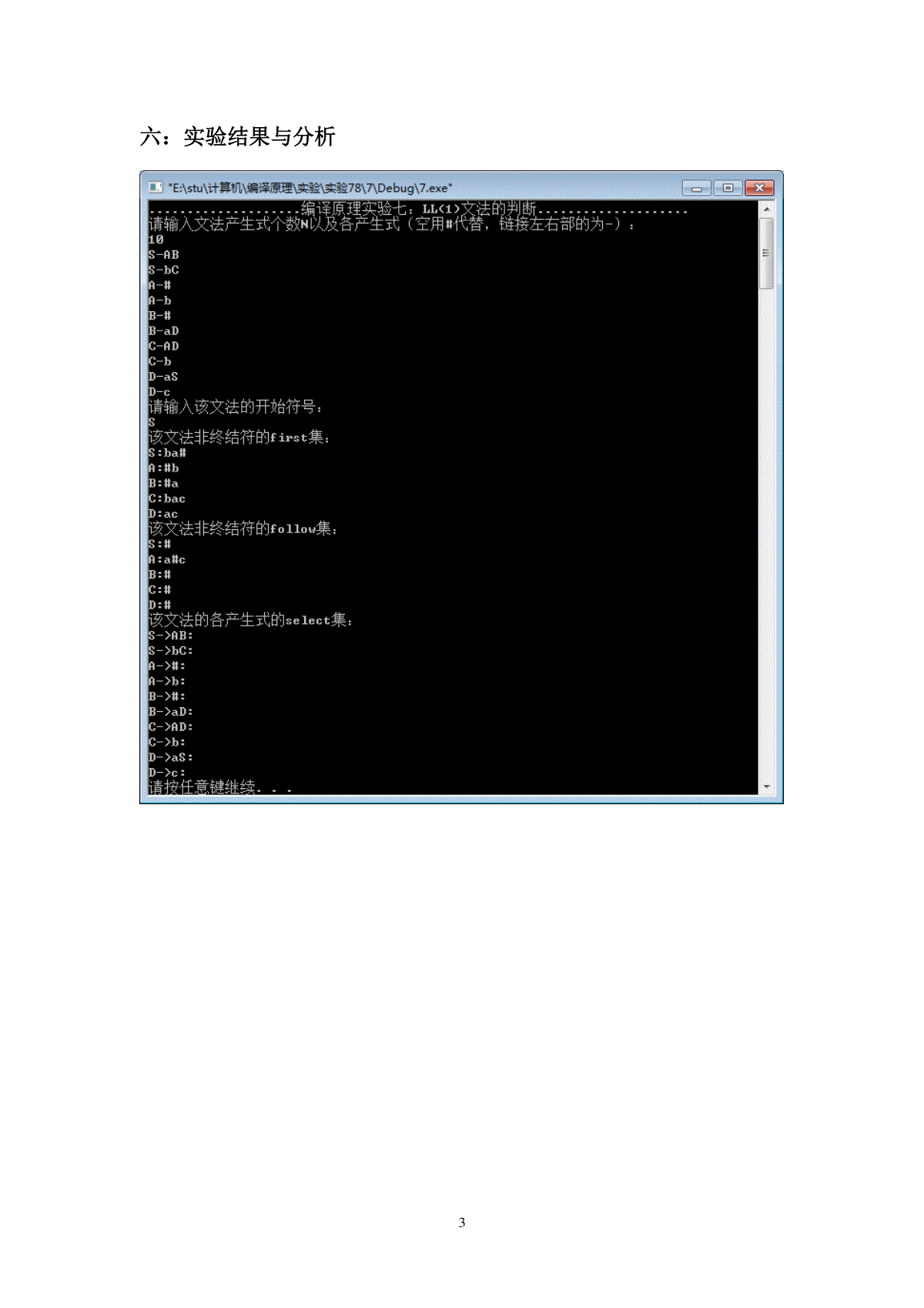
实验七:LL(1)文法的判断一:要求输入:任意的上下文无关文法。输出:判断是否为LL(1)文法二:实验目的1.掌握LL(1)的判断,掌握求first和follow集合的算法2.熟悉运用C/C++语言对求first和follow集合进行实现三:实验原理设α=x1x2…xn,FIRST(α)可按下列方法求得:令FIRST(α)=Φ,i=1;(1)若xi∈VT,则xi∈FIRST(α);(2)若xi∈VN;①若εFIRST(xi),则FIRST(xi)∈FIRST(α);②若ε∈FIRST(xi),则FIRST(xi)-{ε}∈FIRST(α);(3)i=i+1,重复(1)、(2),直到xi∈VT,(i=2,3,…,n)或xi∈VN且若εFIRST(xi)或in为止。当一个文法中存在ε产生式时,例如,存在A→ε,只有知道哪些符号可以合法地出现在非终结符A之后,才能知道是否选择A→ε产生式。这些合法地出现在非终结符A之后的符号组成的集合被称为FOLLOW集合。下面我们给出文法的FOLLOW集的定义。设文法G[S]=(VN,VT,P,S),则FOLLOW(A)={a|S…Aa…,a∈VT}。若S…A,#∈FOLLOW(A)。由定义可以看出,FOLLOW(A)是指在文法G[S]的所有句型中,紧跟在非终结符A后的终结符号的集合。FOLLOW集可按下列方法求得:(1)对于文法G[S]的开始符号S,有#∈FOLLOW(S);(2)若文法G[S]中有形如B→xAy的规则,其中x,y∈V*,则FIRST(y)-{ε}∈FOLLOW(A);(3)若文法G[S]中有形如B→xA的规则,或形如B→xAy的规则且ε∈FIRST(y),其中x,y∈V*,则FOLLOW(B)∈FOLLOW(A);2四:数据结构与算法typedefstructChomsky//定义一个产生式结构体{stringleft;//定义产生式的左部stringright;//定义产生式的右部}Chomsky;voidapart(Chomsky*p,inti)//分开产生式左右部,i代表产生式的编号stringis_empty(Chomsky*p)//判断某非终结符能否直接推出空,空用#代替stringisempty(Chomsky*p)//可以间接推出空的非终结符voidsearch(Chomsky*p,intn)//提取产生式中的非终结符voidFirst(Chomsky*p,intn,charm,intmm)//求文法中非终结符的First集voidFollow(Chomsky*p,intn,intm)//求文法的follow集stringerase(strings)//去First集及follow集中的重复字符voidselect(strings1,strings2)//求产生式的select集,s1是产生式左部,s2是产生式右部五:出错分析1:select集计算不出,关键在于能产生空的非终结符没有求出来2:单个符号的first集与一串符号的first集区别3:实验最后没能输出select集,没能判断出来是否是LL(1)文法3六:实验结果与分析4七:源代码#includeiostream#includestringusingnamespacestd;#definemax100typedefstructChomsky//定义一个产生式结构体{stringleft;//定义产生式的左部stringright;//定义产生式的右部}Chomsky;intn;//产生式总数stringstrings;//存储产生式stringnoend;//存放文法中的非终结符stringempty;//存放可以推出空的非终结符stringfirst[max];//存放非终结符的first集stringfollow[max];//存放非终结符的follow集stringselect[max];//存放产生式的select集voidapart(Chomsky*p,inti)//分开产生式左右部,i代表产生式的编号{intj;for(j=0;jstrings.length();j++)if(strings[j]=='-'){p[i].left=strings.substr(0,j);//从0开始的j长度的子串,即0~j-1p[i].right=strings.substr(j+1,strings.length()-j);//从j+1开始的后面子串}}/*stringis_empty(Chomsky*p)//判断某非终结符能否直接推出空,空用#代替{//如果可以,返回1//不可以,返回0inti;strings;for(i=0;in;i++){if(p[i].right[0]=#&&p[i].right.length()==1)//直接推出空的{empty=empty+p[i].left;5}}s=empty;returns;//s存放能直接推出空的非终结符}stringisempty(Chomsky*p)//可以间接推出空的非终结符{inti,j;strings1;for(i=0;in;i++){if(is_empty(p).find(p[i].left)=0)//若此非终结符已经存在直接推出空那里,在此无需重复计算{}else{for(j=0;j(int)p[i].right.length();j++){if(is_empty(p).find(p[i].right.[j])0){}}if(j==(int)p[i].right.length())//如果右部所有符号都在直接推出空那里,则此左部也可以推出空{s1=s1+p[i].left[0];}}}}*/voidsearch(Chomsky*p,intn)//提取产生式中的非终结符{inti,j;for(i=0;in;i++){if(!(noend.find(p[i].left[0])=0&&noend.find(p[i].left[0])noend.length()))noend=noend+p[i].left;6for(j=0;jp[i].right.length();j++){if('A'=p[i].right[j]&&p[i].right[j]='Z'){if(noend.find(p[i].right[j])=0&&noend.find(p[i].right[j])noend.length())break;elsenoend=noend+p[i].right.substr(j,1);}}}}voidFirst(Chomsky*p,intn,charm,intmm)//求文法中非终结符的First集{intlength=noend.length();stringf;inti,j,x,y;intflag=0;for(i=0;in;i++){if(m==p[i].left[0]){if('a'=p[i].right[0]&&'z'=p[i].right[0])first[mm]=first[mm]+p[i].right.substr(0,1);if(p[i].right[0]=='#')first[mm]=first[mm]+p[i].right.substr(0,1);if('A'=p[i].right[0]&&'Z'=p[i].right[0]){for(j=0;jp[i].right.length();j++){if('A'=p[i].right[j]&&p[i].right[j]='Z')flag++;}if(flag==j)//产生式的右部均为非终结符{flag=0;for(j=0;jp[i].right.length();j++){for(x=0;xn;x++)if(p[i].right[j]==p[x].left[0]&&p[x].right[0]=='#'){flag++;break;7}}if(flag==j)//产生式右部的全部非终结符均能推出空{for(j=0;jp[i].right.length();j++){for(x=0;xn;x++){if(p[i].right[j]==noend[x])break;}y=x;if(first[y]==)First(p,n,p[i].right[j],x);f=first[y];for(x=0;xf.length();x++){if(f[x]=='#'){if(x==f.length()-1)f=f.substr(0,x);elsef=f.substr(0,x)+f.substr(x+1);}}first[mm]=first[mm]+f;}first[mm]=first[mm]+#;}else{for(j=0;jp[i].right.length();j++){for(x=0;xn;x++){if(p[i].right[j]==noend[x])break;}y=x;if(first[y]==)First(p,n,p[i].right[j],x);f=first[y];for(x=0;xf.length();x++){if(f[x]=='#'){if(x==f.length()-1)f=f.substr(0,x);elsef=f.substr(0,x)+f.substr(x+1);}}8first[mm]=first[mm]+f;}}}}}}}voidFollow(Chomsky*p,intn,intm)//求文法的follow集{inti,j,x,y,k;stringfo;for(i=0;in;i++){for(j=0;jp[i].right.length();j++){if(noend[m]==p[i].right[j]){if(jp[i].right.length()-1&&'a'=p[i].right[j+1]&&p[i].right[j+1]='z')follow[m]=follow[m]+p[i].right.substr(j+1,1);if(jp[i].right.length()-1&&'A'=p[i].right[j+1]&&p[i].right[j+1]='Z'){for(y=0;ynoend.length();y++){if(noend[y]==p[i].right[j+1])break;}fo=first[y];for(x=0;xfirst[y].length();x++){if(0=first[y].find('#')&&first[y].find('#')first[y].length())fo=first[y].substr(0,first[m].find('#'))+first[y].substr(first[y].find('#')+1);}follow[m]=follow[m]+fo;for(x=0;xn;x++){if(p[i].right[j+1]==p[x].left[0]&&p[x].right[0]=='#')break;}if(x!=n)//非终结符后面的部分可以推出空{for(y=0;yn;y++){9if(p[i].left[0]==noend[y])break;}k=y;if(follow[k]==)Follow(p,n,y);follow[m]=follow[m]+follow[k];}}if(j==p[i].right.length()-1){for(y=0;yn;y++){if(p[i].left[0]==noend[y])break;}k=y;if(follow[k]==)Follow(p,n,y);follow[m]=follow[m]+follow[k];}}}}}stringerase(strings)//去First集及follow集中的重复字符{inti,j;for(i=0;is.length();i




 三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 扫描二维码
扫描二维码










 qscesz123
qscesz123
本文标题:编译原理实验七:LL(1)文法的判断
链接地址:https://www.777doc.com/doc-4254591 .html