您好,欢迎访问三七文档
当前位置:首页 > 商业/管理/HR > 咨询培训 > 常用实验设计类型和方法
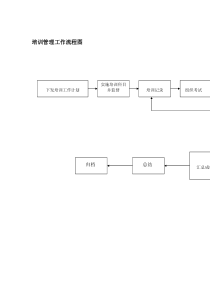
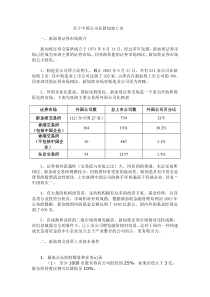
常用实验设计类型与分析方法•研究设计以最少的人力、物力和时间,最大限度地获得丰富、准确、可靠的信息与结论。研究设计:专业设计与统计设计专业设计:选题,建立假说、确定研究对象和技术方法等。统计设计:围绕专业设计,确定统计设计类型、样本大小、分组方法、统计分析指标及统计分析方法等,根据处理因素、控制因素和实验单位的特征,实验设计方法又有许多不同的类型。实验设计是关于数据采集、统计方法应用和得出结论的关键步骤。如实验设计出现错误,不论用什么统计方法进行数据处理也无法得到正确的结论。因此,在医学科研中只要条件允许,应尽量在良好的实验设计的基础上采集数据。医学研究中常用的实验设计类型和方法有以下十几种。一、基本概念总体与样本(注意:样本要有代表性)总体(population)是指根据研究目的所确定的所有同质的观察个体的集合(全体),样本(sample)是指来自总体的部分观察个体。处理因素与非处理因素、水平处理因素(实验因素、研究因素,简称因素),是指在实验中根据研究目的而施加给实验对象的各种人为设置的干预措施。非处理因素是指实验中非人为干预的因素,如实验动物的雌雄、体重,受试者的性别、年龄、病情,实验时的季节、气温等。●应特别注意那些对实验结果有影响的非处理因素。●平衡处理组间的非处理因素是实验设计的重要内容之一。各因素所处的不同状态称为水平(level),一个处理因素往往可分为若干个水平,而水平数的多少是确定实验组数的依据。实验单位与观察单位实验单位(experimentalunit)是指接受处理的基本单位。观察单位(observationalunit)是指根据研究需要确定的采集数据的基本单位。一个实验单位可以有多个观察单位。注意:处理间的差异应在实验单位中比较。单独效应、主效应与交互作用单独效应(simpleeffect)是指其他因素的水平固定时,同一因素不同水平间的平均差别。主效应(maineffect)指某一因素各水平间的平均差别。当某因素的各个单独效应随另一因素水平的变化而变化,且相互间的差别超出随机波动范围时,则称这两个因素间存在交互作用(interaction)。注意:在统计分析时,若存在交互作用,须逐一分析各因素的单独效应。反之,如果不存在交互作用,则两因素的作用相互独立,分析某一因素的作用只需考察该因素的主效应。检验效能检验效能(powerofatest),又称把握度(power),记作1-β,指当两个(或几个)总体存在差异时,经假设检验能够发现该差异的可能性大小。●与、、、N有关。●假设检验为“阴性”结论(P0.05)时,不能简单地下“处理无效”的结论,而应该检查一下是否是检验效能不足。1图8.3.1样本大小与检验效能、显著性水平的关系(α=0.05,α=0.01,δ=0.5cm,σ=2cm)0.00.20.40.60.81.0020040060080010001200样本总量(N)检验效能α=0.05α=0.01(1-β)•实验设计的基本原则实验设计的作用主要是减小误差、提高实验的效率。因此,从统计方面说,根据误差的来源,在设计时必需遵守三个基本统计学原则,即对照(control)原则、随机化(randomization)原则及重复(replication)原则。重复和对照也是观察性研究必须遵循的原则,唯有随机化分组是实验性研究的显著特征。•随机化分组步骤1.将N个实验单位从1到N编号。如动物可按体重大小、患者可按就诊顺序。2.取随机数字,随机数字的位数一般要求与N相同。3.将读取的N个随机数字按分组要求划分区段。即:根据随机数所在区间决定实验单位应接受的处理。例如,按二位随机数分两组时,可规定随机数00~49为第1组,50~99为第2组;分三组时,01~33为第1组,34~66为第2组,67~99为第3组,余类推。同理,如按2:1的比例分两组,则01-66为第1组,67-99为第2组。另外,分两组时,亦可按随机数的奇、偶决定组别。也可将读取的N个随机数从小至大排顺序,得到N个序号R,再根据R进行分组,即按R所在区间决定实验单位应接受的处理。4.有必要时可对分组结果进行组别调整。假如共有n例,需要从中抽取1例,则读取一个位数与n相等的随机数,除以n后将得到的余数作为所抽实验单位的序号(规定:如整除则余数为n)。•常用随机化分组方法简单随机化分段随机化分层随机化简单随机化:设A和B分别代表处理组和对照组。分组步骤是先将受试对象(如动物、患者)按体重大小(或就诊顺序)编号,然后给每个受试者一位随机数,并规定0-4者分配到A组,5-9者分配到B组。例将一批受试对象随机分为两组。受试者编号123456789…随机数405728193…分配组别AABBABABA…对两组以上时,如分三组时可规定随机数1-3为A组,4-6者为B组,7-9者为C组,随机数为0时略去。同理,分四组可规定随机数1-2者为A组,3-4者为B组,5-6者为C组,7-8者为D组,随机数为0和9时略去。简单随机化分组方法不能保证分组后各组例数相等,但当受试对象总例数较多时(如N200),两组例数相差悬殊的概率较小。尽管如此,在正式试验前最好先检查一下随机分配表(即分组过程及结果表)中各组例数是否大致相当。如果发现相差悬殊(如100例分两组,A组15例,B组85例),可以重新制定随机化分配表。有些研究希望各组例数相同。当各组例数不相等时,可从例数较多的组中随机抽取一部分受试者补充到例数较少的组,使各组例数相等。例若将20个实验单位随机等分为四组。对2位随机数字规定,00~24为甲组,25~49为乙组,50~74为丙组,75~99为丁组,分组结果如下:(3\4\6)编号12345678910随机数47503629023193712347组别乙丙乙乙甲乙丁丙甲乙调整丁丁编号11121314151617181920随机数23460426696125549018组别甲乙甲乙丙丙乙丙丁甲调整丁甲组5例,乙组8例,丙组5例,丁组2例,需要从乙组中再抽出3例放入丁组。按组别调整步骤,读一随机数3,除以8(乙组例数)后,余数为3,则将乙组中第3例(第4号)放入丁组。同理,再读一随机数4,除以7(乙组现有7例),余数为4,再将乙组中第4例(第10号)放入丁组。最后再读一随机数6,除以6(乙组现有6例),余数为6,将乙组第6例(第17号)放入丁组。•常用单因素实验设计类型和方法(一)完全随机设计(completelyrandomdesign)优点:简单易行,统计分析简单,即使各处理组例数不等,也不影响实验结果的统计分析,常用t检验、方差分析或Kruskal-Wallis秩和检验进行统计分析。缺点:试验效率不高,只能分析单个因素,且要求实验单位有较好的同质性,如果同质性不好,则需要观察较多的样本量。随机分组步骤:(N=16,G=4)实验单位编号:12345678随机数:7663102185906308R1412351516132处理T4T3T1T2T4T4T4T1实验单位编号:910111213141516随机数:2754310313612437R7108141169处理T2T3T2T1T1T3T2T315112121071481613639514干预随机数大小序号(R)实验单位编号T1T2T3T4实验单位属性3,8,12,134,9,11,152,10,14,161,5,6,7分组的均衡性比较1174T1222210T3333112T344158T25587T2663514T477179T3882211T39932T1101053T1111175T2121221T113133113T4141486T215153615T416164616T4NoRANrRANgroupTransform--------RandomNumberSeed--------Setseedto2000000(默认)--------Transform--------Compute…--------TargetVariable填入ran(变量名)--------NumericExpression:填入UNIFORM(50)0~X--------OKTransform--------RankCases…----Variable填入ran--------OK(自动产生序号rran,完成分组,group)统计分析数据表:16行2列(dependent+factor)反应变量处理因素反应变量处理因素(瘤重g,y)(药物浓度,T)yT3.610.434.511.734.212.334.414.533.023.342.321.242.420.041.122.74One-WayANOVA(二)随机单位组设计(randomizedblockdesign)亦称配伍组设计或随机区组设计,实际上是配对设计(将多方面条件近似的受试对象配成对子)的扩大,也是对完全随机设计的改进(即加强了均衡可比性)。而这种设计是将多方面条件相同或相近的受试对象组成单位组(block,亦称区组或配伍组),适用于三组或三组以上的实验。每个随机单位组的受试对象数目取决于处理的数目。如果一个实验安排了四种不同处理,那么每个单位组就应有四个受试对象。有多少个单位组,则每种处理就可以分配到多少个受试对象。优点:条件一致或相近的受试对象组成同一单位组(非随机),并随机分配于各处理组中,使处理组间的可比性更强,能改善组间生物学特点的均衡性,既缩小了误差,又可分析出处理组间与配伍组间两因素的影响,实验效率较高。缺点:分组较繁,要求单位组内实验单位数与处理数相同,有时实际应用有一定困难。实验结果中若有缺失,统计分析较麻烦。结果分析:方差分析、Friedman秩和检验1.实验设计方法(1)将实验单位按照其自然属性或某个非处理因素形成n个单位组,每个单位组含有k个实验单位。(2)在每个单位组内随机分配k种处理。k=2时为配对设计。实验单位的自然属性:动物的窝别(同窝的k只动物)、受试者的体重(体重相近的k个受试者)等。要选择对试验结果影响较大的非处理因素形成单位组,如研究小鼠吃不同饲料后的体重增长情况,可将体重相近的小鼠配成单位组,在临床试验中可将病情基本相同的患者配成单位组。遵循“单位组间差别越大越好,单位组内差别越小越好”的原则。随机单位组设计(N=12,b=3,k=4)141322134243单位组干预(随机数大小序号,R)111712212233313144411525528166235477217288222399332101035311113741212321NoblockRANrRANTransform--------RandomNumberSeed--------Setseedto2000000(默认)--------Transform--------Compute…--------TargetVariable填入ran(变量名)--------NumericExpression:填入UNIFORM(50)0~X--------OKTransform--------RankCases…----Variable填入ranBy填入block--------OK(自动按block产生序号rran,完成分组)•方差分析选择单位组的原则是“单位组间差别越大越好、单位组内的差别越小越好。”如果单位组选择不当使单位组间的差别很小,由于单位组占用了n-1个自由度,反而增加了误差均方。如表a的试验结果,按随机单位组方差分析(表b),误差均方为8.18,若将单位组DF和SS与误差合并(按完全随机分组方差分析),误差均方为6.61。表a甘蓝叶核黄素浓度(μg/g)测定次数甲乙丙丁单位组小计第一批第二批第三批27.223.224.824.624.222.239.543.145.238.639.533.0129.9130.0125.2处理小计75.271.0127.8111.1385.1表b甘蓝叶核黄素浓
 三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 扫描二维码
扫描二维码








 sc69256
sc69256
本文标题:常用实验设计类型和方法
链接地址:https://www.777doc.com/doc-6959776 .html