您好,欢迎访问三七文档
当前位置:首页 > 商业/管理/HR > 公司方案 > 周淳:DM针对大数据量环境下分析型应用的支持方案v2063
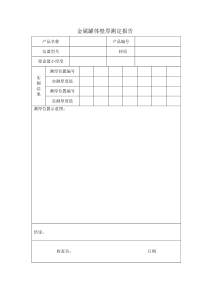
DTCC2011DM针对大数据量环境下分析型应用的支持方案大纲·一个实际案例·挑战和解决方案·下一步工作规划DTCC2011DTCC2011一个实际案例案例简介DTCC2011·海量数据·基于已有硬件投资–单服务器节点–操作库和分析库合并·以查询分析为主,兼顾少量数据维护文本数据源数据硬件与拓扑千兆交换机DTCC2011应用服务器数据汇总文本数据源文本Excel数据数据清洗与入库数据库服务器P550Cpux4Mem32GBP550Cpux4Mem32GB源源16X1TBSASRAID5案例简介-数据DTCC2011·以常规数据为主,主要为数值、字符串、时间类型·日增长数据量为约56G,3亿条元组·当前数据量3TB·最大单表为计费表,目前约150亿条记录·数据保存20年后归档为历史数据·在线数据规模将超过400TB典型业务流程DTCC2011–源数据清洗入库–分析统计型查询·第一步过滤的筛选条件不确定·试错式的查询分析过程,成功后固化,一般包含20多个步骤·大规模的连接查询、子查询、联合查询、数据分组与排序、临时结果集与临时表等·复杂SQL不多,但IO非常大–日常数据维护·手工修改记录内容·批量删除·定期维护案例需求DTCC2011·关键在查询性能–第一个过滤步骤·筛选字段由用户随机定义,因此无法使用索引·一般会得到千万级别的结果集–大量的多表连接查询·数据装载性能·初始入库48亿条,近1T:限48小时,相当于3万条/s·后续每3天入库一次,9亿条,168G,限10小时内完成DTCC2011挑战-核心是性能原有产品难以支持分析型应用DTCC2011·······只支持行式存储查询优化器比较简陋虚拟机实现不尽合理物理存储设计有待优化日志系统过于复杂不能充分利用多机资源提升性能数据分片技术不完善于2009年开始新一代产品DM7的研制DM系统研制历程DTCC2011实验室原型技术积累阶段实现各类标准持续的技术积累5.6引入物理操作符,虚拟机6.0引入高级特性和oracle兼容特性5DM72011稳定性及功能与开源系统有差距3DM5.64DM62009对DM4-DM6的技术总结融合列存储与行存储基于向量数据的1DM1-DM32DM420042007执行内核原生的MVCCOLAP应用的支持1988-2003对于性能的理解DTCC2011应用系统的设计表达式计算优化器综合性能数据/控制权传递I/O效率并发/并行数据控制权传递-批量技术DTCC2011–向量数据处理–在数据泵一次传送一批数据–减少控制转移的CPU损耗;–有利于批量的表达式计算DTCC2011传统的数据传递PROJECTFILTER一次只传递一条记录每个操作符一次只处理一行记录111…控制权需要反复传递SCAN12…N12…N…………DTCC2011向量式的数据传递PROJECT减少控制权限的反复传递提升CPU的有效利用率FILTER便于表达式批量计算SCAN批量技术-数据入库DTCC2011–将系统的初始数据入库–原有BCP接口达到5000条/s,仍无法满足要求–改进:·在服务器端实现批量,减少执行流程中的控制跳转·效率提升8倍批量技术-全表更新DTCC2011普通批量普通批量绑定针对大表更新的特定的批量绑定消息计划生成生成特定计划,减少执行流程单趟扫描一个ID进行更新,执行20万次ID进行排序,单趟扫描20万个ID并进行更新性能提升100倍以上,控制在2秒以内批量技术-LIKE谓词·selectcount(*)fromorderswhereo_commentnotlike'%special%requests%‘DTCC2011DBMS‘O’11g:3.3DBMS‘S’2005:10DM7:0.4orders:1,500,000记录cpu2.2G,多次执行表达式计算-表达式结果重用DTCC2011·一个表达式出现多次–Selectsum(2*c1),sum(3*(2*c1))fromt·只计算一次,结果缓存–v1=2*c1;–Selectsum(v1),sum(3*v1)fromt·类似思路:中间结果重用–一个复杂查询在一条sql语句中使用多次的情况–将复杂查询提取,并将结果缓存,多次使用·虚拟机支持批量计算指令DTCC2011批量表达式计算for(i=0;in;i++){r=(int64)opr1[i]+opr2;if(r!=(int)r)returnEC_DATA_OVERFLOW;}res[i]=(int)r;···一次计算一批数据利用CPU的CACHE利用CPU的SIMD特性·避免传统DBMS的函数反复调用代价··接近于C的效率比一次一行模式快10-100倍以上DTCC2011批量尺寸对性能的影响·SF=1,TPCHQ1·BDTA_SIZE:可配置的批量大小参数·增大BDTA_SIZE可以有效的提高执行效率TPCHDM7DBMS‘O’11PGSQL8.3DBMS‘S’2005Q121.579.154.622.08Q131.734.475.1312.03Q140.718.972.801.16Q150.668.985.511.04Q160.870.334.525.41Q171.038.941001.80Q181.279.2122.012.90Q191.929.065.624.17Q200.789.231000.79Q212.248.8833.015.49Q220.240.341001.16TPCHDM7DBMS‘O’11PGSQL8.3DBMS‘S’2005Q11.3149.0916.0112.87Q20.160.0460.190.14Q30.8621.619.302.78Q40.989.030.800.68Q51.49.054.611.58Q60.7892.720.96Q71.6111.7319.542.35Q82.30.282.972.01Q931.6118.015.45Q101.369.165.832.23Q110.1944.670.550.46TPC-H/SF=1对比测试(S)DTCC2011优化器-分析器流程DTCC2011SQL脚本语法分析语法树语义分析SFW结构关系代数变换关系树代价优化优化了的关系树物理计划生成执行计划智能优化器·基于多趟分析的代价优化器·语义分析、代价优化过程分离·灵活的计划变换控制·基于时间单位(ms)的代价计算·解决统计信息的使用性问题·增加频率直方图·增加高度直方图的桶数DTCC2011查询优化:关系变换DTCC2011·SFW结构转换为关系树Select:ID,nameFrom:TSFW结构–投影(PROJECT)–连接(JOIN)–半连接(SEMIJOIN)–选择(SELECT)–基本表(BASETABLE)Where:ID=10PROJECT(ID,name)SELECT(ID=10)BASE_TABLE(T)关系树查询优化:关系变换的关键DTCC2011·消除子查询,“平坦”的关系树·子查询一律转化为半连接(SEMIJOIN)例:selectfromT1wheret1.idin(selectIDfromT2)PROJECTSEMIJOINT1T2查询优化:待选关系树的生成DTCC2011·考虑三个因素·A.确定的连接次序·B.确定的卡特兰2叉树形状·C.是否下放过滤条件·采用临时结果减少重复计算·代价模型基本覆盖所有情况·对连接表的个数非常多的情况,特殊处理查询优化:统计信息DTCC2011·记录数据分布情况,用于精确行数估计,特别是数据分布不规则的情况,对基数及代价计算有重大影响·频率直方图:不同值较少500450400350300250400200238432300200150100500124167w_id=0w_id=1w_id=2w_id=3w_id=4w_id=5w_id=6·等高直方图:不同值较多4050400040023990403239803950390038503800395039603888I/O效率-融合列存储和行存储DTCC2011·列存储:–数据按列存储–结合自适应压缩技术–与批量计算技术紧密结合·列存储优缺点–大幅提升扫描性能–适合批量装载与删除–不适合频繁的插入、删除和更新·融合列存储和行存储–提供按列存储选项–结合分区技术–同时适应OLAP和OLTP应用需求I/O效率·行存储优化–简化物理记录格式–字段物理次序与逻辑次序分离·多buffer类型–常驻内存和常规方式淘汰–用户可以指定·批量读:预处理·支持垂直分区和水平分区DTCC2011提高并发度·支持并行插入的物理数据存储·并行备份和恢复·分区技术及相应的并行查询操作符号DTCC2011典型场景一:大结果集DTCC2011·场景描述–某表T,31个字段,48亿条记录–随机基于某字段筛选:SELECT*FROMTWHEREFLD1=753–查询符合条件的结果集达到千万条记录·分析––––SQL语句非常简单,没有更优的等效语句结果集筛选条件不确定,无法使用索引服务器内存为32G,在扫描的过程中必然出现页面淘汰由于基础数据量大,因此即使命中率不高(0.2%),也会生成960万条记录的结果集典型场景一:大结果集DTCC2011从3个方向入手,提升全表扫描的IO效率·批量技术·降低结果集处理的时间消耗·调整数据页读取策略典型场景一:大结果集DTCC2011·返回结果集策略改进–优化前·根据通信块大小决定结果集分批次返回的数量·第一批结果集返回后,自动完成后续结果集获取和返回–优化后·由应用设定第一批结果集的大小和返回的时机·当返回第一批结果集后,工作线程暂停SQL查询请求,直到下一批结果集请求到来或开始新事务–效果·快速返回部分结果集,提高用户体验·避免自动返回所有结果集,降低服务器资源消耗典型场景一:大结果集DTCC2011·调整数据读取策略–数据页(page)是数据读写的单位–优化前的全表扫描:按页读取,每次IO只扫描一个页–优化后:一次扫描多个页,减少IO数量–测试:经过优化后,磁盘的吞吐量提升1倍典型场景二:大表连接DTCC2011·场景描述–表T1,31个字段,5000W条记录,数据类型包括int、varchar、datetime、Dec;表T2,15个字段,500W条记录,数据类型包括varchar、datetime、Dec;–SELECTT1.NAME,T2.TITLEFROMPERSON.PERSONT1,RESOURCES.EMPLOYEET2WHERET1.PERSONID=T2.PERSONIDANDT1.SEX='M';–连接查询字段由最终用户临时指定,表上未建索引–结果集不大,但查询表数据量大,连接查询响应时间陡增C1C2…CnC1…Cm…………典型场景二:大表连接DTCC2011·分析·行存储特性:连接查询所连接的字段在数据页中的存储非连续,进行连接查询,需将所有数据页读到内存,IO消耗巨大;·连接匹配时,要对读入缓存中的所有页进行扫描。·行存储:–连接列分散在每个数据页中Cn+1页1…Cn+1页NC1C2…CnC1…Cm…………C1C1…C1C2C2…C3………………Cm…………典型场景二:大表连接DTCC2011·优化方向:列存储–按字段存储–连接列被集中存储Cn+1Cn+1…页1Cn+1页N–读入缓存中的数据页明显减少,系统IO下降典型场景二:大表连接·优化方向:存储压缩–适用于列存储模式的压缩算法–初步压缩结果:DTCC2011····采用本案例数据进行测试Float54%(压缩后大小/压缩前大小)Double33%Dec52%·字符56%典型场景二:大表连接·优化效果从17小时降至10分钟以内DTCC2011典型场景三:全表查询建表DTCC2011·场景描述–表T,15个字段,500W条记录,数据类型包括int、varchar、datetime、Dec;–根据T进行查询建表:CREATETABLETTasSELECT*FROMT;典型场景三:全表查询建表DTCC2011·分析–大表进行查
 三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
三七文档所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 扫描二维码
扫描二维码









 丹阳核蛋危机
丹阳核蛋危机
本文标题:周淳:DM针对大数据量环境下分析型应用的支持方案v2063
链接地址:https://www.777doc.com/doc-912878 .html