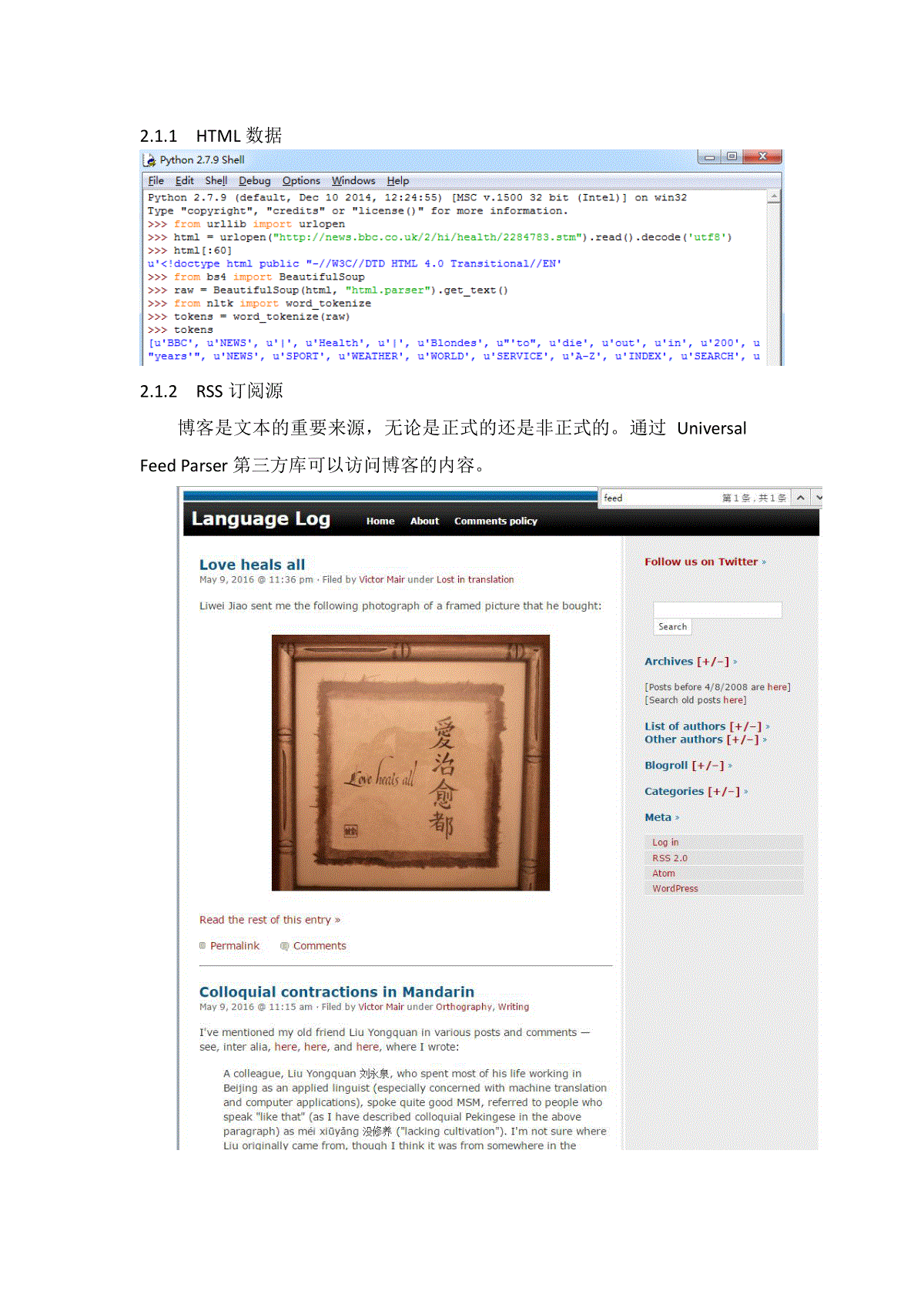
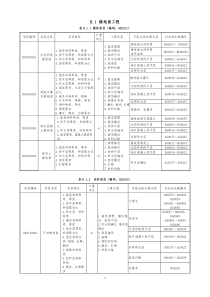
1、文本挖掘主要内容存储信息使用最多的是文本,文本挖掘被认为比数据挖掘具有更高的商业潜力,当数据挖掘的对象完全由文本这种数据类型组成时,这个过程就称为文本数据挖掘。1.1文本分类及情感分析文本分类指按照预先定义的主题类别,为文档集合中的每个文档确定一个类别。需要训练集训练分类器,然后应用于测试集。主要有朴素贝叶斯分类、决策树等。情感分析是近年来国内外的研究热点,是基于计算机整理、分析相关评价信息,对带有感情色彩的的主观性文本进行分析、处理和归纳。情感分析包括情感分类、观点抽取、观点问答等。1.2文本聚类聚类与分类的不同之处在于,聚类没有预先定义好的一部分文档的类别,它的目标是将文档集合分成若干个簇,要求同一簇内文档内容的相似度尽可能的大,而不同簇之间的相似度尽可能的小。1.3文本结构分析其目的是为了更好地理解文本的主题思想,了解文本表达的内容以及采用的方式,最终结果是建立文本的逻辑结构,即文本结构树,根结点是文本主题,依次为层次和段落。1.4Web文本数据挖掘在Web迅猛发展的同时,不能忽视“信息爆炸”的问题,即信息极大丰富而知识相对匮乏。据估计,Web已经发展成为拥有3亿个页面的分布式信息空间,而且这个数字仍以每4-6个月翻1倍的速度增加,在这些大量、异质的Web信息资源中,蕴含着具有巨大潜在价值的知识。Web文本挖掘可以构建社交复杂网络、用户标签、网络舆情分析等2、自然语言处理流程2.1获取原始文本文本最重要的来源无疑是网络。我们要把网络中的文本获取形成一个文本数据库(数据集)。利用一个爬虫抓取到网络中的信息。爬取的策略有广度和深度爬取;根据用户的需求,爬虫可以有主题爬虫和通用爬虫之分。2.1.1HTML数据2.1.2RSS订阅源博客是文本的重要来源,无论是正式的还是非正式的。通过UniversalFeedParser第三方库可以访问博客的内容。2.1.3本地文件2.2对文本进行预处理2.1.1文本编码格式1.decodeearly;2.unicodeeverywhere;3.encodelater。具体见Python2.X编码问题汇总2.1.2文本模式匹配Python自带的一些方法就能完成一部分字符检测工作,例如endswith(‘ly’)可以找到”ly”结尾的词。然而,正则表达式提出了一个更强大、更灵活的字符匹配模式。2.1.3规范化文本(1)通过lower()将文本规范化为小写,即可忽略”The”和”the”的区别(2)词干提取:nltk提供Porter和Lancaster词干提取器,按照内嵌的规则剥离词缀。如下例,Porter能将lying正确地映射为lie,而Lancaster就没处理好。(3)词性归并:注重词性的统一,而不考虑词缀。如下例,将”women”转换为”woman”。(4)非标准词的规范:包括数字,缩写,日期等从非标准格式映射为标准格式。2.3分词经过上面的步骤,我们会得到比较干净的素材。但是,文本中起到关键作用的是一些词,甚至主要词就能起到决定文本取向。英文分词有nltk提供的nltk.word_tokenize()中文分词,出现了很多分词的算法,有最大匹配法、最优匹配法、机械匹配法、逆向匹配法、双向匹配法等。中科院张华平博士研发的分词工具ICTCLAS,该算法经过众多科学家的认定是当今中文分词中最好的,并且支持用户自定义词典,加入词典;对新词,人名,地名等的发现也具有良好的效果。Jieba分词工具:支持繁体分词;支持自定义词典支持三种分词模式:1.精确模式,试图将句子最精确地切开,适合文本分析;2.全模式,把句子中所有的可以成词的词语都扫描出来,速度非常快,但是不能解决歧义;3.搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。阿里分词工具。2.4去除停顿词英文停顿词内嵌在nltk中中文停顿词比如句号,显然句号对意思的表达没有什么效果。还有是、“的”等词。因为这些词在所有的文章中都大量存在,并不能反应出文本的意思,可以处理掉。当然针对不同的应用还有很多其他词性也是可以去掉的,比如形容词等。2.5特征选择经过上面的步骤,我们基本能够得到有意义的一些词。然而并不是所有词都有意义,有些词会在这个文本集中大量出现,有些只是出现少数几次而已。他们往往也不能决定文章的内容。还有一个原因就是,如果对所有词语都保留,维度会特别高,矩阵将会变得特别稀疏,严重影响到挖掘结果。那么如何选择关键词比较合理呢?针对特征选择也有很多种不同的方式,但是TF-IDF往往起到的效果是最好的。tf-idf模型的主要思想是:如果词w在一篇文档d中出现的频率高,并且在其他文档中很少出现,则认为词w具有很好的区分能力,适合用来把文章d和其他文章区分开来。在一份给定的文件里,词频(termfrequency,TF)指的是某一个给定的词语在该文件中出现的次数。这个数字通常会被归一化,以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词频,而不管该词语重要与否)逆向文件频率(inversedocumentfrequency,IDF)是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。如果该词语不在语料库中,就会导致分母为零,因此一般情况下使用。Tf-idf计算公式为:某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于保留文档中较为特别的词语,过滤常用词。缺点:IDF的简单结构并不能有效地反映特征词的分布情况,使其无法很好的完成对权值的调整功能,所以在一定程度上该算法的精度并不是很高。除此之外,算法也没有体现位置信息,对于出现在文章不同位置的词语都是一视同仁的,因为在文章首尾的词语势必重要性要相对高点。2.6利用算法进行挖掘经过上面的步骤之后,我们就可以把文本集转化成一个矩阵。我们能够利用各种算法进行挖掘,比如说如果要对文本集进行分类,我们可以利用KNN算法,贝叶斯算法、决策树算法等等。2.7程序示例2.7.1新闻聚类2.7.2Bayes文本分类




 三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 扫描二维码
扫描二维码
![[大学 硕士 博士 研究]论文-电子书-研究 人员 的 圣经](/doc-63288.png)







 9798
9798
本文标题:自然语言处理流程
链接地址:https://www.777doc.com/doc-5146344 .html