您好,欢迎访问三七文档
当前位置:首页 > 商业/管理/HR > 信息化管理 > 证据理论的发展与应用
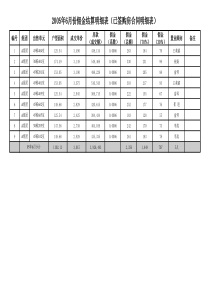
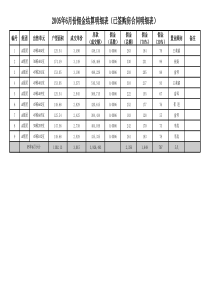
主要内容D-S证据理论证据理论的改进证据理论的应用证据理论是由Dempster首先提出,由他的学生shafer进一步发展起来的一种不精确推理理论,也称为Dempster/Shafer证据理论(D-S证据理论),属于人工智能范畴,最早应用于专家系统中,具有处理不确定信息的能力。D-S证据理论提供了一种处理多数源不确定信息推理和融合的有效方法,对各自独立的证据加以综合给出一致性结果。基于“证据”和“组合”来处理不确定性问题的数学方法具有直接表达“不确定”和“不知道”的能力,从而能够把“不确定知识”和“未知知识这两个概念有效的区分开。证据理论使用集合来表示命题确定命题的识别框架Θ。根据证据源建立一个基本信任程度的初始分配通过分析客观证据的原因和结果,可以计算出我们对于所有命题的信任程度处理的对象:一个需要判决的问题解决问题的答案抽象为一个集合表示◦Θ:所有可能答案的完备集合,集合中的任意两个元素两两互斥◦此互不相容时间的完备集合称为识别框架◦原子性:问题答案只能取Θ中的一个元素◦Θ={𝜃1,𝜃2……}由识别框架Θ的所有子集共同组成的一个集合称为Θ的幂集,记作2Θ幂集2Θ中的每一个元素X都代表属于该问题的答案的一个命题。——“问题的答案在X中”问题:我们有一个骰子,现在判断投掷后所出现的数,Θ={1,2,3,4,5,6}{2,4,6}表示“投出的骰子的点数为偶数”{l,2,3,4,5}是表示“投出的骰子的点数不是6”已经形式化,下一步开始量化D-S理论的解决方式:客观与主观的结合。作用:根据证据建立的信任程度进行初始分配设Θ是一个识别框架,识别框架上的基本概率分配,简称为BPA。在识别框架上的BPA是一个2Θ[0,1]的函数m,也称为mass函数。mass函数满足如下的条件:当A⊑Θ,并且A由单个元素组成时,m(A)表示了对单一元素构成的命题A的精确信任度;当A由Θ中的多个元素表示时,我们并不知道这部分信任度到底应该分给A中的哪些元素当A为空时,m(A)表示的是对O的各个子集进行信任分配后所剩下的部分,它表示的意思是“不知道该如何进行分配”。表示在当前环境下,对某假设集合所信任的程度,其值定义为当前集中所有子集的基本概率分配之和。在识别框架Θ上基于BPAm的信任函数定义为:Bel(A)=𝑚(𝐵)𝐵⊑𝐴虽然可以描述出对A的信任程度,但是它不能反映出我们对A的怀疑程度或者说是我们相信“A的非”为真的程度。似然函数Plausibilityfunction,又称为不可驳斥函数或上限函数。通过似然函数来描述对集合为非假的信任程度。◦在识别框架Θ上基于BPAm的似然函数定义为:Pl(A)=𝑚𝐵𝐵∩𝐴≠𝜙PI(A)≥Bel(A)◦Pl({蓝})=1一Bel({¬蓝})◦Pl({蓝,红})=l—Bel({¬蓝,¬红})Bel(A)是表示对A为真的信任程度,Pl(A)是表示对A为非假的信任程度,而且Pl(A)≥Bel(A),所以我们称Bel(A)和Pl(A)分别为对A信任度的下限和上限D-S证据理论的精髓对不同的证据进行结果融合给定了几个在同一识别框架上基于不同证据的信度函数,即基本概率分配函数,如果这几批证据不是完全相互冲突的,那么我们就可以利用Dempster合成法则计算出另一个信度函数,而这个信度函数根据规则就作为在那几批证据的联合作用下产生的联合信度函数。定义如下:对于A,上的两个mass函数m1,m2的Dempster合成规则为:12121()()()BCAmmAmBmCK其中,K为归一化常数1212()()1()()BCBCKmBmCmBmC推理中的不确定性◦假设的不确定性◦专家规则中条件的不确定性◦片面数据导致推理时的不确定性◦论断片面的不确定性决策融合的方法Dempster合成规则可以利用相互独立的不同信息源提高事件的置信程度,有效消除不同论断间的片面不确定性,提高结果的准确性。原始数据的概率分配必要的推理规则规则形成的推理网络自下而上的不确定性融合与传递信任函数和似然函数的计算由类概率函数得出的所求集合的不确定性k表示的是证据冲突度,反映了证据间的冲突情况,k越大表明证据之间的冲突越大。缺陷:◦没有明确指出其实际应用的范围◦有时候会得出不靠谱的结论1212()()1()()BCBCKmBmCmBmCm1()m2()m12()Peter0.990.000.00Paul0.010.011.00Mary0.000.990.00D-S合成规则缺陷的例子例“Zadeh悖论”:某宗“谋杀案”的三个犯罪嫌疑人组成了识别框架={Peter,Paul,Mary},目击证人(W1,W2)分别给出下表所示的BPA。【解】:首先,计算归一化常数K。12121212()()()()()()()()0.9900.010.0100.990.0001BCKmBmCmPetermPetermPaulmPaulmMarymMary根据目击证人的描述,各自都认为Paul杀人的概率只有0.01计算的结果认为Paul一定是杀人犯合成公式对解决高度冲突的证据融合来说并不适用12121({})({})({})10.010.0110.0001mmPaulmPaulmPaulK改进组合规则的修正改进证据源的修正基于组合规则的改进基于证据源的改进该方法的代表是Lefevre等人提出的统一信度函数组合方法。Yager,Lefevre等人认为,证据理论对冲突信息组合出现悖论的原因就是Dempster组合规则本身不完善所导致的,对冲突信息必须按一定规则重新分配。D-S证据理论基于Bayes公式,有完善的数学基础,其组合规则是没有问题的。这类方法的代表是Murphy,Haenni,他们认为,问题出在冲突的证据源上,需要通过修改降低冲突信息量后,再利用Dempster规则进行组合.在一个辨识框架中,假设各传感器是可靠的,其焦元为𝐴1,…𝐴𝑚,如果在一个周期内收集到n组目标识别的概率证据,每一组中,传感器对目标的基本概率赋值表示为𝑚𝑖(𝐴𝑗),且𝑚𝑖(𝐴𝑗)𝑚𝑗=1=1。基于组合规则的改进基于证据源的改进该方法的代表是Lefevre等人提出的统一信度函数组合方法。Yager,Lefevre等人认为,证据理论对冲突信息组合出现悖论的原因就是Dempster组合规则本身不完善所导致的,对冲突信息必须按一定规则重新分配。D-S证据理论基于Bayes公式,有完善的数学基础,其组合规则是没有问题的。这类方法的代表是Murphy,Haenni,他们认为,问题出在冲突的证据源上,需要通过修改降低冲突信息量后,再利用Dempster规则进行组合.在一个辨识框架中,假设各传感器是可靠的,其焦元为𝐴1,…𝐴𝑚,如果在一个周期内收集到n组目标识别的概率证据,每一组中,传感器对目标的基本概率赋值表示为𝑚𝑖(𝐴𝑗),且𝑚𝑖(𝐴𝑗)𝑚𝑗=1=1。计算一个周期内不同焦元基本概率赋值的均值和方差。𝑀𝑗=1𝑛𝑚𝑖(𝐴𝑗)𝑛𝑖=1(3)σ𝑗=1𝑛−1(𝑚𝑖𝐴𝑗−𝑀𝑗)2𝑛𝑖=1(4)统计𝑚𝑖(𝐴𝑗)中大于𝑀𝑗的个数K。若K𝑛2,则认为大于𝑀𝑗的概率证据都是可信的,不需对其进行处理。对于小于𝑀𝑗的概率证据,且满足一定条件时,认为证据源产生冲突,对其进行修正。若K𝑛2,则认为小于𝑀𝑗的概率证据都是可信的,不需对其进行处理。对于大于𝑀𝑗的概率证据,且满足一定条件时,认为证据源产生冲突,对其进行修正。修正规则:σ𝑗≤|𝑚𝑖𝐴𝑗−𝑀𝑗|≤2σ𝑗(5)𝑚𝑖𝐴𝑗−𝑀𝑗2σ𝑗(6)满足(5)时𝑚𝑖𝐴𝑗=(1+𝜆𝑖)𝑚𝑖𝐴𝑗满足(6)时𝑚𝑖𝐴𝑗=𝑀𝑗修正后的证据,利用正交和规则合成,即可识别出目标来。问题描述:假设系统辨识框架内焦元为A,B,C,待识别的目标类型为A,在一个处理周期T内,收集到了10组目标识别的概率证据,设传感器是可靠的,可认为大多数的证据是可靠的,仿真中随机一个周期内目标识别概率证据,如图所示。由图可知,一个周期内,有多组目标证据冲突。进行100次独立实验,可获得直接利用证据理论与利用改进证据理论而获得的对目标识别的对比图,如图所示。根据上图可知,如果设定门限β(设0.5β1,β的选择与目标识别环境及系统精度相关,超过门限β,则认为可以识别出目标)较高,则D-S证据理论不能很好地识别出目标,有相当一部分概率值落入0.5以下,产生了与实际不符的情况。可以根据改进证据理论对证据源进行修改,以此得到可信度较高的目标识别结果。通过算法仿真,证实了改进算法的有效性和合理性。TheEnd!谢谢大家
 三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 扫描二维码
扫描二维码







 jerry_bin
jerry_bin
本文标题:证据理论的发展与应用
链接地址:https://www.777doc.com/doc-4864535 .html