您好,欢迎访问三七文档
机器学习MachineLearning•课程考核方法–平时分(20分)–点名(10分)一次不来扣3分–上机作业(30分)–期末考核(40分)•主要参考书目–《机器学习》TomM.Mitchell著曾华军张银奎等译–《机器学习导论》EthemAlpaydin著范明等译•学时安排及上机–总学时54(授课36+上机18)–上机时间地点:信息楼105•辅导答疑–周五3-4节扬帆楼503本课程主要内容•监督学习–分类–回归•隐马尔可夫模型•贝叶斯网络•决策树•人工神经网络•贝叶斯学习•增强学习如何学习本门课程•本门课程注重了解和理解,为将来进一步的深入学习打好基础。•本门课程的要求–掌握基本概念–了解机器学习方法的思想–掌握少数经典算法,并能够编程实现•多动脑思考,积极活跃的课堂讨论。第一章绪论•什么是机器学习?•机器学习的应用实例•相关资源四个概念•人工智能(ArtificialIntelligence)•智能计算(IntelligentComputing)•计算智能(ComputationalIntelligence)•机器学习(MachineLearning)智·能所以知之在人者,谓之知。知有所合,谓之智。所以能之在人者,谓之能。能有所合,谓之能。——荀况《荀子·正名》智能学智能学:即研究生物智能、人类智能以及人造智能的科学。21世纪的科学技术,已经向我们展示了一个丰富多彩的智能世界:人类智能、生物智能、智能机器人、生物信息系统;人工智能、计算智能、机器学习、智能仪器、智能机器人、机器翻译、人机对弈、人工生命、人工免疫系统、人造昆虫、机器人足球赛…。计算一切思维不过就是计算。——霍布斯作为一般的智能行为,物质符号系统具有的计算手段,既是必要的也是充分的。人类认知和智能活动,经编码成符号系列,都可以通过计算机进行模拟。——西蒙梦想•机器具有智能—计算机科学家的梦想什么是智能?能感知、能学习、能思维、能记忆、能决策、能行动……,智能的核心是思维。图灵测试•怎样判断机器具有智能—图灵测试1950年AlanTuring的文章“ComputingMachineryandIntelligence.”(Mind,Vol.59,No.236)提出图灵测试,检验一台机器或电脑是否具有如人一样的思维能力和智能电脑和人分别封闭在不同的房间,测试者不知道哪个房间是人,哪个房间是电脑,他向双方提出测试问题,电脑和人给出各自的答案,如果一系列的测试问题之后,测试者分不出哪些是电脑的答案,哪些是人的答案,则电脑通过测试,确实具有与人一样的智能。我是人哦!我是谁?如实回答?测试悖论•公平性问题图灵测试的出发点显然是刁难电脑,要求电脑模仿人回答问题,公平吗?反过来要求人模仿电脑回答问题,公平吗?•标准性问题在怎样的智能水平下对电脑进行测试?天才、普通人还是婴幼儿,或者说怎样认定电脑的智力水平?•全面性问题怎样全面地测试电脑的智能,喜、怒、哀、乐和表情等有关情感的测试如何进行?测试边界怎样确定?•欺骗性问题电脑如果有意欺骗测试者,测试者能判断出来吗?在一定的范围内进行测试还是可行的困惑•哲学问题(1)规则与规律:规则是制定的,规律是客观存在的,从规则能自动发现规律吗?(2)生命与非生命:智能是高等生命体独有的能力,非生命体内能产生智能吗?(3)物质与意识:唯物主义和唯心主义都承认二元论,只是在何者起决定作用上争论不休,智能能在机器内产生将导致一元论—物质生成一切?(4)智能的本质:理性与感性、思考与行动、社会性与个体性•伦理问题(1)电脑与人脑:能否互换?(2)机器人与人:机器能否融入人类社会?(3)情感与役使:机器是人制造并使用的工具,一旦机器人具有了智能和情感,人类还能当奴隶一样地役使吗?(4)机器人叛乱:机器人群体有可能叛乱而反过来役使人类吗?现实•比尔·盖茨预测:智能计算发展前景乃是机器最终“能看会想,能听会讲”。•无论是人工智能,还是智能人工,只要能够殊途同归,造福于人类,那么所有的努力便都是有价值的。•未来,智能机器作为真正意义上的工作助手和生活良伴,将使我们的生活完全改观。•“聪明机器”的出现,也决不会成为人类的灾难,在智慧与创造力方面,永远是人类最有发言权。什么是智能计算•智能计算(ComputationalIntelligence,CI)目前还没有一个统一的的定义,使用较多的是美国科学家贝慈德克(J.C.Bezdek)从智能计算系统角度所给出的定义:•如果一个系统仅处理低层的数值数据,含有模式识别部件,没有使用人工智能意义上的知识,且具有计算适应性、计算容错力、接近人的计算速度和近似于人的误差率这4个特性,则它是智能计算的。•从学科范畴看,智能计算是在神经网络(NeuralNetworks,NN)、演化计算(EvolutionaryComputation,EC)及模糊系统(FuzzySystem,FS)这3个领域发展相对成熟的基础上形成的一个统一的学科概念。智能计算的产生与发展•1992年,贝慈德克在《ApproximateReasoning》学报上首次提出了“智能计算”的概念。•1994年6月底到7月初,IEEE在美国佛罗里达州的奥兰多市召开了首届国际智能计算大会(简称WCCI’94)。会议第一次将神经网络、演化计算和模糊系统这三个领域合并在一起,形成了“智能计算”这个统一的学科范畴。•在此之后,WCCI大会就成了IEEE的一个系列性学术会议,每4年举办一次。1998年5月,在美国阿拉斯加州的安克雷奇市又召开了第2届智能计算国际会议WCCI’98。2002年5月,在美国州夏威夷州首府火奴鲁鲁市又召开了第3届智能计算国际会议WCCI’02。此外,IEEE还出版了一些与智能计算有关的刊物。•目前,智能计算的发展得到了国内外众多的学术组织和研究机构的高度重视,并已成为智能科学技术一个重要的研究领域。什么是机器学习?•计算机技术的发展–海量数据(存储和处理的能力)–计算机网络(远程访问数据的能力)•例如:–连锁超市遍布全国各地,商品上千种,顾客数百万。–销售终端记录每笔交易的详细资料,包括日期,购买商品和数量、销售价格和总额,顾客标识码等。什么是机器学习?–我们不能确切的知道哪些人比较倾向于购买哪些特定的商品,也不知道应该向喜欢看电影的人推荐哪些电影。•我们已经掌握的,就是历史的数据(经验)。•我们期望从数据中提取出这些问题或相似问题的答案。什么是机器学习?•已经观测到的数据产生是随机的么?其中是否隐含一些规律?–当你去超市买面包的时候,你是不是同时也会买点牛奶?–夏天的时候你是不是经常买雪糕?冬天则很少?•数据中存在一些确定的模式或规律!什么是机器学习?•机器学习?–从历史数据中,发现某些模式或规律(描述)–利用发现的模式和规律进行预测•机器学习的定义–基于历史经验的,描述和预测的理论、方法和算法。•机器学习可行性的保证–将来,至少是不远的将来,情况不会与收集的样本数据时有很大的不同,因此未来的预测也将有望是正确的。机器学习能做什么?•机器学习方法在大型数据库中的应用被称为数据挖掘(DataMining)。–大量的金属氧化物以及原料从矿山开采出来,处理后产生少量的珍贵物质。数据挖掘中,需要处理大量的数据以构建简单有用的模型,例如高精度的预测模型。•应用举例–零售业,银行,金融业,构建信用分析、诈骗检测、股票市场;–制造业,优化、控制、故障检测;–医学领域,医疗诊断;–电信行业,通话模式的分析可用于网络优化和提高服务质量。–万维网上检索信息。机器学习能做什么?•机器学习也是人工智能的组成部分。•授予鱼不如授予渔–为了智能化,处于变化环境中的系统不需具备学习能力。如果系统能够学习并且适应这些变化,那么系统设计者就不必预见所有情况,并为它们提供解决方案了。机器学习能做什么?•机器学习还可以解决视觉、语音识别以及机器人方面的许多问题。•模式识别–图像和音频的获得很容易,机器如何做到识别?让机器人识别人脸?辨别声音?–一个图像并非是像素点的随机组合,人脸是有结构、对称的。人脸上的器官是有组合模式的。–通过分析一个人的脸部图像的多个样本,学习程序是可以捕获到那个人特有的模式。然后进行辨认。深入理解机器学习•机器学习使用实例数据或过去的经验来训练计算机,以优化某种性能指标。–例如,依赖于某种参数的模型,学习过程就是执行计算机程序,利用训练数据或以往的经验来优化该模型的参数。•学习模型可以是预测的,用于预测未来。或者是描述的,用于从数据中获取知识。也可以二者兼备。•机器学习在构建数学模型是利用统计学理论,其核心任务是从样本中推理。–训练过程中,面对海量数据,需要高效的算法。–表示和推理的算法也必须是高效的。–因此,时间复杂度,空间复杂度和预测精确度三者缺一不可。机器学习应用举例•学习关联性•分类•回归•非监督学习•增强学习学习关联性•在零售业,例如超市连锁店,机器学习的一个应用就是购物篮分析。它的任务是发现顾客所购商品之间的关联性:如果顾客购买商品X时通常也购买商品Y,而一名顾客购买商品X却没有购买商品Y,则他是商品Y的潜在顾客,一旦发现这类顾客,可以实行打包销售策略。•关联规则1:条件概率P(Y|X)–例如从以往数据中统计出P(牛奶|面包)=0.8•关联规则2:估计P(Y|X,D)其中D是顾客的一组属性,如性别、年龄、婚姻状况等,例如网上书店,将分析的结果概率比较大的书Y,推荐给符合某属性的用户。分类•信贷是金融机构(例如银行)借出的一笔钱,需要连本带息分期偿还。对于银行来说,重要的是能够提前预测贷款风险。风险指的是客户不履行义务和不全额还款的可能性。既要保证银行获利,又要确保不会因提供超出客户财力的贷款而给客户带来不便和银行的损失。在信用评分中,银行要计算在给定信贷额度和客户信息情况下的风险。客户信息包括可以获取的数据,以及客户财力相关的数据,即收入、存款、担保、职业、年龄、以往经济记录等。通过这些申请数据,我们可以推断出一般规则,表示客户属性及风险的相关性。从而将客户分为低风险客户和高风险客户。新的客户申请数据作为分类器的输入,分类器将该客户输入指派到某一个类中。•得到的规则:ifincomexandsavingsythenlow-riskelsehigh-risk分类思考1•在某些情况下,我们可能不希望1/0(高风险/低风险)类型的判断,而是希望计算一个风险概率值。该如何用概率模型表达??•概率值P(Y|X),X是顾客属性,Y是0或1,表示低风险和高风险。–例如给定客户属性x,P(Y=1|X=x)=0.8,表示客户高风险的可能性是80%。分类--模式识别(PatternRecogniition)•光学字符识别(Opticalcharacterrecognition)–图像字符–文本识别It’srainyoutside.•人脸识别(facerecognition)•语音识别(speechrecognition)•医学诊断(medicaldiagnosis)回归(Regression)•假如我们想要一个能够预测二手车价格的系统,输入为会影响车价格的属性:品牌,车龄,发动机性能,里程以及其他信息,输出为车的价格。•设x表示车的属性,y表示车的价格。机器学习采用函数拟合来学习x的函数y。(1)y=w1x*w0线性回归(2)y=w2x2+w1x*w0非线性回归回归(Regression)•思考2:•多属性如何回归?思考3•回归和分类的共同点是什么?监督学习(supervisedlearning)•回归和分类均为监督学习问题•即,输入x和输入y都是给定的,任务是学习从输出到输入的映射:y=g(x|θ)其中θ是模型参数。•回归y取值是连续的(数值),而分类是离散的。非监督学习•监督学习中,输出的正确值是由指导者提供的。而非监督学习中,却没有这样的指导者,只有输入数据。•非监督学习的目标是发现输入数据中的规律。•输入空间存在着某种结构,似的特定的模式比其他模式更常出现,我们希望知道的是哪些经常发生,那些不经常发生。在统计学中,这被称为密度估计(dens
 三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 扫描二维码
扫描二维码


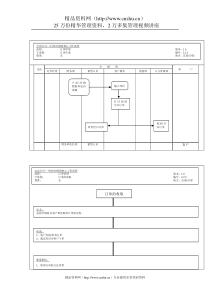
![管理咨询入门-1[1]](/doc-710993.png)


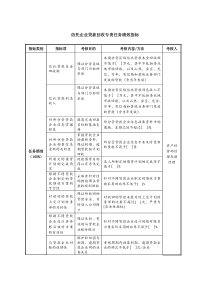



 laidiany
laidiany
本文标题:机器学习导论第1章
链接地址:https://www.777doc.com/doc-7078544 .html