您好,欢迎访问三七文档
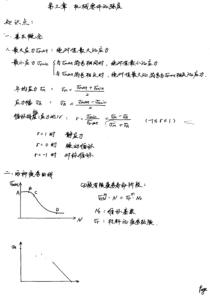
第六章质量管理统计方法2质量特性数据的收集与整理本章重点1随机变量及其概率分布2统计分析方法33第一节质量特性数据的收集与整理一、质量特性数据的类型二、数据的收集与分析三、数据的整理与显示四、数据特征描述4一、质量特性数据的类型(一)定性数据顾名思义,定性数据只用来描述质量的定性特征,比如依据一定的标准判断产品质量为“合格”或者是“不合格”,(二)定量数据1.计量值数据计量值数据是指在某个区间上的可能取值具有连续性的数据,即在该区间内可以取无穷多个实数值。常见的有质量、面积、长度、体积,等等。2.计数值数据计数值数据是指在有限的区间内只能取有限个整数值的数据,其取值只能是大于或等于零的整数,否则将失去其实际意义。如铸件内的气孔个数、一批产品中不合格产品的件数,等等。5二、数据的收集与分析(一)总体、个体及样本类别定义总体需要研究考察的对象的全体即被称为总体,总体是由个体组成的。个体总体中包含的个体数量称为总体容量,用大写字母N表示样本被抽取出来的这一部分个体就组成了一个样本,而样本中所包含的个体数目称为样本容量,用小写字母n表示。6二、数据的收集与分析(二)数据初步分析已收集的数据作为后续数据处理及统计分析的基础,有必要对其进行初步的分析检验。包括分析数据的来源及真实性,以便进一步确认数据是否准确;审查数据的精确程度和完整性,是否符合必要的使用要求;由专业人士协助设置疑问框,检验是否存在有矛盾或异常数据,并予以剔除,等等。7三、数据的整理与显示(一)数据排序数据排序就是将数据按照数值大小、类别等级等规则进行重新排列。特别是当数据类型是定量数据,且数据的数量较为庞大时,通过数据排列更有助于突出一些明显的特征和趋势,并且可以为后面的分组、众数、中位数等统计计算提供便利。8三、数据的整理与显示(二)数据分组1.数据分组的概念和意义数据分组——是根据统计分析的需要,将数据总体按照一定的分组标志,分成若干个组成部分。对于定性数据,就是按照其不同的属性分为若干组;对于定量数据,则是依据不同的数值或数值范围将数据划分为若干组。分组应使组内差距尽可能小,而组间差异应较为明显。分组有助于显现数据的类别差异、结构情况或数量上的层次性,也有助于简化后续的一些统计计算,是在整理数据时被广泛采用的一种普遍方法。9三、数据的整理与显示•2.定性数据分组方法•对于定性数据,可以根据统计分析的需要按照数据的类别或等级对数据进行分组。•【例6-1】抽取某种产品100个,通过检验,有特等品20个,一等品49个,二等品28个,残次品3个。•分组方案一:显然,可以将该数据按照表述中的等级分为四组,显示出具体的产品等级情况。•分组方案二:如果只考虑产品的合格率,也可以采用另一种分组方案,将其直接分为两组,即合格产品97个、残次品3个。•这两种分组方案各有其针对性,为更直观地显示其类别结构情况,可以采用饼图将这两种分组方案分别表示出来,如图6-1、图6-2所示。特等品20%一等品49%二等品28%残次品3%残次品3%合格品97%10三、数据的整理与显示3.定量数据分组方法对定量数据进行分组的关键是确定组数、组间距及划分各组界限。(1)组数。(2)组距。组距可以由组数得到,组距用字母h表示:(3)组限。组限就是各个相邻组之间的具体分界值,也就是每一个组的两个端值。(4)组中值。顾名思义,组中值就是一个分组的上限和下限的中间值,即:组中值(5)累计频数。2lglg1nK+=RhK2UL11三、数据的整理与显示【例6-2】抽取同一批生产的60个某种袋装食品,测量其质量的数值(单位:克),经过审核后进行了排序,数据如下:195.6196.2196.3196.6196.7197.0197.2197.5197.7197.9198.1198.1198.2198.6198.7198.7198.9199.0199.2199.3199.3199.4199.6199.6199.8199.9199.9200.0200.0200.1200.2200.2200.3200.5200.5200.6200.8200.8200.9201.0201.1201.1201.4201.5201.7201.7202.0202.1202.5202.6202.6203.1203.3203.7203.8204.1204.2204.7205.2205.5应用斯特杰斯公式即可得到分组数的一个参考值:所以大致可以将这些数据分为七组左右。lg6016.9lg2K12三、数据的整理与显示(1)组数所以大致可以将这些数据分为七组左右(2)组距在上述的60个数据中,全距R就等于最大值205.5与最小值195.6的差,即R=9.9(3)组限[195.5,197.0),[197.0,198.5),[198.5,200.0),[200.0,201.5),[201.5,203.0),[203.0,204.5),[204.5,206.0)。(4)组中值(5)累计频数lg6016.9lg2K9.91.4356.9h13三、数据的整理与显示分组编号组限组中值频数1[195.5,197.0)196.2552[197.0,198.5)197.7583[198.5,200.0)199.25144[200.0,201.5)200.75175[201.5,203.0)202.2576[203.0,204.5)203.7567[204.5,206.0)205.25314三、数据的整理与显示分组组限频数频率(%)累计频数累计频率(%)向上向下向上向下1[195.5,197.0)58.35608.3100.02[197.0,198.5)813.3135521.791.73[198.5,200.0)1423.3274745.078.44[200.0,201.5)1728.3443373.355.05[201.5,203.0)711.7511685.026.76[203.0,204.5)610.057995.015.07[204.5,206.0)35.0603100.05.015四、数据特征描述1.算术平均数2.几何平均数3.众数(1)众数的定义(2)分组定量数据的众数(3)众数的特点。4.中位数(1)中位数的定义。(2)未分组数据的中位数。(3)分组数据的中位数nxnxxxxn=+++=211231nnnniiGxxxxx112oMLd121222ennnxnxxnM当为奇数)(当为偶数)(2=f中位数的位置16四、数据特征描述5.算术平均数、众数及中位数的关系算术平均数、众数及中位数三者之间的关系,与数据的分布状态直接相关。当数据的分布状态基本对称时,算术平均数、众数和中位数三者的数值非常接近甚至几乎相同,如图6-5所示。17四、数据特征描述(二)离散趋势1.平均差2.方差与标准差(2)总体方差与标准差未分组总体数据的方差已分组总体数据的方差:未分组总体数据的标准差:已分组总体数据的标准差..xxADn221NiiXXN()2211KiiiKiiXXff()21NiiXXN()211KiiiKiiXXff()18四、数据特征描述(二)离散趋势(3)样本方差与标准差未分组总体数据的方差已分组总体数据的方差未分组总体数据的标准差已分组总体数据的标准差221NiiXXN()2211KiiiKiiXXff()21NiiXXN()211KiiiKiiXXff()19四、数据特征描述(3)样本方差与标准差未分组总体数据的方差已分组总体数据的方差:未分组总体数据的标准差:已分组总体数据的标准差2211niixxSn()=22111kiiikiixxfSf()=211nixxSn()=2111kiikiixxfSf()=20四、数据特征描述3.离散系数(1)离散系数——也称变异系数,就满足了这种要求,它消除了数据绝对量水平高低以及计量单位不同对考察离散程度相对水平的影响。离散系数是采用离差值与平均数的比值,通常用百分数表示。(2)标准差系数及公式100%100%SSVVXx或21四、数据特征描述4.异众比率5.四分位差QD=Q3-Q11mmrfffffV22第二节随机变量及其概率分布一、随机变量二、随机变量的概率分布23一、随机变量(一)随机变量的含义和表示随机变量——就是用来表示随机现象结果的变量,所以其取值带有随机性,即具体取何值在事先无法确定。作为表征产品性能的指标,产品的质量特性数据普遍都具有随机性,所以每个质量特性本身也就是一个随机变量。随机变量通常用大写字母X、Y、Z等表示,而用相应的小写字母x、y、z等表示它们的取值。24一、随机变量(二)随机变量的类型根据随机变量取值类型的不同,随机变量可以分为两种:离散型随机变量和连续型随机变量。离散型随机变量,是只能取有限个或可数个数值的随机变量。例如前面例子中的不合格品数X、铸件内的气孔数Y,就都是离散型随机变量。连续型随机变量,是指可以取一个或多个区间中任意实数值的随机变量。前面例子中电冰箱的使用寿命Z,便是连续型随机变量,再如上一节例6-2中的袋装食品质量,事实上也是属于连续型随机变量。25二、随机变量的概率分布(一)随机变量概率分布的含义随机变量的取值具有统计规律性,也就是说对于一个随机变量,完全可以确定其取某个值或在某个区间内取值的概率。所以,既需要了解随机变量所有可能的取值,还需要知道它取这些值的可能性具体是多少。26二、随机变量的概率分布(二)离散型随机变量的概率分布设一个离散型随机变量X的所有可能取值为xi(i=1,2,…,n),并且与其相对应的概率P(X=xi)=pi都是已知的,那么也就确定了该随机变量的概率分布。也可以用表格的形式更直观地表示出来:XX1X2X3XNP27二、随机变量的概率分布•【例6-4】某种机械产品的故障维修时间X(以整小时记数),是一个随机变量,且其概率分布为:•表6-6维修时间的概率分布•由此可知,当一台该种产品出现故障时,可以在n个小时内将其维修好的概率即为:X(小时)12…n…P……121412n28二、随机变量的概率分布(三)连续型随机变量的概率分布1.概率密度函数类似于离散型随机变量概率分布的两个性质,连续型随机变量X的概率密度函数也需要满足下面两个条件:01()()fxfxdx29二、随机变量的概率分布2.概率分布函数通常,对于一个具体的取值a,概率分布函数F(a)表示的概率为:因此,可以用概率分布函数F(x),来表示随机变量X在区间(a,b)或[a,b]上取值的概率:()()aFafxdx()()()()baPaxbfxdxFbFa30二、随机变量的概率分布由此显而易见,连续型随机变量在一个具体取值点上的概率为0,即它是一条面积等于0的线段。所以,对于连续型随机变量X而言,在区间(a,b)上或在区间[a,b]上取值的概率是相同的。Oxab31二、随机变量的概率分布(四)随机变量的数学特征随机变量有一些重要的数学特征,以表征其分布的集中位置、离散程度等具体信息,主要包括随机变量的数学期望、方差与标准差。1.随机变量的数学期望1()niiiEXxp()EXxfxdx32二、随机变量的概率分布随机变量的数学期望,具有如下一些基本的运算性质:(1)常量c的数学期望,等于该常量本身:(2)随机变量与一个常量之和的数学期望,等于随机变量的数学期望与这个常量的和:()Ecc()()EXcEXc33二、随机变量的概率分布(3)随机变量与一个常量乘积的数学期望,等于随机变量的数学期望与这个常量的积:(4)两个随机变量的和或者差的数学期望,等于它们各自数学期望的和或差:(5)两个独立随机变量乘积的数学期望,等于这两个随机变量数学期望的乘积:()()EcXcEX
 三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 扫描二维码
扫描二维码







 kele007
kele007
本文标题:质量管理统计方法
链接地址:https://www.777doc.com/doc-6172334 .html