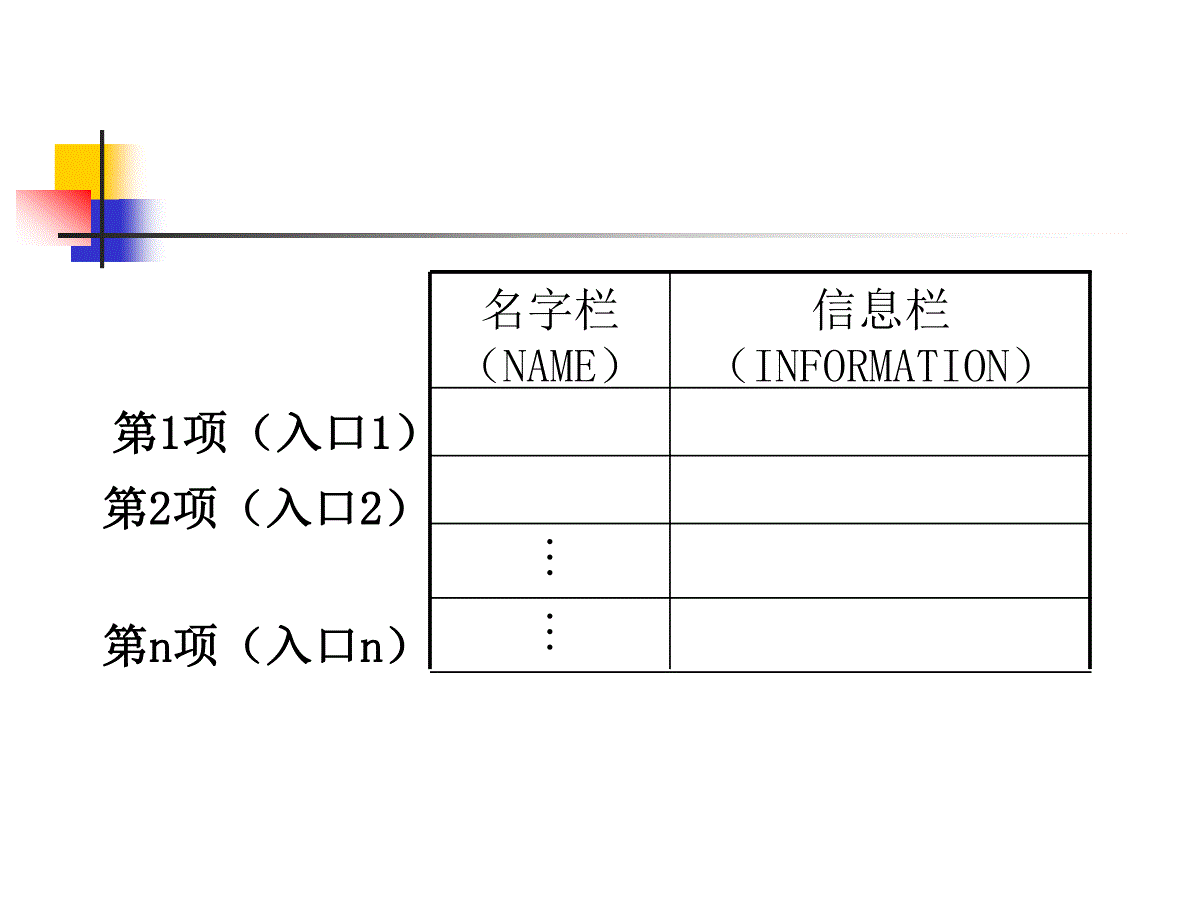
第6章符号表编译过程中编译程序需要不断汇集和反复查证出现在源程序中各种名字的属性和特征等有关信息。这些信息通常记录在一张或几张符号表中。符号表的每一项包含两部分,一部分是名字(标识符),另一部分是此名字的有关信息。每个名字的有关信息一般指种属(如简单变量、数组、过程等)、类型(如整、实、布尔等)等等。这些信息将使用于语义检查、产生中间代码以及最终生成目标代码等不同阶段。编译过程中,每当扫描器识别出一个单词后,编译程序就查阅符号表,看它是否已在其中。如果它是一个新名就将它填进表里。它的有关信息将在词法分析和语法--语义分析过程中陆续填入符号表中所登记的信息在编译的不同阶段都要用到。在语义分析中,符号表所登记的内容将用于语义检查(如检查一个名字的使用和原先的说明是否相一致)和产生中间代码。在目标代码生成阶段,当对符号名进行地址分配时,符号表是地址分配的依据。对于一个多遍扫描的编译程序,不同遍所用的符号表也往往各有不同。因为每遍所关心的信息各有差异。教学内容符号表的组织分程序结构语言符号表的建立非分程序结构语言符号表的建立1.符号表的组织和使用概括地说,一张符号表的每一项(或称入口)包含两大栏(或称区段,字域),即名字栏和信息栏。表格的形式是:信息栏(INFORMATION)名字栏(NAME)第1项(入口1)第2项(入口2)第n项(入口n)信息栏通常包含许多子栏和标志位,用来记录相应名字的种种不同属性。由于查填符号表一般都是通过匹配名字来实现的。名字栏也称主栏。主栏的内容称为关键字(keyword)。虽然原则上说,使用一张统一的符号表也就够了,但是,许多编译程序按名字的不同种属分别使用许多符号表,如常数表、变量名表、过程名表等等。这是因为,不同种属名字的相应信息往往不同,并且信息栏的长度也各有差异的缘故。因而,按不同种属建立不同的符号表在处理上常常是比较方便的。对于编译程序的符号表来说,它所涉及的基本操作大致可归纳为五类:1、对给定名字,确定此名是否在其中;2、填入新名;3、对给定名字,访问它的有关信息;4、对给定名字,填写或更新它的某些信息;5、删除一个或一组无用的项。符号表最简单的组织方式是让各项各栏所占的存储单元的长度都是固定的。这种项栏长度固定的表格易于组织、填写和查找。对于这种表格,每一栏的内容可直接填写在有关的区段里。例如,有些语言规定标识符的长度不得超过8个字符,于是,我们就可以用两个机器字作为主栏(假定每个机器字可容四个字符)每个名字直接填写在主栏中。若标识长度不到8个字符,则用空白符补足。这种直接填写式的表格形式如下:…WEIGHT…SAMPLEINFORMATIONNAME符号表有许多语言对标识符的长度几乎不加限制,或者说,标识符的长度范围甚宽。譬如说,最长可容许由100个字符组成的名字。在这种情况下,如果每项都用25个字作主栏,则势必会大量浪费存储空间。因此,最好用一个独立的字符串数组,把所有标识符都存放在其中。在符号表的主栏放一个指示器和一个整数。指示器指出标识符在字符串数组中的位置;整数代表此标识符的长度。这样,符号表的结构就如下图所示:符号表THGIEWELPMASPOOL.6INFORMATIONNAME字符串数组符号表作为一个多元组,表中元组之间的排列组织是构造符号表的重要成分。在编译程序的整个工作过程中,符号表被频繁也用来建立表项,找查表项,填充和引用表项的属性。因此表项的排列组织对该系统运行的效率起着十分重要的作用。在“数据结构”技巧的讨论中提供了很多有关多元组表格的组织方法和它们有关的操作算法。而在编译程序中,符号表项的组织传统上采用三种构造方法。即线性法,二分法及散列法。符号表项的排列与查找线性组织这种方法规定符号表项中按它的符号被扫描到的先后顺序建立。例如有一程序中出现符号的情况如下:…………………a…………………b………a…………………d………c…………………b…………符号属性h→abdcP→语言中任何符号都是由一个或几个字符拼写而成的,在机器中是用字符代码(通常是ASCII或EBCDIC代码)表达。因每一个符号在机器内都是由这种字符代码串来表示。排序组织的符号表,就是在符号表中的表项按其符号的字符代码串(可以看成一个整数值)的值的大小从大到小(或从小到大)排列的。排序表按排序组织得到的符号表将如图:符号属性h→abcdP→对于表格处理来说,根本问题在于如何保证查表与填表两方面的工作都能高效地进行。对于线性表来说,填表快,查表慢。而对于二分法而言,则填表慢,查表快。杂凑法是一种争取查表、填表两方面都能高速进行的统一技术。散列组织这种办法是:假定有一个足够大的区域,这个区域是以填写一张含N项的符号表。我们希望构造一个地址函数H,对任何名字SYM,H(SYM)取值于0至N—1之间。这就是说,不论对SYM查表或填表,我们都希望能从H(SYM)获得它的表中的位置。我们用无符号整数作为项名,令N=17,把H(SYM)定义为SYM÷N的余数。那么,名字ˋ09ˊ将被置于表中的第9项,ˋ34ˊ将被置于表中的第0项,ˋ171ˊ将被置于表中的第1项。第一,函数的计算要简单、高效;第二,函数值能比较均匀地分布在0至N--1之间。散列组织对于地址函数H有两点要求:例如,若取N为质数,把H(SYM)定义为SYM÷N的余数就是一个相当理想的函数。构造函数H的办法很多,通常是将符号名的编码杂凑成0--N--1间的某一个值。因此,地址函数H也常常称为杂凑函数。杂凑函数的选择往往和具体计算机系统的字符编码有关。如果是对数目确定的已知符号名,我们可以通过试验,精挑细选,构造出一个一一对应函数。如果杂凑函数是用来产生用户的标识符表的,由于用户使用标识是随机的,而且标识符的个数也是无限的(虽然在一个源程序中所有的标识符的全体是有限的),因此,企图构造一一对应的函数当然是徒劳的。在这种情况下,除了希望函数值的分布比较均匀之外,我们还应没法解决“地址冲突”的问题。以N=17,H(SYM)为SYM÷N的余数为例,由于H(ˋ05ˊ)=H(ˋ22ˊ)=5,若表格的第5项已为ˋ05ˊ所占,那么,后来的ˋ22ˊ应放在哪里呢?解决地址冲突的办法很多。我们这里只介绍一种最简单的线性查填解决法。这种办法的填表过程是:对任何名字SYM,令H(SYM)=h,若第h项为空,则直接把SYM填入。若h项不空,则看第h+1(modN)项,为空则填入,否则继续考察第h+2(modN)项,如此反复,直至或者把SYM填为第h+i(modN)项;或者到达h+N=h(modN)(说明表区已满),无法再填入。查表过程与此相仿:令H(SYM)=h,若第h项为空,则说明SYM不在表中,若SYM等于第h项的名字,则宣布查找成功,且SYM的项数为h。否则,继续考察第h+1(modN)项。如此反复,直至或者在第h+i(modN)项中找到SYM;或者h+i(modN)项为空,说明SYM不在表中;或者到达h+N=h(modN),同样说明SYM不在表中。




 三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 扫描二维码
扫描二维码









 climafly
climafly
本文标题:第6章符号表
链接地址:https://www.777doc.com/doc-3904288 .html