您好,欢迎访问三七文档
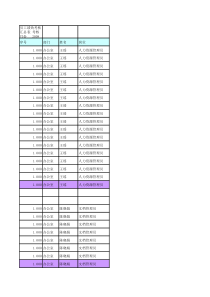
2018-2019-1学期《搜索引擎技术》实验报告1/11实验:中文分词实验小组成员:黄婷苏亮肖方定山一、实验目的:1.实验目的(1)了解并掌握基于匹配的分词方法、改进方法、分词效果的评价方法等2.实验要求(1)从互联网上查找并构建不低于10万词的词典,构建词典的存储结构;(2)选择实现一种机械分词方法(双向最大匹配、双向最小匹配、正向减字最大匹配法等),同时实现至少一种改进算法。(3)在不低于1000个文本文件(可以使用附件提供的语料),每个文件大于1000字的文档中进行中文分词测试,记录并分析所选分词算法的准确率、召回率、F-值、分词速度。二、实验方案:1.实验环境系统:win10软件平台:spyder语言:python2.算法选择(1)选择正向减字最大匹配法图1.正向减字最大匹配算法流程2018-2019-1学期《搜索引擎技术》实验报告2/11图2.切词算法流程2018-2019-1学期《搜索引擎技术》实验报告3/11(2)算法伪代码描述:3.实验步骤在网上查找语料和词典文本文件;思考并编写代码构建词典存储结构;2018-2019-1学期《搜索引擎技术》实验报告4/11编写代码将语料分割为1500个文本文件,每个文件的字数大于1000字;编写分词代码;思考并编写代码将语料标注为可计算准确率的文本;对测试集和分词结果集进行合并;对分词结果进行统计,计算准确率,召回率及F值(正确率和召回率的调和平均值);思考总结,分析结论。4.实验实施实验过程:(1)语料来源:语料来自SIGHAN的官方主页(),SIGHAN是国际计算语言学会(ACL)中文语言处理小组的简称,其英文全称为“SpecialInterestGroupforChineseLanguageProcessingoftheAssociationforComputationalLinguistics”,又可以理解为“SIG汉“或“SIG漢“。SIGHAN为我们提供了一个非商业使用(non-commercial)的免费分词语料库获取途径。我下载的是Bakeoff2005的中文语料。有86925行,2368390个词语。语料形式:“没有孩子的世界是寂寞的,没有老人的世界是寒冷的。”图3.notepad++对语料文本的统计结果(2)词典:词典用的是来自网络的有373万多个词语的词典,采用的数据结构为python的一种数据结构——集合。图4.notepad++对词典文本的统计结果2018-2019-1学期《搜索引擎技术》实验报告5/11(3)分割测试数据集:将原数据分割成1500个文本文件,每个文件的词数大于1000。图5.测试数据集分解截图图6.其中某文件的形式2018-2019-1学期《搜索引擎技术》实验报告6/11图7.notepad++对其中一个测试文本的统计结果(4)编写分词代码:采用python语言和教材上介绍的算法思路,进行编程。(5)编写代码将语料标注为可计算准确率的文本:用B代表单词的开始字,E代表结尾的字,BE代表中间的字,如果只有一个字,用E表示。例如:原数据是:“人们常说生活是一部教科书”而我将它转化为了如下格式:人们常说生活是一部教科书BEEEBEEEEBBEE(6)进行分词:使用之前编写的分词函数,载入文本,进行分词,将每个文本结果输出到txt文本。图8.分词结果文件2018-2019-1学期《搜索引擎技术》实验报告7/11图9.测试数据的形式(文本截图)图11.分词结果(文本截图)2018-2019-1学期《搜索引擎技术》实验报告8/11图12.运行时间(7)对测试集和分词结果集进行合并:将测试集和分词结果集合并是为了进行准确率,召回率等的计算。测试集和训练集都是下面的格式:人们常说生活是一部教科书BEEEBEEEEBBEE将它们合并为下面的格式,第二列为测试集的标注,第三列为训练集的结果:人们常说生活是一部教科书BEEEBEEEEBBEEBEEEBEEBEEBBEE(8)对分词结果进行统计,计算准确率P,召回率R及F值(正确率和召回率的调和平均值),设提取出的信息条数为C,提取出的正确信息条数为CR,样本中的信息条数O:计算结果如下:2018-2019-1学期《搜索引擎技术》实验报告9/11表1.第一轮分词统计结果召回率R准确率PF值B73.99%76.42%75.18%E92.12%76.41%83.53%BE40.05%74.56%52.11%平均值68.72%75.79%70.27%(9)反思:平均准确率只有75.79%,为何分词效果这么差,没有达到我们的预期效果85%,经过思考和多次尝试才发现,原来是因为词典太大了,最大匹配分词效果对词典依赖很大,不是词典越大越好,还有就是我们的词典和我们的测试数据的相关性不大,于是我们小组修改了词典,进行了第二轮测试。(10)修改词典:将词典大小裁剪,但是不能只取局部,例如前面10万词或后面10万词,于是我的做法是在373万词的词典中随机取3万词,再用之前没用完的语料制作7万词,组成10万词的词典:图13.notepad++对重新制作的词典文本的统计结果(11)再次实验:重新进行前面的步骤得到了下面的结果:表2.第二轮分词统计结果召回率R准确率PF值B95.07%95.03%95.05%E93.74%99.07%96.33%BE98.75%67.30%80.05%平均值95.85%87.13%90.48%此时分词的平均准确率提高到了87.13%,还是很不错的,说明我的反思是有道2018-2019-1学期《搜索引擎技术》实验报告10/11理的。三、实验结果及分析:1.实验结果:图14.第一轮分词测试统计结果图15.第二轮分词测试统计结果2.结果分析:2018-2019-1学期《搜索引擎技术》实验报告11/11(1)第一轮分词结果只有75.79%,而小组的预期效果或者说目标是85%以上,我们先是讨论是不是这个算法只能达到这么多,于是通过网络和询问同学的分词准确率知道,这个结果是可以继续提升的。于是,我们仔细思考了每一个环节,发现问题主要出在词典上面,因为词典中的词越多,利用做大匹配分出来的词的平均长度就越长,分得的词数也越少,错误率反而增大,而那些分法可能并不是我们想要的,而且我们的词典和我们的语料相关性很小,分词效果是依赖于这个词典的相关性的。然后我们尝试减少词典的大小,见减小到150万词,发现效果确实好了点,于是干脆只在原词典中取出3万词,再用语料库没用过的同类型的语料做一份词典,再把它们合起来,结果分词准确率一下子提高到了87.13%。(2)影响中文分词效果的因素:词典的大小,数据集的规范性,算法的优越程度如何提高中文分词的准确率:规范的数据集,合理大小的词典,好的算法。四、实验总结:本次实验期间遇到过很多问题,幸好都一一解决了,比如在合并测试集和分词结果集时,合并测试集和分词结果集时中词语的位置有错位,想了好几个办法才解决,其实在实验之前多思考思考是可以避免这种情况的。本次实验中,分词是实验的重点,但难点不在分词上面,而在数据的处理和计算准确率。我们还应多练习,多运用,多思考才能真正提升自己的能力。五、参考文献:[1]百度文库“搜索引擎检索性能评价实验报告”[2]数据集:SIGHANbakeoff2005数据集中的简体中文部分[3]链接:[4]文献:1.知乎:如何解释召回率与准确率?[5]链接:[6]《搜索引擎--原理、技术与系统》[7]百度文库“中文分词实验”
 三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 扫描二维码
扫描二维码









 xutingting01
xutingting01
本文标题:中文分词实验报告
链接地址:https://www.777doc.com/doc-5277624 .html