您好,欢迎访问三七文档
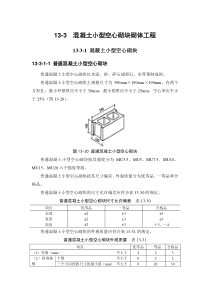
8计算机病毒传播模型•1生物病毒病毒传播模型•2当前计算机病毒传播模型•3网络环境下一个通用病毒的传播模型•4模型中的门限值和单结点的作用•5有限网络中病毒传播的离散模型•6计算机病毒的逻辑模型•7网络环境下病毒的求源8.1当前计算机病毒防治的主要手段及不足之处•解决病毒攻击的理想办法是对病毒进行预防,即阻止病毒的入侵,但由于受工作环境和具体技术的制约,预防的办法很难实现,也就是说,当前对计算机病毒的防治还仅仅是以检测、清除为主。8.1病毒防治的主要手段•(1)反病毒的软件采用单纯的特征值检测技术,将病毒从染病文件中消除。这种方式的可靠性很高,但随着病毒技术的发展,特别是加密和变形技术的运用,使得这种静态的扫描技术正在逐渐失去作用。•(2)反毒软件采用一般的启发式扫描技术、特征值检测技术和行为监测技术。这种方式可以更多地检测出变形病毒,也可以实现动态检测,但另一方面误报率也提高了,尤其是采用不严格的启发式知识判定技术,使得清除病毒存在很大的风险。•(3)在第二代清毒软件的基础上,采用虚拟机技术,将查找病毒和清除合二为一,以常驻内存的形式对病毒进行防、查、杀等必要手段。•(4)在第三代反毒技术之上,结合人工智能的研究成果,实现启发式动态,智能的查毒技术,它综合采用CRC检验,扫描机理,启发式智能代码分析模块,动态数据还原模块(能查出隐蔽性极好的压缩加密文件中的病毒),内存解毒模块以及自身免疫模块等技术。不足之处•抗病毒软件大都是针对某一类或某几类病毒,虽然我们也希望能够研制出较为通用的防毒软件,使之能清除更多种病毒,然而究竟能够清除哪些病毒,还要看实际输入的参数和样本,在未知的病毒特征没有弄清之前检测和清除都是不现实的。•当前的技术性防毒措施有很大的局限性,它是一种被动的防治技术。保证100%对抗所有病毒的清毒软件是不存在的。FredCohen博士也证明了病毒的不可判定性,因此,从理论上讲与病毒的斗争将是长期的.8.1主要的生物病毒传播模型•1975年一大批数学家研究了生物种群内生物病毒的传播规律。他们将一定区域内的人口分为两类,一类是已感染病毒的患者,一类是没有感染病毒的易感染者。I(t),S(t)分别表示t时刻感染者人数和易感染者人数。00)0(,)0()()()()()()()(SSIItStIdttdStItStIdttdI(1.1)8.1主要的生物病毒传播模型•上述模型并没有考虑由于生物体被感染而导致的死亡和获得“免疫”的部分,而死亡和“免疫”会结束该生物体所可能带来的感染。于是Kermack-Mckendrick又给出了另一模型,这也就是所谓的SIR模型:000)0(,)0(,)0()()()()()()()()()(RRSSIItIdttdRtItSdttdStItStIdttdI(1.2)这些模型为流行病的传播预测和防御提供了有利的工具。比如早在2005年初,传染病学家们就准确地预测到2005年底到2006年初的禽流感的爆发。8.2当前计算机病毒传播模型•大约在1990初,Kephart和White依据生物上流行病的传播模型(1.1)提出了计算机的病毒的传播模型,也就是SIS模型[56]。该模型给出了计算机病毒传播中的一些定性因素,较好地帮助人们理解计算机病毒传播中的一些规律,它也为后来其他的计算机病毒模型奠定了基础。在SIS模型中,所有的计算机只能处在两个不同的状态,易感者(Susceptible)和感染者(Infectious):))(())()(()()())()(()(tSNtSNtSdttdStItINtIdttdI(1.3)假设方程(1.3)的初始条件为:表示区域内计算机感染者最初的数量为I0。那么由分离变量法可以解出方程(1.3)具有如下形式的解:8.2当前计算机病毒传播模型tNeININItI)(000)()()((1.4)8.2当前计算机病毒传播模型•同样地JonghyunKim等人依据Kermack-MckendrickSIR模型给出了计算机病毒传播的SIR模型,在计算机病毒的SIR模型中,区域内的计算机也被划分为3个状态,易感染状态(Susceptible)、感染状态(Infectious)和被删除状态(Removed)。)()()()()()()()()(tIdttdRtItSdttdStItStIdttdI(1.5)8.2当前计算机病毒传播模型•RomualdoPastor-Satorras考虑到更一般的情况,哪些由于感染病毒而获得“免疫”的结点或者死亡的结点,又以某一生还比率变成了易感染者,换言之部分由于感染而失去的结点在时间t时,又加入到易感染者行列,这就是SIRS模型:)()()()()()()()()()()(tRtIdttdRtRtItSdttdStItStIdttdI(1.6)1.3计算机病毒传播模型中的问题•(1)传播速度模型的预测速度要比大多数的病毒传播速度慢得多。•(2)传播的规模与传播速度截然相反,大多数病毒的传播规模要比现有模型的预测规模小的多,这也是令大多数人感到困域的地方。•(3)门限值问题从前面的叙述中可以看出,与大多数的生物病毒传播模型一样,现有的一些网络病毒传播模型,也都给出了它们自己模型的门限值。然而实际的网络病毒传播数据表明,大多数的网络病毒并不具有这一传播特征,它们大都不具备唯一的极值,而是反复跳跃,呈现出反复感染、重复传播的情况。比如CIH病毒在每月的26日,就会重复发作。2004年4~5月间爆发的震荡波病毒,即使在初始爆发阶段,它的统计数据也呈现反复攀升的模式。因此人们不仅要问计算机病毒模型是否具备门限值呢?•(4)病毒的消亡问题大多数的生物病毒传播都有结束的时候,这与生物病毒传播模型是相吻合的。故计算机病毒的传播模型对任何病毒的传播预测也都应该有结束的时候。然而实际上大多数的计算机病毒,并没有像预测的那样消亡。•(5)传染的机制不再单一现有的计算机病毒传播模型大都是对传播类型单一的病毒建立的,它们的预测结果也大都是对局部的、某一类型的计算机系统的感染情况进行预测。而实际上越来越多的计算机病毒尤其是一些智能型病毒,它们的传播目标类型不再单一,而感染的对象也不再局限于某一地域或某一类网络。2计算机病毒与生物病毒•2.1计算机病毒与生物病毒的相似性•2.2计算机病毒与生物病毒在传播特征上的主要差异2.1计算机病毒与生物病毒的相似性•和生物病毒一样,计算机病毒是在正常的计算机程序中插入的破坏计算机正常功能或毁坏数据的一组计算机指令或程序的一段代码,计算机病毒的独特复制功能使得计算机病毒可以很快地蔓延,又常常难以根除。为了便于隐藏,它们的“个体”比一般的正常程序都要小。它们能把自已附在特定文件上,当文件被复制或从一个用户传送到另一用户时,计算机病毒也就随着这些文件蔓延开来。•计算机病毒和生物病毒都具有循环复制的功能,这也是它们的最大相似之处,因为循环复制是传染性的基础。•在编码方式上,计算机病毒早期采用机器语言编写,而后来,尤其是近年来的病毒大都采用高级语言编写。这些病毒程序通过一定的感染途径,进入宿主计算机后,大多以物理(磁)储存的方式,潜伏于计算机的存储介质中;类似地生物病毒,大都采用核酸编码,也有采用甲氨基酸编码,其高级的细胞语言也是编制生物病毒的一种选择。所谓细胞语言是指比较低级的核酸编码,它借助细胞外进行信息交流。当然无论是低级语言的核酸还是高级语言的氨基酸,这些序列都可以固化的形式存在,也可以物理存储的方式存在于细胞的物理存储单元核小体中。它们的破坏机制也都是循环执行。2.2计算机病毒与生物病毒在传播特征上的主要差异•2.2.1传播中的感染者接触方式差异•2.2.2感染者的个体差异•2.2.3感染者的结局差异•2.2.4治愈率差异3网络环境下一个通用病毒的传播模型•3.1模型的提出•3.2传播模型的建立•3.3传播模型的解•3.4问题3.1模型的提出•计算机病毒有不同于生物病毒的根本之处,具体表现在以下4个方面:•(1)生物病毒的传播是通过一个地域内的传播主体的物理接触,其传播速度取决于人口的流动状况,这种人口流动状况是相对稳定的;而网络病毒的传播则是通过计算机系统间的连接,这种连接是一种逻辑上的连接而不是物理的接触(当然这种连接需要物理上的连通),它几乎不受地域的限制,并且这种逻辑上的连接是动态的、它是随时间而变化的,甚至还有一定的周期。•(2)作为生物病毒传播载体的生物宿主,在同一种群内的生物体之间的区别是很小的,也就是它们在病毒的传播上几乎不加区别,而仅以感染者的数量作为分析的对象;但作为计算机病毒传播载体的计算机系统,它们间的区别是很大的。如一台PC机和一个热门的大型网站,它们对病毒的传播几乎天壤之别。如果一个大型网站被感染,它对于病毒的传播几乎是爆炸式的。•(3)生物病毒会导致传播主体的死亡,从而结束该个体的传播功能,这也是减少染病者数目的原因之一;但计算机病毒几乎不会导致计算机系统的真正减少。•(4)生物病毒的感染者一旦被治愈,一般来讲对该病毒都会具有免疫力;但计算机系统被治愈后,严格意义上的免疫还不具备,也就是说被治愈者仍可能被重复感染,然后它还会感染别的计算机。3.1模型的提出•正是这种不同之处才导致了计算机病毒具有不同于生物病毒的传播特征,从而应具有不同于生物病毒的传播模型。正如上面的分析,影响病毒传播的关键因素是计算机系统间的这种逻辑的、动态的、有方向的连接,如果把计算机系统间的这种连接率作为它们影响病毒传播的一个基本特征,那么将会更有效地反映计算机病毒的传播规律。这不仅能刻画出病毒的传播速度受整个网络连接率变化的影响,而且还能刻画出不同的计算机系统由于其连接率的不同,它们对病毒的传播也应有很大的不同。当然计算机系统的这种连接率是可以量化的,比如计算机系统上网时的点击率和数据流量等,就是最直接有效的反映。当然无论是点击率还是计算机在上网时的数据流量都必须与具体的病毒相关。3.2传播模型的建立3.2传播模型的建立()()()(1)1()()()dItItctNIttItdtN2()(()())()()()dItNcttItctItdt(3.2)(3.1)当N比较大时,N≈N-1,所以上式可化为:3.2传播模型的建立•这就是我们以普通的网络环境为基础建立的病毒的传播模型,称它为GSM(GeneralSpreadingModel)模型。从上面的建立过程来看,病毒的传播需要借助计算机间的连接,而计算机间的连接又需要某主动方来发起连接。这意味着该微分方程所刻画的病毒并不包含那些主动寻址传播的蠕虫,除此之外的邮件类病毒、QQ类病毒、FTP病毒还有大量的仅借助文档传播的宏病毒和早期病毒等等,这些被动传播病毒都可以用GSM模型来刻画。3.3传播模型的解3.3传播模型的解•这是一个一阶线性非齐次的常微分方程,所以可知其解:]dse)s(cI1[e)t(yt0dx)x(c20ds)s(cs01t01由(3.3)可得到(3.1)在初值(3.2)下的解为:t0dx)x()x(cN0ds)s()s(cNdse)s(cI1e)t(Is0t0(3.4)3.3传播模型的解t0dx)x()x(cN212012ds)s()s(cN21dse))s(C)CNC)(s(c(ICCeCC)t(Is0t0考虑到后面将要讨论的几种实际情况,我们可以将解依如下形式来进一步讨论:(3.5)3.3.1第一种情况3.3.1第一种情况图3.1计算机病毒Gaobot.gen和Briss.A的传播数据统计图3.3.2第二种情况•取c(t)=c,010100()tttttttt单增函数得解为如下形式:
 三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 扫描二维码
扫描二维码








 bresy
bresy
本文标题:计算机病毒传播模型
链接地址:https://www.777doc.com/doc-6040422 .html